040 DataFrame中的write与read编程
一:SparkSQL支持的外部数据源
1.支持情况

2.External LIbraries
不是内嵌的,看起来不支持。
但是现在已经有很多开源插件,可以进行支持。
3.参考材料
· 支持的格式:https://github.com/databricks
二:准备
1.启动服务
RunJar是metastore服务,在hive那边开启。
只需要启动三个服务就可以了,以后runjar都要启动,因为这里使用hive与spark集成了,不启动这个服务,就会总是报错。

2.启动spark-shell

三:测试检验程序
1.DataFrame的构成

2.结果

3.测试

4.结果

四:DataFrame的创建
1.创建SQLContext
val sqlContext=new SQLContext(sc)
2.创建DataFrame(两种方式)
val df=sqlContext.#
val df=sqlContext.read.#
3.DataFrame数据转换
val ndf=df.#.#
4.结果保存
ndf.#
ndf.write.#
五:DataFrame的保存
1.第一种方式
将DataFrame转换为RDD,RDD数据保存
2.第二种方式
直接通过DataFrame的write属性将数据写出。
但是有限制,必须有定义类实现,默认情况:SparkSQL只支持parquet,json,jdbc
六:两个常用的网站(数据源问题)
1.金砖公司提供的一些插件

2.package网址
https://spark-packages.org/

七:DataFrameReader编程模式
功能: 通过SQLContext提供的reader读取器读取外部数据源的数据,并形成DataFrame
1.源码的主要方法
format:给定数据源数据格式类型,eg: json、parquet
schema:给定读入数据的数据schema,可以不给定,不给定的情况下,进行数据类型推断
option:添加参数,这些参数在数据解析的时候可能会用到
load:
有参数的指从参数给定的path路径中加载数据,比如:JSON、Parquet...
无参数的指直接加载数据(根据option相关的参数)
jdbc:读取关系型数据库的数据
json:读取json格式数据
parquet:读取parquet格式数据
orc: 读取orc格式数据
table:直接读取关联的Hive数据库中的对应表数据
八:Reader的程序测试
1.新建文件夹

2.上传数据

3.加载json数据
val df=sqlContext.read.format("json").load("spark/sql/people.json")
结果:

4.数据展示
df.show()
结果:

5.数据注册成临时表并操作展示

结果:

6.和上面的方法等效的方式
sqlContext.sql("select * from json.`spark/sql/people.json`").show()
结果:

7.读取显示parquet格式的数据
sqlContext.read.format("parquet").load("spark/sql/users.parquet").show()
结果:

8.加载mysql中的数据
这个是服务器上的mysql。
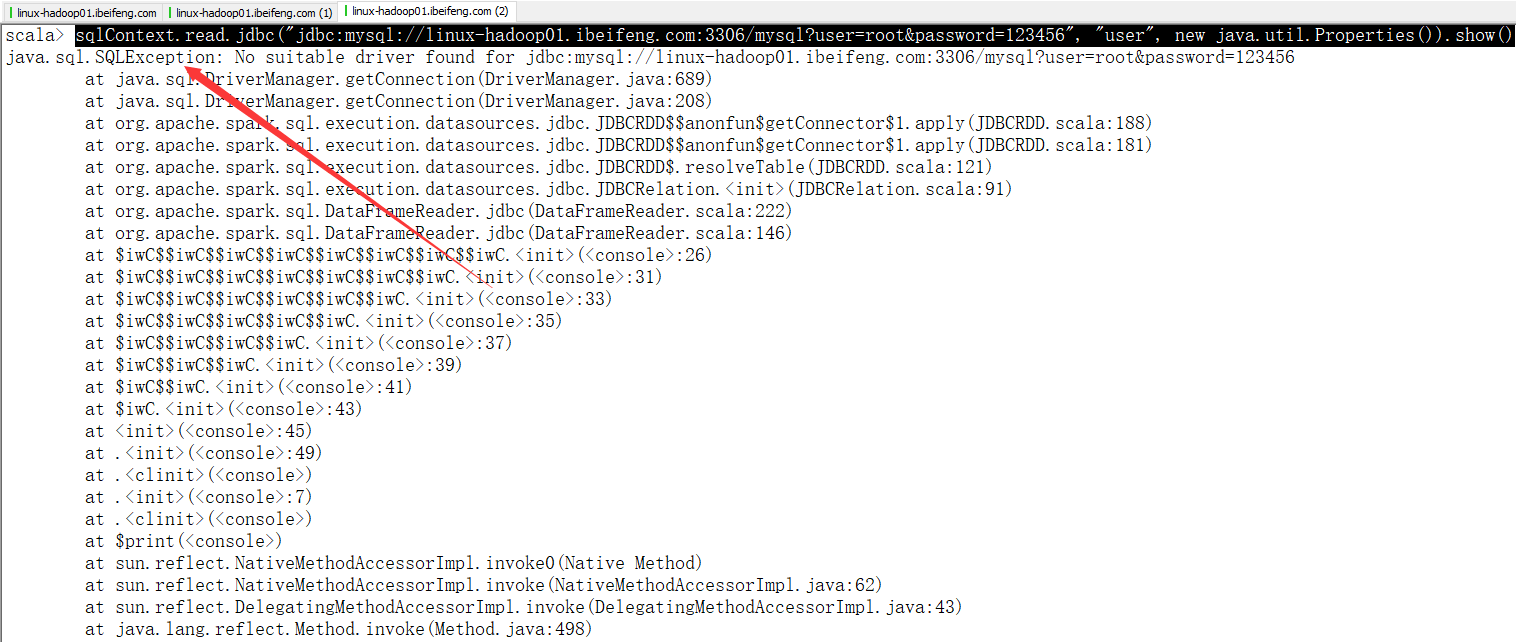
sqlContext.read.jdbc("jdbc:mysql://linux-hadoop01.ibeifeng.com:3306/mysql?user=root&password=123456", "user", new java.util.Properties()).show()
这个地方比较特殊。
第一次使用bin/spark-shell进入后,使用命令,效果如下:
然后使用这种方式进行启动,加上jar
bin/spark-shell --jars /opt/softwares/mysql-connector-java-5.1.27-bin.jar --driver-class-path /opt/softwares/mysql-connector-java-5.1.27-bin.jar
九:DataFrameWriter编程模式
功能:将DataFrame的数据写出到外部数据源
1.源码主要方法
mode: 给定数据输出的模式
`overwrite`: overwrite the existing data.
`append`: append the data.
`ignore`: ignore the operation (i.e. no-op).
`error`: default option, throw an exception at runtime.
format:给定输出文件所属类型, eg: parquet、json
option: 给定参数
partitionBy:给定分区字段(要求输出的文件类型支持数据分区)
save: 触发数据保存操作 --> 当该API被调用后,数据已经写出到具体的数据保存位置了
jdbc:将数据输出到关系型数据库
当mode为append的时候,数据追加方式是:
先将表中的所有索引删除
再追加数据
没法实现,数据不存在就添加,存在就更新的需求
十:writer的程序测试
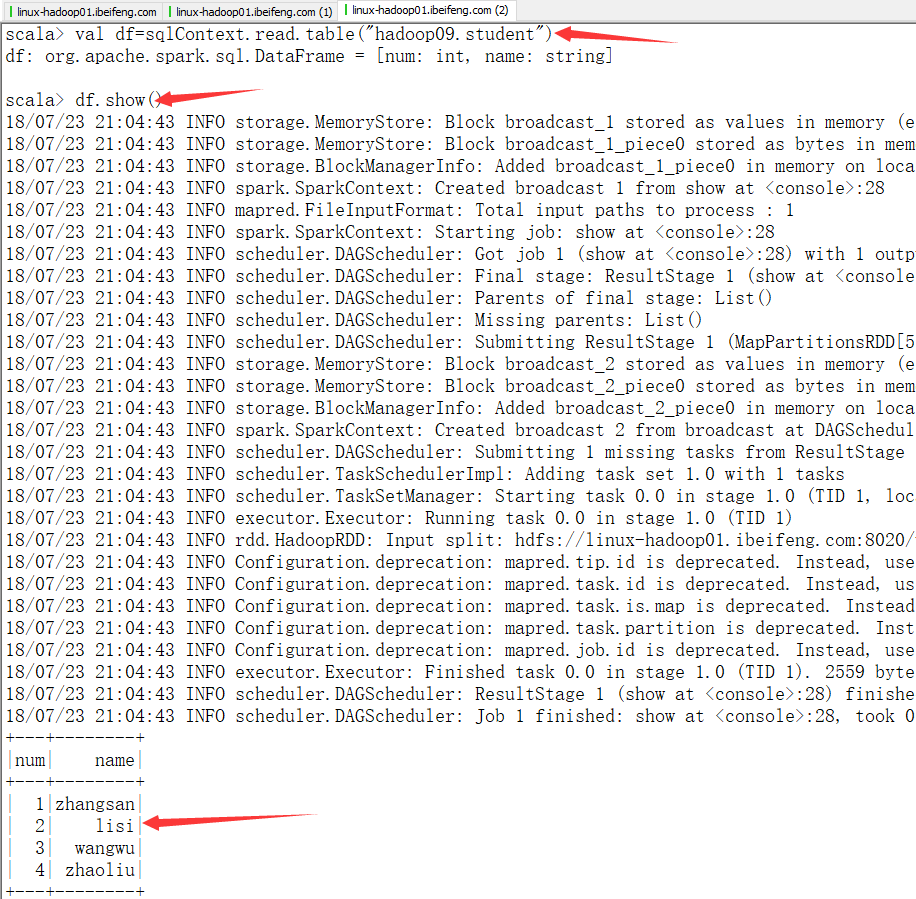
1.读取hive数据,形成DateFrame
2.结果保存为json格式
自动创建存储目录。
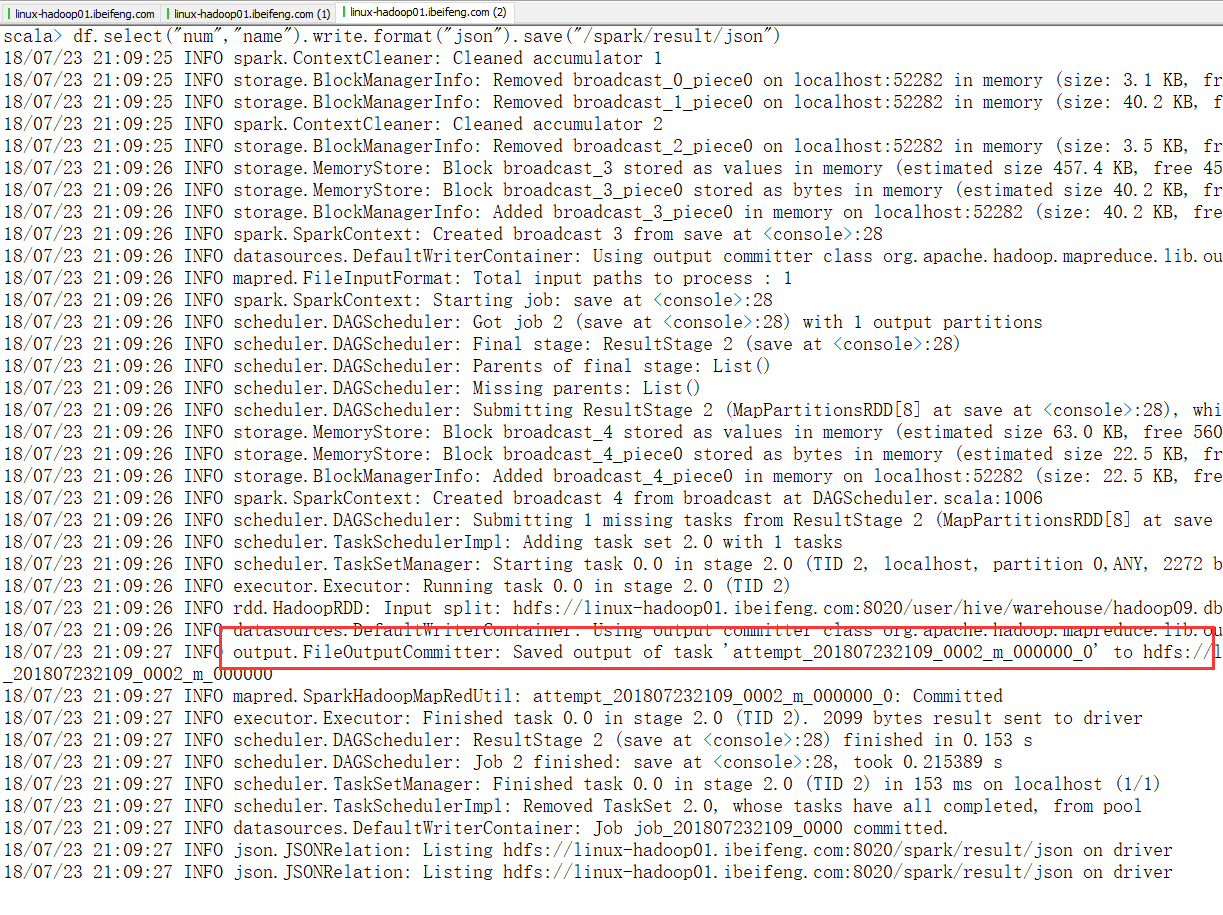
效果:
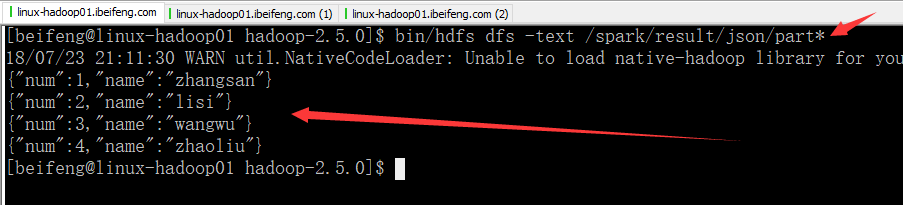
3.不再详细粘贴结果了
读取Hive表数据形成DataFrame
val df = sqlContext.read.table("common.emp") 结果保存json格式
df.select("empno","ename").write.mode("ignore").format("json").save("/beifeng/result/json")
df.select("empno","ename").write.mode("error").format("json").save("/beifeng/result/json")
df.select("empno","ename", "sal").write.mode("overwrite").format("json").save("/beifeng/result/json")
df.select("empno","ename").write.mode("append").format("json").save("/beifeng/result/json")\
上面虽然在追加的时候加上了sal,但是解析没有问题
sqlContext.read.format("json").load("/beifeng/result/json").show() 结果保存parquet格式
df.select("empno", "ename", "deptno").write.format("parquet").save("/beifeng/result/parquet01")
df.select("empno", "ename","sal", "deptno").write.mode("append").format("parquet").save("/beifeng/result/parquet01") ## 加上sal导致解析失败,读取数据的时候 sqlContext.read.format("parquet").load("/beifeng/result/parquet01").show(100)
sqlContext.read.format("parquet").load("/beifeng/result/parquet01/part*").show(100) partitionBy按照给定的字段进行分区
df.select("empno", "ename", "deptno").write.format("parquet").partitionBy("deptno").save("/beifeng/result/parquet02")
sqlContext.read.format("parquet").load("/beifeng/result/parquet02").show(100)
040 DataFrame中的write与read编程的更多相关文章
- pandas | 详解DataFrame中的apply与applymap方法
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是pandas数据处理专题的第5篇文章,我们来聊聊pandas的一些高级运算. 在上一篇文章当中,我们介绍了panads的一些计算方法, ...
- [引]MSDN Visual Basic 和 C# 中都会用到的编程概念
本文转自:http://msdn.microsoft.com/zh-cn/library/dd460655.aspx 本节介绍 Visual Basic 和 C# 中都会用到的编程概念. 本节内容 ...
- pandas,对dataFrame中某一个列的数据进行处理
背景:dataFrame的数据,想对某一个列做逻辑处理,生成新的列,或覆盖原有列的值 下面例子中的df均为pandas.DataFrame()的数据 1.增加新列,或更改某列的值 df[&qu ...
- [Spark][Python][DataFrame][RDD]DataFrame中抽取RDD例子
[Spark][Python][DataFrame][RDD]DataFrame中抽取RDD例子 sqlContext = HiveContext(sc) peopleDF = sqlContext. ...
- python – 基于pandas中的列中的值从DataFrame中选择行
如何从基于pandas中某些列的值的DataFrame中选择行?在SQL中我将使用: select * from table where colume_name = some_value. 我试图看看 ...
- Python中识别DataFrame中的nan
# 识别python中DataFrame中的nanfor i in pfsj.index: if type(pfsj.loc[i]['WZML']) == float: print('float va ...
- [Spark][Python]DataFrame中取出有限个记录的例子
[Spark][Python]DataFrame中取出有限个记录的例子: sqlContext = HiveContext(sc) peopleDF = sqlContext.read.json(&q ...
- STL中实现 iterator trail 的编程技巧
STL中实现 iterator trail 的编程技巧 <泛型编程和 STL>笔记及思考. 这篇文章主要记录在 STL 中迭代器设计过程中出现的编程技巧,围绕的 STL 主题为 (迭代器特 ...
- 更改 pandas dataframe 中两列的位置
更改 pandas dataframe 中两列的位置: 把其中的某列移到第一列的位置. 原来的 df 是: df = pd.read_csv('I:/Papers/consumer/codeandpa ...
随机推荐
- 【BZOJ1201】[HNOI2005]数三角形(暴力)
[BZOJ1201][HNOI2005]数三角形(暴力) 题面 BZOJ 洛谷 题解 预处理每个点向四个方向可以拓展的最大长度,然后钦定一个点作为三角形的某个顶点,暴力枚举三角形长度,检查这样一个三角 ...
- python的内置模块re模块方法详解以及使用
正则表达式 一.普通字符 . 通配符一个.只匹配一个字符 匹配任意除换行符"\n"外的字符(在DOTALL模式中也能匹配换行符 >>> import re ...
- 解决linux mysql命令 bash: mysql: command not found 的方法
错误: root@DB-02 ~]# mysql -u root-bash: mysql: command not found 原因:这是由于系统默认会查找/usr/bin下的命令,如果这个命令不在这 ...
- SHELL (1) —— shell脚本入门
摘自:Oldboy Linux运维——SHELL编程实战 SHELL Shell是一个命令解释器,解释执行用户输入的命令及程序等,用户每输入一条命令,Shell就解释执行一条.这种从键盘以输入命令,就 ...
- [iOS]Xcode+GitHub远程代码托管(GIT, SVN)
先来看看什么是代码远程托管: 其实就是将我们的代码上传到GitHub的服务器上, 供别人下载, 当然了也可以在团队开发的时候, 使用GitHub进行代码合并工作, 下面我们进入正题 (已经有远程仓库的 ...
- 用python处理文本,本地文件系统以及使用数据库的知识基础
主要是想通过python之流的脚本语言来进行文件系统的遍历,处理文本以及使用简易数据库的操作. 本文基于陈皓的:<程序员技术练级攻略> 一.Python csv 对于电子表格和数据库导出文 ...
- ASP.NET批量下载文件
一.实现步骤 在用户操作界面,由用户选择需要下载的文件,系统根据所选文件,在服务器上创建用于存储所选文件的临时文件夹,将所选文件拷贝至临时文件夹.然后调用 RAR程序,对临时文件夹进行压缩,然后输出到 ...
- expect 交互 telnet 交互
telnet 交互 #!/bin/bash Ip="10.0.1.53" a="\{\'method\'\:\'doLogin\'\,\'params\'\:\{\'uN ...
- Ubuntu 12.04安装后无法boot
解决方法是: 在选择启动项时, U盘会有两种启动方式: UEFI和非UEFI的. 用非UEFI进入live CD安装系统后无法启动, 用UEFI重装后问题解决.
- Ubuntu14.04搭建Android O编译环境
一.搭建环境 官方参考文档: 1.代号.标签和版本号 2.Factory Images 3.Driver Binaries 4.工具链 软硬件版本: 1.系统平台:I5-8500T+8G+1T,Ub ...