kafka清理
由于项目原因,最近经常碰到Kafka消息队列拥堵的情况。碰到这种情况为了不影响在线系统的正常使用,需要大家手动的清理Kafka Log。但是清理Kafka Log又不能单纯的去删除中间环节产生的日志,中间关联的很多东西需要手动同时去清理,否则可能会导致删除后客户端无法消费的情况。
在介绍手动删除操作之前,先简单的介绍一下Kafka消费Offset原理。
一、Kafka消费Offset
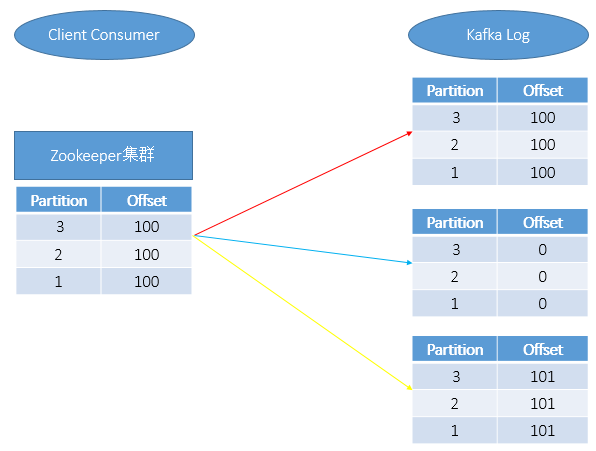
在通过Client端消费Kafka中的消息时,消费的消息会同时在Zookeeper和Kafka Log中保存,如上图红线所示。
当手动删除Kafka某一分片上的消息日志时,如上图蓝线所示,此是只是将Kafka Log中的信息清0了,但是Zookeeper中的Partition和Offset数据依然会记录。当重新启动Kafka后,我们会发现如下二种情况:
A、客户端无法正常用消费;
B、在使用Kafka Consumer Offset Monitor工具进行Kafka监控时会发现Lag(还有多少消息数未读取(Lag=logSize-Offset))为负数;其中此种情况的删除操作需要我们重点关注,后面我们也会详细介绍其对应的操作步骤。
一般正常情况,如果想让Kafka客户端正常消费,那么需要Zookeeper和Kafka Log中的记录保持如上图黄色所示。
Kafka具体消费原理可以参见:http://blog.xiaoxiaomo.com/2016/05/14/Kafka-Consumer%E6%B6%88%E8%B4%B9%E8%80%85/
二、Kafka消息日志清除
操作步骤主要包括:
1、停止Kafka运行;
2、删除Kafka消息日志;
3、修改ZK的偏移量;
4、重启Kafka;
上述步骤重点介绍其中的关键步骤。
在进行第2步:删除Kafka消息日志时,进入Kafka消息日志路径下,使用du -sh * 检查磁盘占用比较大的目录,然后删除此目录;
在进行第3步:修改ZK的偏移量时,进入ZK的安装目录下,运行./zkCli.sh -server (中间以,分割),如果不带server默认修改的为本机。
示例如下:
A.运行./zkCli.sh -server AAA:2181,BBB:2181,CCC:2181
B.在ZK上运行ls /consumers/对应的分组/offset/对应的topic,就可以看到此topic下的所有分区了;
通过get /consumers/对应的分组/offset/对应的topic/对应的分区号,可以查询到该分区上记录的offset;
通过set /consumers/对应的分组/offset/对应的topic/对应的分区号 修改后的值(一般为0),即可完成对offset的修改;
三、重建Topic
操作步骤主要包括如下:
1、删除Topic;
2、删除log日志;
3、删除ZK中的Topic记录
第一步:删除Topic
运行./kafka-topics.sh -delete -zookeeper [zookeeper server] -topic [topic name];如果kafka启动时加载的配置文件server.properties没有配置delete.topic.enable = true,那么此时的删除并不是真正的删除。而只是把topic标记为:marked for deletion,此时就需要执行第3步的操作;
第三步:删除ZK中的Topic记录
示例如下:
A.运行./zkCli.sh -server AAA:2181,BBB:2181,CCC:2181
B.进入/admin/delete_topics目录下,找到删除的topic,删除对应的信息。
四、常用命令
A.查看Kafka中的消息
|
1
2
|
./kafka-run-class.sh kafka.tools.DumpLogSegments -print-data-log -files /data01/middle/kafka-logs/00000002154.log >>aa.txtfind /dataa01 -mtime 0 -name *.log |xargs /kafka-run-class.sh kafka.tools.DumpLogSegments -print-data-log -files /data01/middle/kafka-logs/00000002154.log >>aa.txt |
0代表当天;-1代表昨天
kafka清理的更多相关文章
- kafka清理数据日志
背景问题: 使用kafka的路上踩过不少坑,其中一个就是在测试环境使用kafka一阵子以后,发现其日志目录变的很大,占了磁盘很大空间,定位到指定目录下发现其中一个系统自动创建的 topic,__con ...
- 转 kafka 清理数据
由于项目原因,最近经常碰到Kafka消息队列拥堵的情况.碰到这种情况为了不影响在线系统的正常使用,需要大家手动的清理Kafka Log.但是清理Kafka Log又不能单纯的去删除中间环节产生的日志, ...
- Kafka学习笔记之Kafka日志删出策略
0x00 概述 kafka将topic分成不同的partitions,每个partition的日志分成不同的segments,最后以segment为单位将陈旧的日志从文件系统删除. 假设kafka的在 ...
- kafka一些问题点的分析
kakfka架构图: 理解kafka需要理解三个问题. 1.producer,broker,consumer,ZK的工作模式. broker,ZK是作为一个后台服务,而producer和consume ...
- kafka实战教程(python操作kafka),kafka配置文件详解
kafka实战教程(python操作kafka),kafka配置文件详解 应用往Kafka写数据的原因有很多:用户行为分析.日志存储.异步通信等.多样化的使用场景带来了多样化的需求:消息是否能丢失?是 ...
- Kafka常用命令及详细介绍
目录 常用操作 Sentry kafka 清理 Kafka 术语 Kafka 主题剖析 Kafka 生产者 kafka 消费者和消费组 一致性和可用性 写入处理 失败处理 Kafka 客户端一致性 文 ...
- Kafka日志及Topic数据清理
由于项目原因,最近经常碰到Kafka消息队列拥堵的情况.碰到这种情况为了不影响在线系统的正常使用,需要大家手动的清理Kafka Log.但是清理Kafka Log又不能单纯的去删除中间环节产生的日志, ...
- 清理kafka zookeeper
; ; /; rm -rf /app/zookeeper/logs/*; rm -rf /app/pet_kafka_emds2_cluster/kafka-logs/*; rm -rf /app/p ...
- 漫游Kafka之过期数据清理【转】
转自:http://blog.csdn.net/honglei915/article/details/49683065 Kafka将数据持久化到了硬盘上,允许你配置一定的策略对数据清理,清理的策略有两 ...
随机推荐
- [Unity动画]06.子状态机
参考链接: https://www.jianshu.com/p/6b1db3d060ac?utm_campaign=maleskine&utm_content=note&utm_med ...
- activiti源代码的细节
由于activiti-explorer-5.14的web演示程序使用的是vaadin服务器端ui组件,程序关键点找起来还是有些麻烦,vaadin的这种web框架,就是不需要专门美术界面人员,只需要程序 ...
- centos6安装python3
1.安装环境 #yum install gcc zlib-devel make 2.下载python版本 #wget http://www.python.org/ftp/python/3.*.0/Py ...
- 2.HTML+CSS制作一闪一闪亮晶晶的星星(stars)
效果地址:https://codepen.io/flyingliao/pen/NJxbdB?editors=1100 HTML code: <div class="stars" ...
- kettle实现简单的增量同步
下载 pdi-ce-7.0.0.0-25.zip 解压 安装jdk 1.7以上的版本 配置环境变量 下载并将mysql-connector-java-5.1.39.jar 拷贝到 \data-inte ...
- Node.js之process模块
注意⚠️:process为nodejs内置对象,不需要实例化,改模块用来与当前进程进行互动,可以通过全局变量process访问,它是一个EventEmitter对象的实例. process对象提供一系 ...
- date命令的用法
date +%F data +%w, date +%W cal date -d "-1 years" +%F date -d "-1 hour" +%T 时间与 ...
- react-native android 集成 react-native-baidu-map
记录下 遇到的问题,方便以后查看,参考 文章 https://www.jianshu.com/p/7ca4d7acb6d2 1. npm install react-native-baidu-map ...
- 【转】Jenkins 二次开发 - Python
马克,备用: Jenkins 二次开发 https://testerhome.com/topics/14988?locale=zh-TW python-jenkins api 文档:https://p ...
- oracle 修改字符集 为ZHS16GBK
一.oracle server 端 字符集查询 select userenv('language') from dual 其中NLS_CHARACTERSET 为server端字符集 NLS_LANG ...