spm
看了很多关于SPM的介绍,但是网络上的资源大多都是对论文Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories的直接翻译,关于自己的理解谈得很少。这里主要写一下在我看了SPM论文和其提供的代码之后的感想。
SPM,一般中文翻译为空间金字塔,主要是计算机视觉中对图片的一种特征提取的方式. SPM的主要思想为:将图像分成若干块(sub-regions),分别统计每一子块的特征,最后将所有块的特征 拼接起来,形成完整的特征。这就是SPM中的Spatial。在分块的细节上,作者采用了一种多尺度的分块方法,即分块的粒度越大越细 (increasingly fine),呈现出一种层次金字塔的结构,这就是SPM中的Pyramid。
如果细心分析代码那么可以看到,代码主要分为4步来完成,分别对应一个function。
- GenerateSiftDescriptors:
该函数主要是来产生Sift特征,主要需要注意的是它将每一张图片分为了多个patch,这样对每个patch计算Sift特征,最后得到一个多维特征向量。在作者提供的Example中,一张图片480*640,那么对于16*16的patch,gridspacing为8,grid数量为(480/8-1)*(640/8-1)=4661那么可以得到的sift特征数量为4661,每个特征维度为128.
- CalculateDictionary
该函数很简单,就是将刚得到的特征用k-means的方法找到指定size的字典,这里指定的字典size=200或400.那么后面的每张图片的每个sift特征就可以用该字典来表示了,直接去字典里面找和该sift特征最接近的word,直接用index来表示,这个可以用sp_dist2函数来实现。这里注意的是:字典是一个200*128的矩阵,也就是每一行代表着一个k-mean得到的中心sift特征。这个可以在Example跑完后的data文件夹下的dictionary_size(200或400).mat中看到。
- BuildHistograms
该函数在论文里面是没有提到的,它的主要功能在于将每张图片得到的特征(该特征存放在imagename_sift.mat文件中,矩阵为4661*128)转化为texton,该词的翻译为基元,也就是将每张图片中的每个grid产生的sift特征在字典中给对应起来得到一个4661*1的矩阵,该矩阵存放在imagename_texton_ind_size(200).mat文件中。
- CompilePyramid
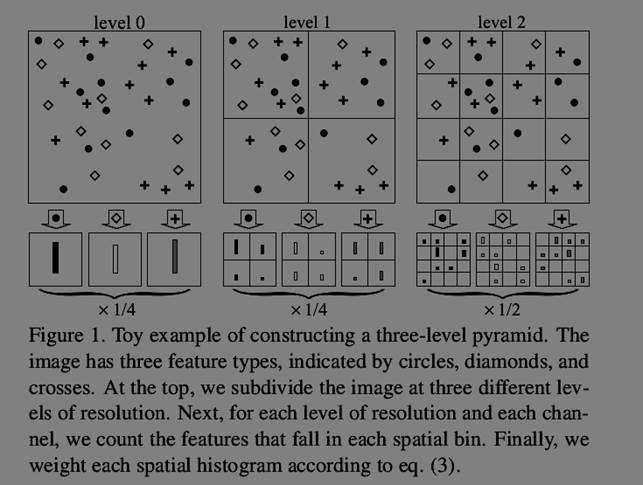
该函数是最后一步,也就是计算金字塔的步骤,在该函数中将图片按level来进行划分,也就是论文里面的那个图(如下),分了3层,层数l越大,则划分得越细,论文中有句话“More specifically, let us construct a sequence of grids
at resolutions 0, . . . , L, such that the grid at level l has 2 ^(l) cells along each dimension, for a total of D = 2^(dl) cells. ”,实际上意思是对于每层划分,
将图片按照行列的维度进行划分,l=2,则每行没列都做2^2=4个划分,也就是下图最右所示,则所有的cells也就是2^(2*2)=16,这里d=2,对于level l=0,1都是一样道理。做了这样的划分之后,首先计算的是划分最细的特征直方图,这里指的是level 2。那么这里对原图做了16patch的划分,然后计算刚才得到的texton中落在每个patch中的特征sift在词典中的index,多个sift所以形成了一个由index组合的向量,然后计算直方图,这里用hist函数来计算,主要是将词典中每个词也就是每个sift的index在刚得到的向量里面出现的次数得到一个直方图,该直方图是200维。那么对于16个patch都重复计算,最后得到的就是16个200维的直方图特征,所以对于level 2层最后将这些直方图连在一起,就是16*200维。
根据level 2的计算对level 1 ,0重复计算,不过由于粗粒度的特征计算包含了细粒度的计算,所以直接用level 2的计算结果就可以了,这部分代码比较简单,直接看代码就可以了。不过需要注意的是在代码中pyramid_cell这个变量的第一个cell实际上存放的是level 2的特征,是倒过来的。也就是pyramid_cell{1}存放4*4*200,pyramid_cell{2}存放的则是2*2*200,pyradmid{3}存放的则是1*1*200.
最后还有一步就是加权求整张图片级别的特征,这里的思想主要是细粒度的权重大,粗粒度的权重小,这里系数给的是2^(-l)(代码里给的,实际上对应论文里面的,这里l=1,2,3,刚好对应论文里面的2^(-(L-l))),不过这里需要注意的是对于l=3,权重系数为1-(1/2+1/4)=1/4,这是为了归一化。用该系数乘上每个patch得到的直方图特征,
将它们按照细粒度在前,粗粒度在后的顺序连在一起,形成一个4*4*200+2*2*200+1*1*200=4200维度的特征,这对应论文里面,这就是最后图片的特征描述。由于按照level来对图片进行划分,形成一个金字塔结构,所以叫空间金子塔结构。
- 最后
在论文里面还提到一些公式,如下
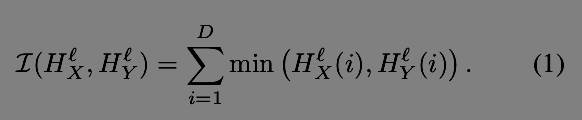
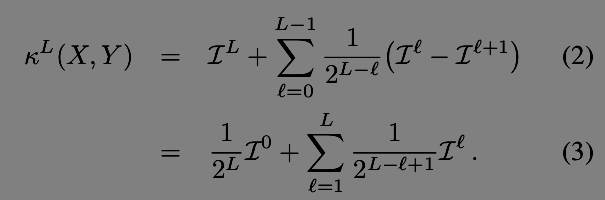
这几个公式主要用来估计相似度的,可以想象为给定两张图片,根据得到的Spm特征进行相似度估计,可以用欧式距离,这里给出了金字塔模型中的相似度估计方法。具体的做法在hist_isect函数中。在(1)中,该函数是一个直方图交集函数(histogram intersection function),对于每个grid产生的200维的直方图,也就是该grid中sift特征落在词典中每个bin的数量,对每个bin中的数量进行比较对小的求和,这就是直方图交集函数。实际代码中,就是先将一个直方图的等于0部分去掉也就是
nonzero_ind = find(x1(p,:)>0);
tmp_x1 = repmat(x1(p,nonzero_ind), [n 1]);
找到大于0部分的,(因为等于0的bin肯定是小的,加和没有意义,直接处理大于0部分就行),然后比较对应部分较小值求和就好。
K(p,:) = sum(min(tmp_x1,x2(:,nonzero_ind)),2)';
。
spm的更多相关文章
- 163邮箱问题:554 DT:SPM 163 smtp5,D9GowACHO7RNWNdXmXs1Bw--.9035S2
最近公司需要开发一个自定义邮箱功能,上网查询一下,利用163邮箱发送邮件. 由于163 的反垃圾机制,(坑爹机制.) 一般出现 554有在1)测试中用了test,测试,关键字在主题或者内容里面. 但是 ...
- 折腾一两天,终于学会使用grunt压缩合并混淆JS脚本,小激动,特意记录一下+spm一点意外收获
很长时间没有更新博客了,实在是太忙啦...0.0 ,以下的东西纯粹是记录,不是我原创,放到收藏夹还担心不够,这个以后常用,想来想去,还是放到这里吧,,丢不了..最后一句废话,网上搜集也好原创也罢,能解 ...
- https://yq.aliyun.com/articles/65125?spm=5176.100240.searchblog.18.afqQoU
https://yq.aliyun.com/articles/65125?spm=5176.100240.searchblog.18.afqQoU
- 利用SPM工具运行自己创建的小组件(使用common-model向后台接口请求数据)
步骤如下: 1.安装依赖:spm install -e 2.编译:spm build (编译好的东西会放在trunk-dist里面) 3.发布:spm app -d (会出来一个export端口,一般 ...
- 使用SPM创建新组件
(前提:已经安装好了spm) 步骤如下:
- notes:spm多重比较校正
SPM做完统计后,statistical table中的FDRc实际上是在该p-uncorrected下,可以令FDR-correcred p<=0.05的最小cluster中的voxel数目: ...
- GLM in SPM
主要记一句话: SPM的GLM模型中的β,指的是相应regressor对最后测量得到的信号所产生的效应(effect). 后续的假设检验过程实际上都是对各个regressor的β向量进行的. The ...
- SPM FDR校正
来源: http://blog.sciencenet.cn/blog-479412-572049.html,http://52brain.com/thread-15512-1-1.html SPM8允 ...
- SPM - data analysis
来源: SPM基本原理与使用PPT, 北师大,朱朝喆研究员,http://www.cnblogs.com/haore147/p/3633515.html ❤ First-level analysis: ...
- SPM paired t-test步骤
首先感谢大神空里流霜耐心的讲解,这篇笔记内容主要是整理他的谆谆教导,虽然他也看不到>< 所有数据都要经过平滑. Paired t-test虽然在2nd-level analysis中,但是 ...
随机推荐
- hexo发文章
http://blog.csdn.net/qq_36099238/article/details/54576089
- Notes of Daily Scrum Meeting(12.17)
我们会尽量安排好时间,在其他作业不受影响的情况下加快项目的进度,在Deadline之前完成Beta阶段的工作. 今天的团队工作总结如下: 团队成员 今日团队工作 陈少杰 调试网络连接,补充后端代码 王 ...
- Linux读书笔记第一周
1.Unix内核的特点:简洁:抽象:可移植性:进程创建:清晰的层次化结构. Linux内核是一种自由/开源的软件,设计思想与Unix系统相似(一切皆文件,特定的单一用途 & 简单的组合方式) ...
- 从零开始学Kotlin-基础语法(1)
从零开始学Kotlin基础篇系列文章 注释 //单行注释 /* 多行注释 */ /** * 多行注释 */ 定义变量/常量 变量定义:var 关键字 var <标识符> : <类型& ...
- Eclipse使用较多的快捷键
快速修正:Ctrl+1 单词补全:Alt+/ 快速Outline:Ctrl+O 删除行:Ctrl+D 选中到行末/行首:Shift+End/Home 注释:Ctrl+/ 变为大/小写:Ctrl+Shi ...
- PAT 甲级 1022 Digital Library
https://pintia.cn/problem-sets/994805342720868352/problems/994805480801550336 A Digital Library cont ...
- [转帖]DRAM芯片战争,跨越40年的生死搏杀
DRAM芯片战争,跨越40年的生死搏杀 超级工程一览 ·2017-08-20 12:50·半导体行业观察 阅读:1.4万 来源:内容来自超级工程一览 , 谢谢. DRAM是动态随机存储器的意思,也就是 ...
- [转帖] Kubernetes如何使用ReplicationController、Replica Set、Deployment管理Pod ----文章很好 但是还没具体操作实践 也还没记住.
Kubernetes如何使用ReplicationController.Replica Set.Deployment管理Pod https://blog.csdn.net/yjk13703623757 ...
- Laravel Service Provider 中 boot 方法和 register 方法的区别
register 方法用于绑定服务到容器,框架会先调用所有 provider 的 register 方法,等所有服务都注册完毕再去调用每一个服务的 boot 方法. 所以不能在 register 方法 ...
- 一本通1623Sherlock and His Girlfriend
1623:Sherlock and His Girlfriend 时间限制: 1000 ms 内存限制: 524288 KB [题目描述] 原题来自:Codeforces Round ...