[机器学习笔记]奇异值分解SVD简介及其在推荐系统中的简单应用
本文先从几何意义上对奇异值分解SVD进行简单介绍,然后分析了特征值分解与奇异值分解的区别与联系,最后用python实现将SVD应用于推荐系统。
1.SVD详解
SVD(singular value decomposition),翻译成中文就是奇异值分解。SVD的用处有很多,比如:LSA(隐性语义分析)、推荐系统、特征压缩(或称数据降维)。SVD可以理解为:将一个比较复杂的矩阵用更小更简单的3个子矩阵的相乘来表示,这3个小矩阵描述了大矩阵重要的特性。
1.1奇异值分解的几何意义(因公式输入比较麻烦所以采取截图的方式)
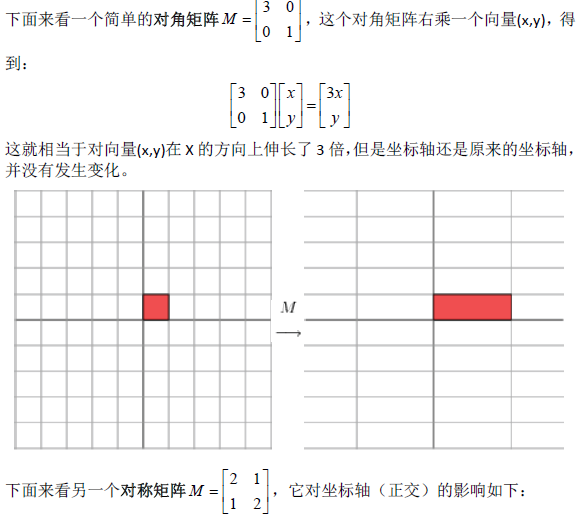
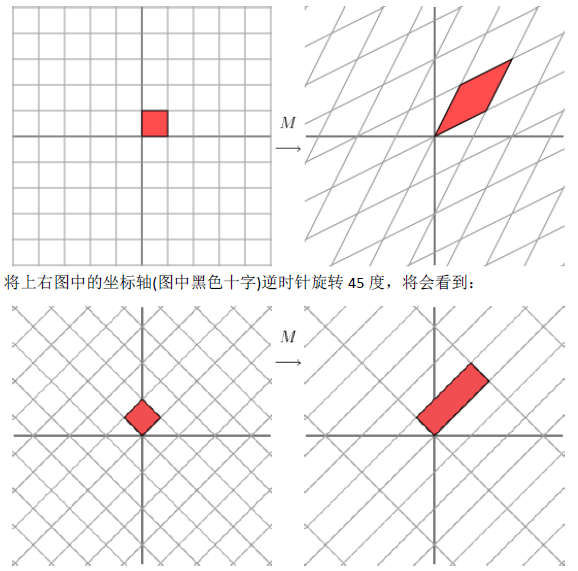

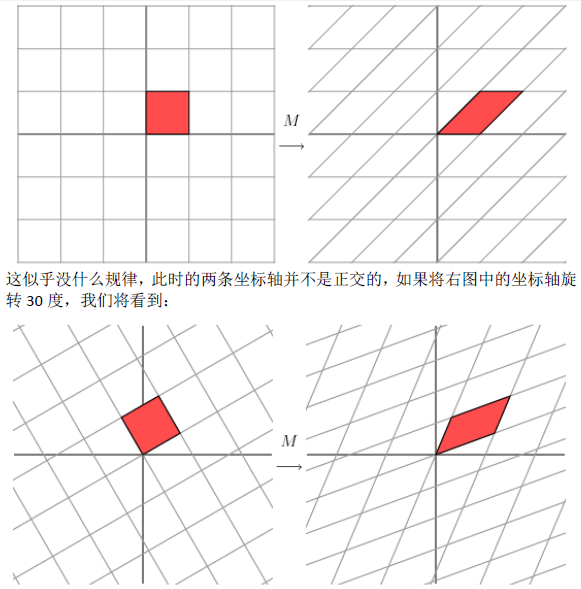
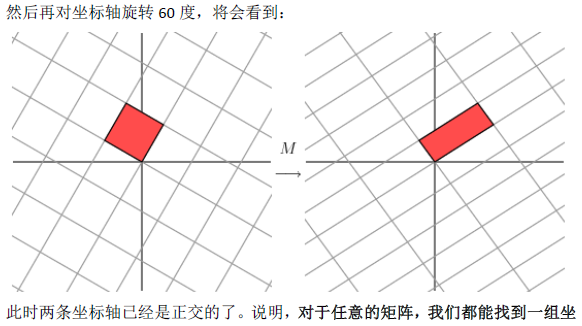
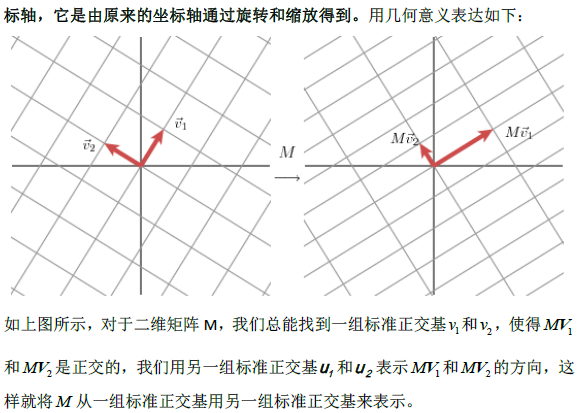








2.SVD应用于推荐系统
数据集中行代表用户user,列代表物品item,其中的值代表用户对物品的打分。基于SVD的优势在于:用户的评分数据是稀疏矩阵,可以用SVD将原始数据映射到低维空间中,然后计算物品item之间的相似度,可以节省计算资源。
整体思路:先找到用户没有评分的物品,然后再经过SVD“压缩”后的低维空间中,计算未评分物品与其他物品的相似性,得到一个预测打分,再对这些物品的评分从高到低进行排序,返回前N个物品推荐给用户。
具体代码如下,主要分为5部分:
第1部分:加载测试数据集;
第2部分:定义三种计算相似度的方法;
第3部分:通过计算奇异值平方和的百分比来确定将数据降到多少维才合适,返回需要降到的维度;
第4部分:在已经降维的数据中,基于SVD对用户未打分的物品进行评分预测,返回未打分物品的预测评分值;
第5部分:产生前N个评分值高的物品,返回物品编号以及预测评分值。
优势在于:用户的评分数据是稀疏矩阵,可以用SVD将数据映射到低维空间,然后计算低维空间中的item之间的相似度,对用户未评分的item进行评分预测,最后将预测评分高的item推荐给用户。
#coding=utf-8
from numpy import *
from numpy import linalg as la '''加载测试数据集'''
def loadExData():
return mat([[0, 0, 0, 0, 0, 4, 0, 0, 0, 0, 5],
[0, 0, 0, 3, 0, 4, 0, 0, 0, 0, 3],
[0, 0, 0, 0, 4, 0, 0, 1, 0, 4, 0],
[3, 3, 4, 0, 0, 0, 0, 2, 2, 0, 0],
[5, 4, 5, 0, 0, 0, 0, 5, 5, 0, 0],
[0, 0, 0, 0, 5, 0, 1, 0, 0, 5, 0],
[4, 3, 4, 0, 0, 0, 0, 5, 5, 0, 1],
[0, 0, 0, 4, 0, 4, 0, 0, 0, 0, 4],
[0, 0, 0, 2, 0, 2, 5, 0, 0, 1, 2],
[0, 0, 0, 0, 5, 0, 0, 0, 0, 4, 0],
[1, 0, 0, 0, 0, 0, 0, 1, 2, 0, 0]]) '''以下是三种计算相似度的算法,分别是欧式距离、皮尔逊相关系数和余弦相似度,
注意三种计算方式的参数inA和inB都是列向量'''
def ecludSim(inA,inB):
return 1.0/(1.0+la.norm(inA-inB)) #范数的计算方法linalg.norm(),这里的1/(1+距离)表示将相似度的范围放在0与1之间 def pearsSim(inA,inB):
if len(inA)<3: return 1.0
return 0.5+0.5*corrcoef(inA,inB,rowvar=0)[0][1] #皮尔逊相关系数的计算方法corrcoef(),参数rowvar=0表示对列求相似度,这里的0.5+0.5*corrcoef()是为了将范围归一化放到0和1之间 def cosSim(inA,inB):
num=float(inA.T*inB)
denom=la.norm(inA)*la.norm(inB)
return 0.5+0.5*(num/denom) #将相似度归一到0与1之间 '''按照前k个奇异值的平方和占总奇异值的平方和的百分比percentage来确定k的值,
后续计算SVD时需要将原始矩阵转换到k维空间'''
def sigmaPct(sigma,percentage):
sigma2=sigma**2 #对sigma求平方
sumsgm2=sum(sigma2) #求所有奇异值sigma的平方和
sumsgm3=0 #sumsgm3是前k个奇异值的平方和
k=0
for i in sigma:
sumsgm3+=i**2
k+=1
if sumsgm3>=sumsgm2*percentage:
return k '''函数svdEst()的参数包含:数据矩阵、用户编号、物品编号和奇异值占比的阈值,
数据矩阵的行对应用户,列对应物品,函数的作用是基于item的相似性对用户未评过分的物品进行预测评分'''
def svdEst(dataMat,user,simMeas,item,percentage):
n=shape(dataMat)[1]
simTotal=0.0;ratSimTotal=0.0
u,sigma,vt=la.svd(dataMat)
k=sigmaPct(sigma,percentage) #确定了k的值
sigmaK=mat(eye(k)*sigma[:k]) #构建对角矩阵
xformedItems=dataMat.T*u[:,:k]*sigmaK.I #根据k的值将原始数据转换到k维空间(低维),xformedItems表示物品(item)在k维空间转换后的值
for j in range(n):
userRating=dataMat[user,j]
if userRating==0 or j==item:continue
similarity=simMeas(xformedItems[item,:].T,xformedItems[j,:].T) #计算物品item与物品j之间的相似度
simTotal+=similarity #对所有相似度求和
ratSimTotal+=similarity*userRating #用"物品item和物品j的相似度"乘以"用户对物品j的评分",并求和
if simTotal==0:return 0
else:return ratSimTotal/simTotal #得到对物品item的预测评分 '''函数recommend()产生预测评分最高的N个推荐结果,默认返回5个;
参数包括:数据矩阵、用户编号、相似度衡量的方法、预测评分的方法、以及奇异值占比的阈值;
数据矩阵的行对应用户,列对应物品,函数的作用是基于item的相似性对用户未评过分的物品进行预测评分;
相似度衡量的方法默认用余弦相似度'''
def recommend(dataMat,user,N=5,simMeas=cosSim,estMethod=svdEst,percentage=0.9):
unratedItems=nonzero(dataMat[user,:].A==0)[1] #建立一个用户未评分item的列表
if len(unratedItems)==0:return 'you rated everything' #如果都已经评过分,则退出
itemScores=[]
for item in unratedItems: #对于每个未评分的item,都计算其预测评分
estimatedScore=estMethod(dataMat,user,simMeas,item,percentage)
itemScores.append((item,estimatedScore))
itemScores=sorted(itemScores,key=lambda x:x[1],reverse=True)#按照item的得分进行从大到小排序
return itemScores[:N] #返回前N大评分值的item名,及其预测评分值
将文件命名为svd2.py,在python提示符下输入:
>>>import svd2
>>>testdata=svd2.loadExData()
>>>svd2.recommend(testdata,1,N=3,percentage=0.8)#对编号为1的用户推荐评分较高的3件商品
Reference:
1.Peter Harrington,《机器学习实战》,人民邮电出版社,2013
2.http://www.ams.org/samplings/feature-column/fcarc-svd (讲解SVD非常好的一篇文章,对于理解SVD非常有帮助,本文中SVD的几何意义就是参考这篇)
3. http://blog.csdn.net/xiahouzuoxin/article/details/41118351 (讲解SVD与特征值分解区别的一篇文章)
[机器学习笔记]奇异值分解SVD简介及其在推荐系统中的简单应用的更多相关文章
- SVD在餐馆菜肴推荐系统中的应用
SVD在餐馆菜肴推荐系统中的应用 摘要:餐馆可以分为很多类别,比如中式.美式.日式等等.但是这些类别不一定够用,有的人喜欢混合类别.对用户对菜肴的点评数据进行分析,可以提取出区分菜品的真正因素,利用这 ...
- 【疑难杂症】奇异值分解(SVD)原理与在降维中的应用
前言 在项目实战的特征工程中遇到了采用SVD进行降维,具体SVD是什么,怎么用,原理是什么都没有细说,因此特开一篇,记录下SVD的学习笔记 参考:刘建平老师博客 https://www.cnblogs ...
- 机器学习之-奇异值分解(SVD)原理详解及推导
转载 http://blog.csdn.net/zhongkejingwang/article/details/43053513 在网上看到有很多文章介绍SVD的,讲的也都不错,但是感觉还是有需要补充 ...
- [机器学习笔记]主成分分析PCA简介及其python实现
主成分分析(principal component analysis)是一种常见的数据降维方法,其目的是在“信息”损失较小的前提下,将高维的数据转换到低维,从而减小计算量. PCA的本质就是找一些投影 ...
- 奇异值分解(SVD)原理与在降维中的应用
奇异值分解(Singular Value Decomposition,以下简称SVD)是在机器学习领域广泛应用的算法,它不光可以用于降维算法中的特征分解,还可以用于推荐系统,以及自然语言处理等领域.是 ...
- 机器学习实战(Machine Learning in Action)学习笔记————10.奇异值分解(SVD)原理、基于协同过滤的推荐引擎、数据降维
关键字:SVD.奇异值分解.降维.基于协同过滤的推荐引擎作者:米仓山下时间:2018-11-3机器学习实战(Machine Learning in Action,@author: Peter Harr ...
- Python机器学习笔记:奇异值分解(SVD)算法
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 奇异值分解(Singu ...
- 机器学习降维方法概括, LASSO参数缩减、主成分分析PCA、小波分析、线性判别LDA、拉普拉斯映射、深度学习SparseAutoEncoder、矩阵奇异值分解SVD、LLE局部线性嵌入、Isomap等距映射
机器学习降维方法概括 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/u014772862/article/details/52335970 最近 ...
- 【Machine Learning】机器学习及其基础概念简介
机器学习及其基础概念简介 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
随机推荐
- http_proxy_module模块常用参数
Nginx的upstream模块相当于是建立一个函数库一样,把后端的服务器地址放在了一个池子里,而proxy模块则是从这个池子里调用了这些服务器. http_proxy_module模块常用参数: p ...
- SpringBoot整合阿里Druid数据源及Spring-Data-Jpa
SpringBoot整合阿里Druid数据源及Spring-Data-Jpa https://mp.weixin.qq.com/s?__biz=MzU0MDEwMjgwNA==&mid=224 ...
- Jupyter Notebook添加Ruby支持
安装步骤 gem install iruby iruby register --force 参考资料:http://devopspy.com/linux/ruby-kernel-jupyter-not ...
- pandas中遍历dataframe的每一个元素
假如有一个需求场景需要遍历一个csv或excel中的每一个元素,判断这个元素是否含有某个关键字 那么可以用python的pandas库来实现. 方法一: pandas的dataframe有一个很好用的 ...
- 腾讯云centos7安装MySQL
centos就centos呗,为什么要加个腾讯云呢?有这种疑问的兄dei,一定是没被不同云的系统坑过啊,阿里云的Ubuntu和腾讯云的Ubuntu不一样,centos好像也有差别,各个云平台,同样的系 ...
- Python线程状态和全局解释器锁
在刚接触Python的时候时常听到GIL这个词,并且发现这个词经常和Python无法高效的实现多线程划上等号.本着不光要知其然,还要知其所以然的研究态度,博主搜集了各方面的资料,花了一周内几个小时的闲 ...
- request鉴权的处理和判断
一般查看蝉道bug管理工具bug列表的时候,会提示 Unauthorized access,那是因为需要用户名和密码,一般用基本的认证,代码如下: 不是所有的系统都是开放的,有些人是不可以访问的,所 ...
- python之三元表达式、列表推导、生成器表达式、递归、匿名函数、内置函数
目录 一 三元表达式 二 列表推到 三 生成器表达式 四 递归 五 匿名函数 六 内置函数 一.三元表达式 def max(x,y): return x if x>y else y print( ...
- pxc5.7配置安装
pxc5.7配置安装 一.准备工作 # Centos6. 最小化安装操作系统 ########################---- Centos最小化安装推荐常用依赖包---- ######### ...
- 信用评分卡 (part 7 of 7)
python信用评分卡(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_camp ...