彻底搞懂Scrapy的中间件(三)
在前面两篇文章介绍了下载器中间件的使用,这篇文章将会介绍爬虫中间件(Spider Middleware)的使用。
爬虫中间件
爬虫中间件的用法与下载器中间件非常相似,只是它们的作用对象不同。下载器中间件的作用对象是请求request和返回response;爬虫中间件的作用对象是爬虫,更具体地来说,就是写在spiders文件夹下面的各个文件。它们的关系,在Scrapy的数据流图上可以很好地区分开来,如下图所示。
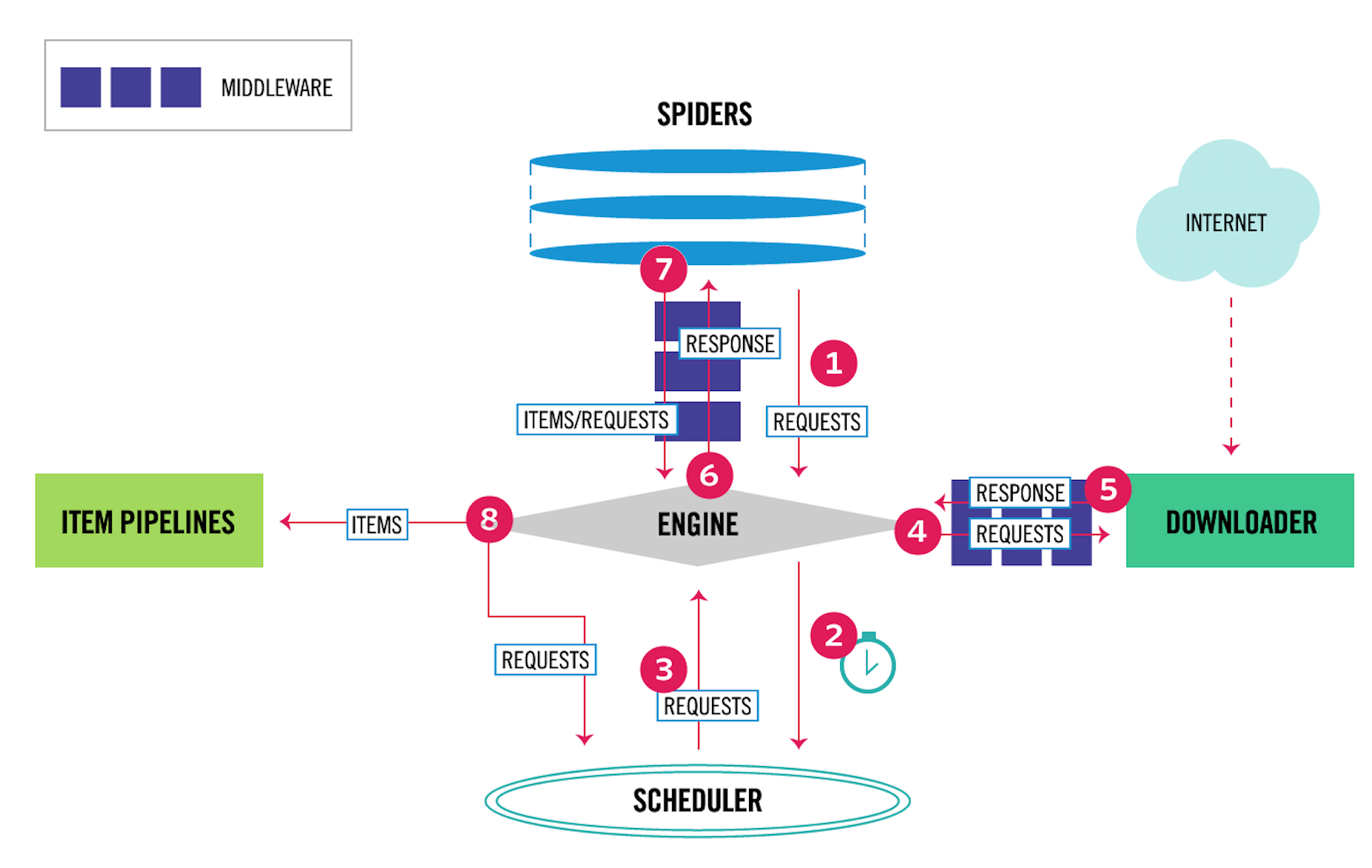
其中,4、5表示下载器中间件,6、7表示爬虫中间件。爬虫中间件会在以下几种情况被调用。
- 当运行到
yield scrapy.Request()或者yield item的时候,爬虫中间件的process_spider_output()方法被调用。 - 当爬虫本身的代码出现了
Exception的时候,爬虫中间件的process_spider_exception()方法被调用。 - 当爬虫里面的某一个回调函数
parse_xxx()被调用之前,爬虫中间件的process_spider_input()方法被调用。 - 当运行到
start_requests()的时候,爬虫中间件的process_start_requests()方法被调用。
在中间件处理爬虫本身的异常
在爬虫中间件里面可以处理爬虫本身的异常。例如编写一个爬虫,爬取UA练习页面http://exercise.kingname.info/exercise_middleware_ua ,故意在爬虫中制造一个异常,如图12-26所示。
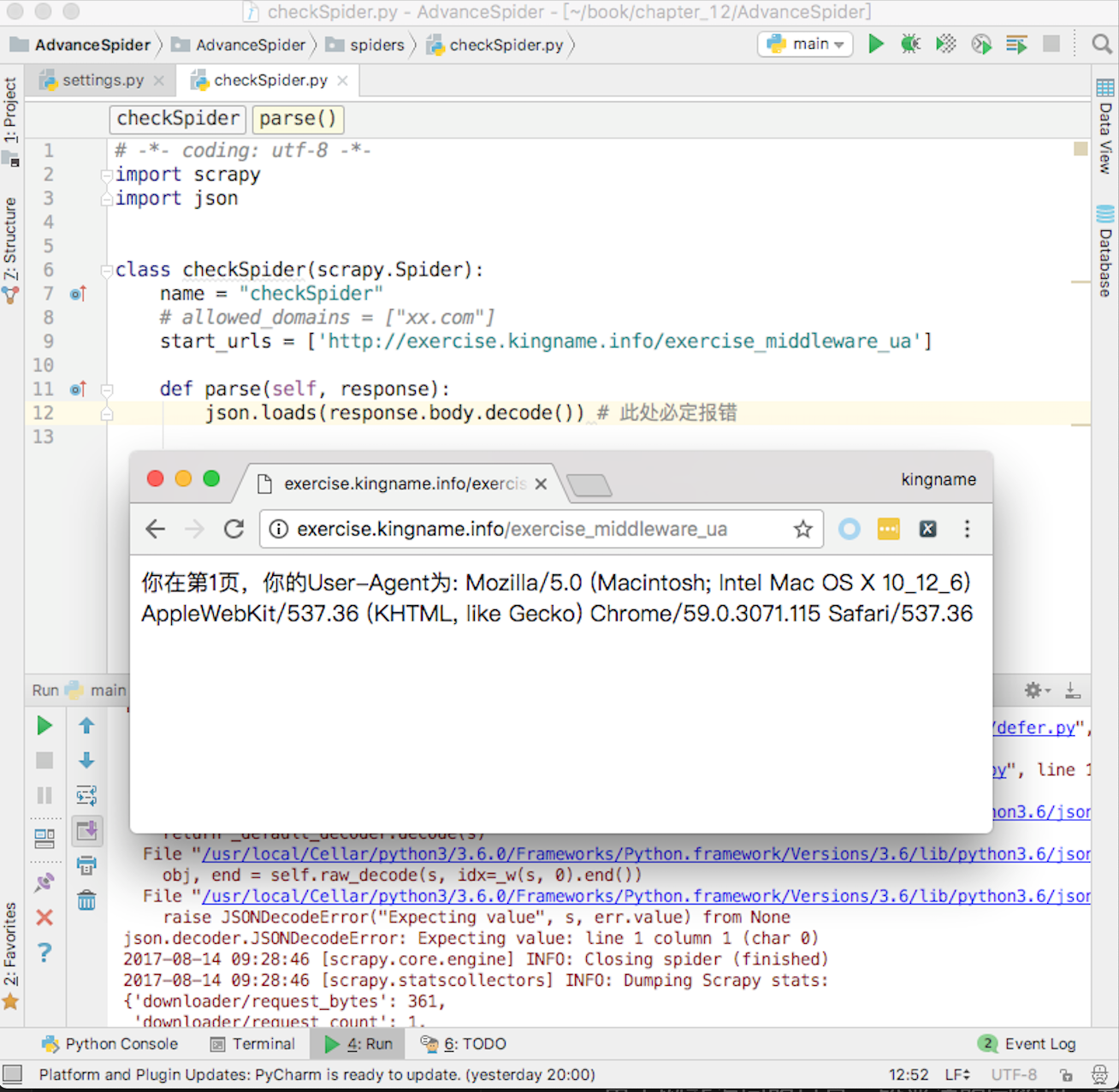
由于网站返回的只是一段普通的字符串,并不是JSON格式的字符串,因此使用JSON去解析,就一定会导致报错。这种报错和下载器中间件里面遇到的报错不一样。下载器中间件里面的报错一般是由于外部原因引起的,和代码层面无关。而现在的这种报错是由于代码本身的问题导致的,是代码写得不够周全引起的。
为了解决这个问题,除了仔细检查代码、考虑各种情况外,还可以通过开发爬虫中间件来跳过或者处理这种报错。在middlewares.py中编写一个类:
class ExceptionCheckSpider(object):
def process_spider_exception(self, response, exception, spider):
print(f'返回的内容是:{response.body.decode()}\n报错原因:{type(exception)}')
return None
这个类仅仅起到记录Log的作用。在使用JSON解析网站返回内容出错的时候,将网站返回的内容打印出来。
process_spider_exception()这个方法,它可以返回None,也可以运行yield item语句或者像爬虫的代码一样,使用yield scrapy.Request()发起新的请求。如果运行了yield item或者yield scrapy.Request(),程序就会绕过爬虫里面原有的代码。
例如,对于有异常的请求,不需要进行重试,但是需要记录是哪一个请求出现了异常,此时就可以在爬虫中间件里面检测异常,然后生成一个只包含标记的item。还是以抓取http://exercise.kingname.info/exercise_middleware_retry.html这个练习页的内容为例,但是这一次不进行重试,只记录哪一页出现了问题。先看爬虫的代码,这一次在meta中把页数带上,如下图所示。

爬虫里面如果发现了参数错误,就使用raise这个关键字人工抛出一个自定义的异常。在实际爬虫开发中,读者也可以在某些地方故意不使用try ... except捕获异常,而是让异常直接抛出。例如XPath匹配处理的结果,直接读里面的值,不用先判断列表是否为空。这样如果列表为空,就会被抛出一个IndexError,于是就能让爬虫的流程进入到爬虫中间件的process_spider_exception()中。
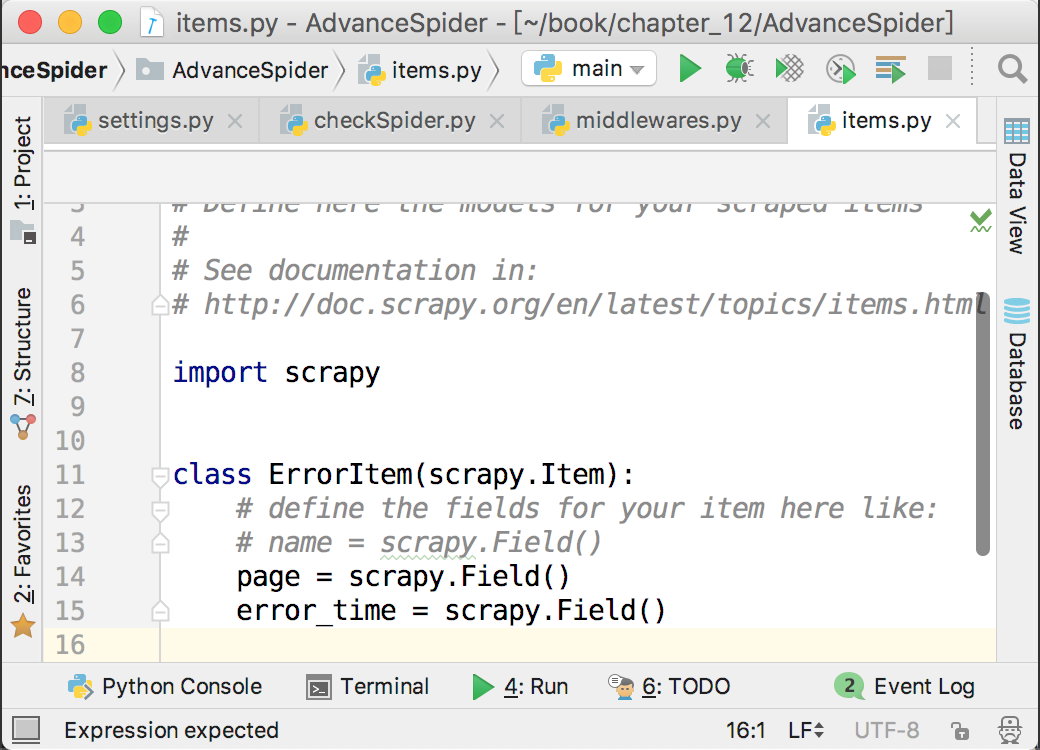
在items.py里面创建了一个ErrorItem来记录哪一页出现了问题,如下图所示。
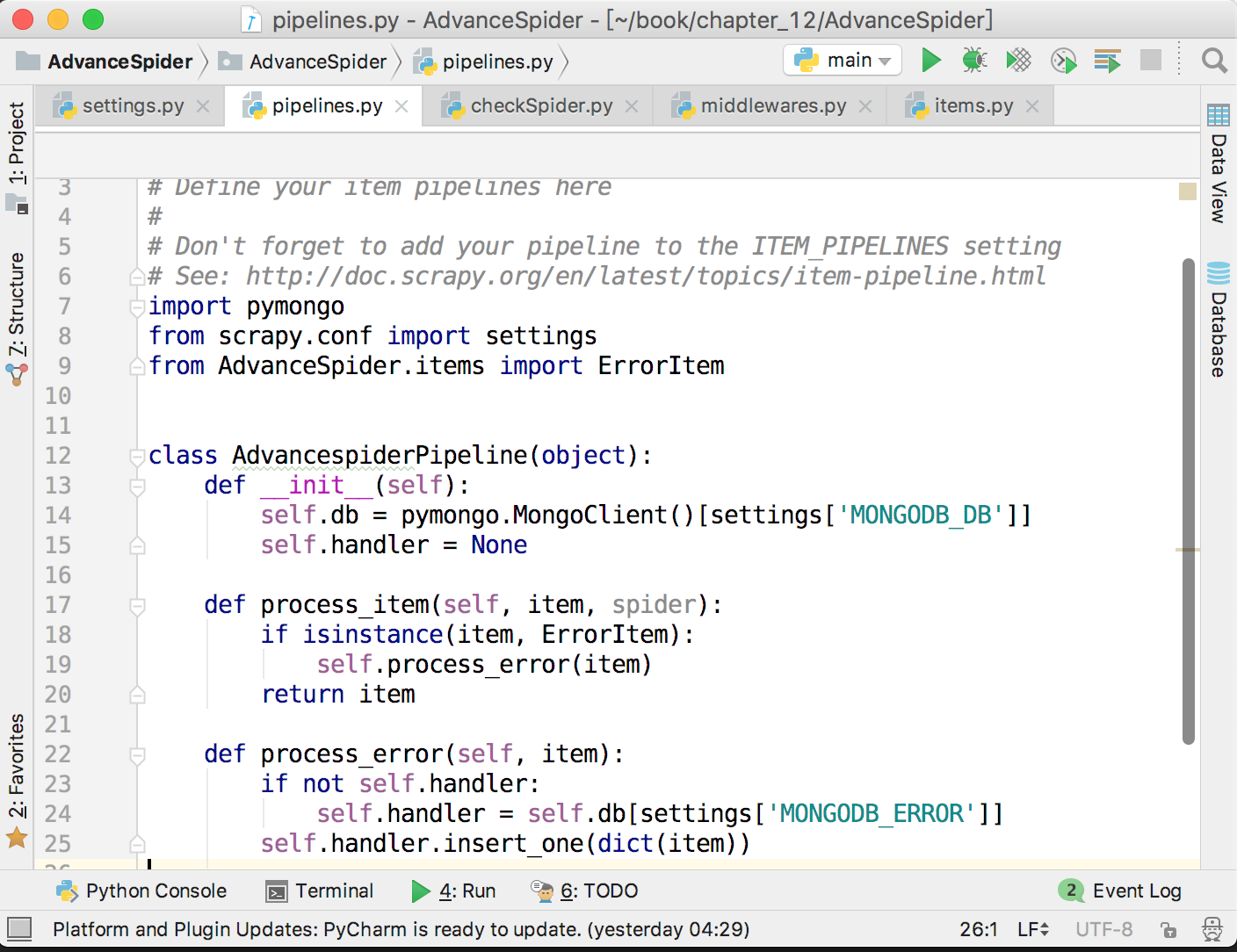
接下来,在爬虫中间件中将出错的页面和当前时间存放到ErrorItem里面,并提交给pipeline,保存到MongoDB中,如下图所示。
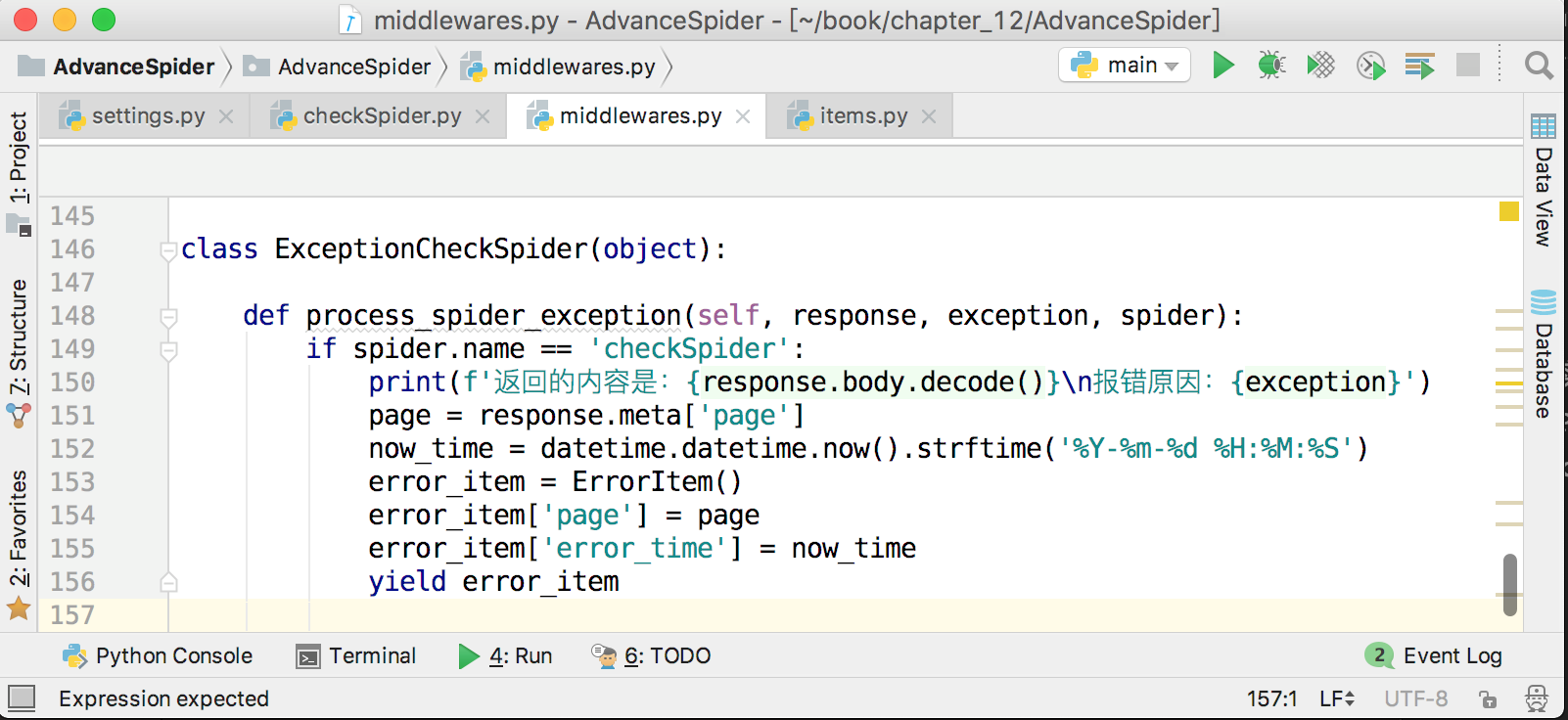
这样就实现了记录错误页数的功能,方便在后面对错误原因进行分析。由于这里会把item提交给pipeline,所以不要忘记在settings.py里面打开pipeline,并配置好MongoDB。储存错误页数到MongoDB的代码如下图所示。
激活爬虫中间件
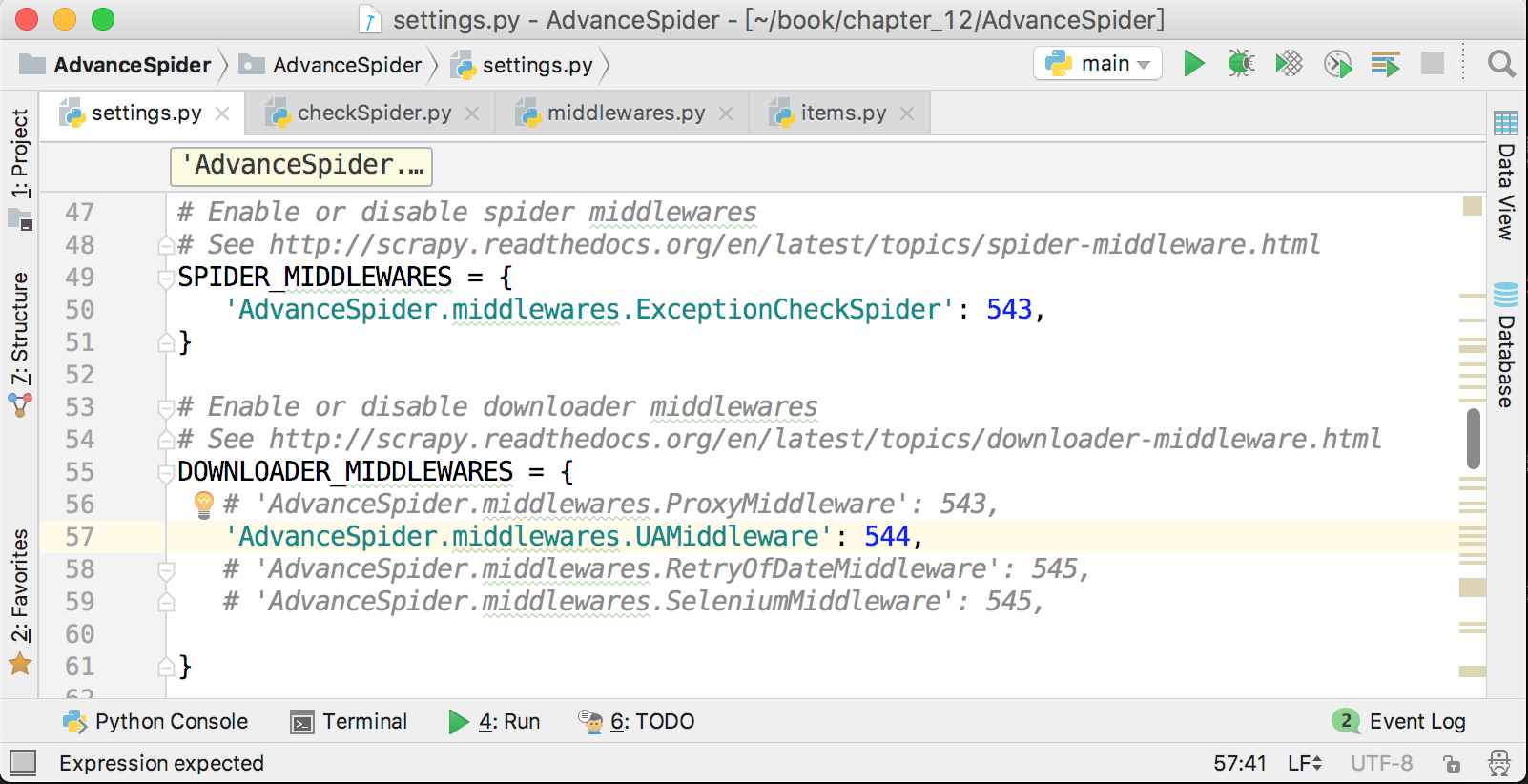
爬虫中间件的激活方式与下载器中间件非常相似,在settings.py中,在下载器中间件配置项的上面就是爬虫中间件的配置项,它默认也是被注释了的,解除注释,并把自定义的爬虫中间件添加进去即可,如下图所示。
Scrapy也有几个自带的爬虫中间件,它们的名字和顺序如下图所示。

下载器中间件的数字越小越接近Scrapy引擎,数字越大越接近爬虫。如果不能确定自己的自定义中间件应该靠近哪个方向,那么就在500~700之间选择最为妥当。
爬虫中间件输入/输出
在爬虫中间件里面还有两个不太常用的方法,分别为process_spider_input(response, spider)和process_spider_output(response, result, spider)。其中,process_spider_input(response, spider)在下载器中间件处理完成后,马上要进入某个回调函数parse_xxx()前调用。process_spider_output(response, result, output)是在爬虫运行yield item或者yield scrapy.Request()的时候调用。在这个方法处理完成以后,数据如果是item,就会被交给pipeline;如果是请求,就会被交给调度器,然后下载器中间件才会开始运行。所以在这个方法里面可以进一步对item或者请求做一些修改。这个方法的参数result就是爬虫爬出来的item或者scrapy.Request()。由于yield得到的是一个生成器,生成器是可以迭代的,所以result也是可以迭代的,可以使用for循环来把它展开。
def process_spider_output(response, result, spider):
for item in result:
if isinstance(item, scrapy.Item):
# 这里可以对即将被提交给pipeline的item进行各种操作
print(f'item将会被提交给pipeline')
yield item
或者对请求进行监控和修改:
def process_spider_output(response, result, spider):
for request in result:
if not isinstance(request, scrapy.Item):
# 这里可以对请求进行各种修改
print('现在还可以对请求对象进行修改。。。。')
request.meta['request_start_time'] = time.time()
yield request
本文节选自我的新书《Python爬虫开发 从入门到实战》完整目录可以在京东查询到 https://item.jd.com/12436581.html
彻底搞懂Scrapy的中间件(三)的更多相关文章
- 彻底搞懂Scrapy的中间件(一)
中间件是Scrapy里面的一个核心概念.使用中间件可以在爬虫的请求发起之前或者请求返回之后对数据进行定制化修改,从而开发出适应不同情况的爬虫. "中间件"这个中文名字和前面章节讲到 ...
- 彻底搞懂Scrapy的中间件(二)
在上一篇文章中介绍了下载器中间件的一些简单应用,现在再来通过案例说说如何使用下载器中间件集成Selenium.重试和处理请求异常. 在中间件中集成Selenium 对于一些很麻烦的异步加载页面,手动寻 ...
- 彻底搞懂 etcd 系列文章(三):etcd 集群运维部署
0 专辑概述 etcd 是云原生架构中重要的基础组件,由 CNCF 孵化托管.etcd 在微服务和 Kubernates 集群中不仅可以作为服务注册与发现,还可以作为 key-value 存储的中间件 ...
- 完全搞懂傅里叶变换和小波(2)——三个中值定理<转载>
书接上文,本文章是该系列的第二篇,按照总纲中给出的框架,本节介绍三个中值定理,包括它们的证明及几何意义.这三个中值定理是高等数学中非常基础的部分,如果读者对于高数的内容已经非常了解,大可跳过此部分.当 ...
- hiho一下 第二十九周 最小生成树三·堆优化的Prim算法【14年寒假弄了好长时间没搞懂的prim优化:prim算法+堆优化 】
题目1 : 最小生成树三·堆优化的Prim算法 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 回到两个星期之前,在成功的使用Kruscal算法解决了问题之后,小Ho产生 ...
- 三文搞懂学会Docker容器技术(中)
接着上面一篇:三文搞懂学会Docker容器技术(上) 6,Docker容器 6.1 创建并启动容器 docker run [OPTIONS] IMAGE [COMMAND] [ARG...] --na ...
- 三文搞懂学会Docker容器技术(下)
接着上面一篇:三文搞懂学会Docker容器技术(上) 三文搞懂学会Docker容器技术(中) 7,Docker容器目录挂载 7.1 简介 容器目录挂载: 我们可以在创建容器的时候,将宿主机的目录与容器 ...
- c#代码 天气接口 一分钟搞懂你的博客为什么没人看 看完python这段爬虫代码,java流泪了c#沉默了 图片二进制转换与存入数据库相关 C#7.0--引用返回值和引用局部变量 JS直接调用C#后台方法(ajax调用) Linq To Json SqlServer 递归查询
天气预报的程序.程序并不难. 看到这个需求第一个想法就是只要找到合适天气预报接口一切都是小意思,说干就干,立马跟学生沟通价格. 不过谈报价的过程中,差点没让我一口老血喷键盘上,话说我们程序猿的人 ...
- 搞懂分布式技术2:分布式一致性协议与Paxos,Raft算法
搞懂分布式技术2:分布式一致性协议与Paxos,Raft算法 2PC 由于BASE理论需要在一致性和可用性方面做出权衡,因此涌现了很多关于一致性的算法和协议.其中比较著名的有二阶提交协议(2 Phas ...
随机推荐
- 【bug记录】OS Lab3 踩坑记
OS Lab3 踩坑记 Lab3在之前Lab2的基础上,增加了进程建立.调度和中断异常处理.其中测试包括进程建立以及进程调度部分. 由于是第一次做bug记录,而且是调试完bug后再做的记录,所以导致记 ...
- JDK安装与环境配置——学习JAVA的准备工作
1.安装JDK 官网,版本看了也不明白区别,我下载的第一个 JAVA SE 12 https://www.oracle.com/technetwork/java/javase/downloads/in ...
- 网页真机调试之Browsersync简介
以前的调试方式 修改完项目文件(html.js.css等)后保存,在浏览器刷新页面查看修改后的效果 本地开启一个 tomcat 服务,修改文件后保存刷新页面,移动端或其他 pc 则需要输入 ip + ...
- 《python for data analysis》第九章,数据聚合与分组运算
# -*- coding:utf-8 -*-# <python for data analysis>第九章# 数据聚合与分组运算import pandas as pdimport nump ...
- Vue字符串传入变量
- java 重载、重写、重构的区别
1.重载 构造函数是一种特殊的函数,使用构造函数的目的是用来在对象实例化时初始化对象的成员变量.由于构造函数名字必须与类名一致,我们想用不同的方式实例化对象时,必须允许不同的构造方法同时存在,这就用到 ...
- RabbitMq C# .net 教程
本文转载来自 [http://www.cnblogs.com/yangecnu/p/Introduce-RabbitMQ.html]写的很详细. 文件安装包官方DEMO下载地址是:http://pan ...
- 华为4K机顶盒EC6108V9U从原联通更换为电信的IPTV账号成功经验
4K设备直接在淘宝上买30块钱升级4K机顶盒,i视视手机app控制电视和手机投屏 硬件设备:EC6108V9U由X省联通更换为四川电信 采坑经验: 1.要从现有的机顶盒获取mac地址.stbid.ip ...
- 【Oracle】ORA-14400: 插入的分区关键字未映射到任何分区
问题描述: 工作中使用kettle将原始库中的数据抽取到标准库中,在抽取过程中报错:[ORA-14400: 插入的分区关键字未映射到任何分区]/[ORA-14400: inserted partiti ...
- hiero.ui获取实例名的方法
在hiero.ui中经常会通过hiero.ui.windowManager().windows()来获取当前QMainWindow中的QWidget子窗口,而这些子窗口是以实例对象的方式返回的,如果想 ...