mysql数据库分区和分表
转载自 https://www.cnblogs.com/miketwais/articles/mysql_partition.html https://blog.csdn.net/vbirdbest/article/details/82461109
mysql数据库分表及实现
项目开发中,我们的数据库数据越来越大,随之而来的是单个表中数据太多。以至于查询书读变慢,而且由于表的锁机制导致应用操作也搜到严重影响,出现了数据库性能瓶颈。
当出现这种情况时,我们可以考虑分表,即将单个数据库表进行拆分,拆分成多个数据表,然后用户访问的时候,根据一定的算法,让用户访问不同的表,这样数据分散到多个数据表中,减少了单个数据表的访问压力。提升了数据库访问性能。
我们可以进行简单的设想:现在有一个表products存储产品信息,现在有100万用户在线访问,就要进行至少100万次请求,现在我们如果将它分成100个表即products0~~products99,那么利用一定的算法我们就分担了单个表的访问压力,每个表只有1万个请求(当然,这是理想情况下!)
实现mysql 分表的关键在于:设计良好的算法来确定"什么时候情况下访问什么(哪个)表"。
下面我们先来实现一个简单的mysql分表演示:这里使用MERGE分表法
1,创建一个完整表存储着所有的成员信息
create table member(
id bigint auto_increment primary key,
name varchar(20),
sex tinyint not null default '0'
)engine=myisam default charset=utf8 auto_increment=1;
加入点数据:
insert into member(id,name,sex) values (1,'jacson','0');
insert into member(name,sex) select name,sex from member;
第二条语句多执行几次就有了很多数据。
2,下面我们进行分表:这里我们分两个表tb_member1,tb_member2

DROP table IF EXISTS tb_member1;
create table tb_member1(
id bigint primary key auto_increment ,
name varchar(20),
sex tinyint not null default '0'
)ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;
DROP table IF EXISTS tb_member2;
create table tb_member2(
id bigint primary key auto_increment ,
name varchar(20),
sex tinyint not null default '0'
)ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;
//创建tb_member2也可以用下面的语句 create table tb_member2 like tb_member1;
3,创建主表tb_member
DROP table IF EXISTS tb_member;
create table tb_member(
id bigint primary key auto_increment ,
name varchar(20),
sex tinyint not null default '0'
)ENGINE=MERGE UNION=(tb_member1,tb_member2) INSERT_METHOD=LAST CHARSET=utf8 AUTO_INCREMENT=1 ;
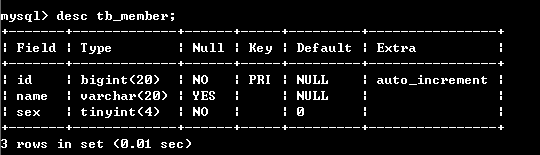
查看一下tb_member表的结构:desc tb_member;
4,接下来,我们把数据分到两个分表中去:
insert into tb_member1(id,name,sex) select id,name,sex from member where id%2=0;
insert into tb_member2(id,name,sex) select id,name,sex from member where id%2=1;
查看一下主表的数据:select * from tb_member;
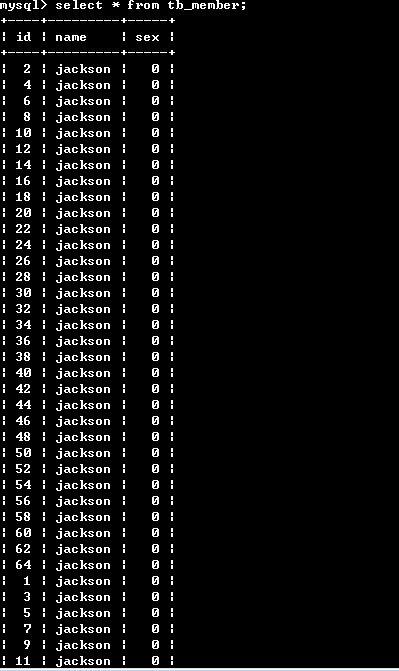
注意:总表只是一个外壳,存取数据发生在一个一个的分表里面。
ps:创建主表时可能会出现下面的错误:
ERROR 1168 (HY000): Unable to open underlying table which is differently defined
or of non-MyISAM type or doesn't exist
若遇到上面这种错误,一般从两方面来排查:(从这两方面一般可以解决这个问题,本人也遇到了。)
1,查看上面的分表数据库引擎是不是MyISAM.
2,查看分表与指标的字段定义是否一致。
分表的大概过程和步骤就是这样的,下面我们来看看分表的算法实现:
假设现在有一个应用系统可能会有100亿的用户量,另外一个表一般存储量在不超过100万的时候基本能保持良好性能,计算下来,我们需要1万张表,即分表为1万个表。
我们可以设计成:user_0~user_9999
在用户表里面我们有唯一的标示是用户id,我们尅设计一个小算法来实现用户id与访问表名的对应:
function getTable($id)
{
return 'user_'.sprintf('%d',($id >>20));
}
解释一下:($id >> 20)表示将向右移位20位,(向右移动一位标示减少一半),printf('%d',$data)标示将数据按照十进制输出。
即id为1~1048575(2的20次幂-1)时均访问user_0,1048576~2097152时访问user_1,以此类推.....
那么问题来了,如果用户更多怎么办,现在需要一个可扩展的方法:
而博客的浏览量,回复数等,类似的统计信息,或者别的变化频率比较高的数据,我们把它叫做活跃数据。
我们进行纵向分表后:
1,存储引擎的使用不同,冷数据使用MyIsam 可以有更好的查询数据。活跃数据,可以使用Innodb ,可以有更好的更新速度。
2,对冷数据进行更多的从库配置,因为更多的操作是查询,这样来加快查询速度。对热数据,可以相对有更多的主库的横向分表处理。
3,对于一些特殊的活跃数据,也可以考虑使用memcache ,redis之类的缓存,等累计到一定量再去更新数据库.
Mysql分表和分区的区别 转载自 https://blog.csdn.net/heirenheiren/article/details/7896546
Mysql分区 转载自: https://blog.csdn.net/vbirdbest/article/details/82461109
mysql数据库分区和分表的更多相关文章
- 什么是分表和分区 MySql数据库分区和分表方法
1.为什么要分表和分区 日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性 ...
- mysql数据库为什么要分表和分区?
一般下载的源码都带了MySQL数据库的,做个真正意义上的网站没数据库肯定不行. 数据库主要存放用户信息(注册用户名密码,分组,等级等),配置信息(管理权限配置,模板配置等),内容链接(html ,图片 ...
- mysql的分区和分表
分区 分区就是把一个数据表的文件和索引分散存储在不同的物理文件中. mysql支持的分区类型包括Range.List.Hash.Key,其中Range比较常用: RANGE分区:基于属于一个给定连续区 ...
- MySQL的分区、分表、集群
1.分区 mysql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看),一张表主要对应着三个文件,一个是frm存放表结构的,一 ...
- Mysql数据库进阶之(分表分库,主从分离)
前言:数据库的优化是一个程序员的分水岭,作为小白我也得去提前学习这方面的数据的 (一) 三范式和逆范式 听起范式这个迟非常专业我来举个简单的栗子: 第一范式就是: 把能够关联的每条数据都拆分成一个 ...
- 实现对MySQL数据库进行分库/分表备份(shell脚本)
工作中,往往数据库备份是件非常重要的事情,毕竟数据就是金钱,就是生命!废话不多,下面介绍一下:如何实现对MySQL数据库进行分库备份(shell脚本) Mysq数据库dump备份/还原语法: mysq ...
- MyCat:对MySQL数据库进行分库分表
本篇前提: mycat配置正确,且能正常启动. 1.schema.xml <table>标签: dataNode -- 分片节点指定(取值:dataNode中的name属性值) rule ...
- 12-2 MySQL数据库备份(分表)
#!/bin/bash source /etc/profile DATE="$(date +%F_%H-%M-%S)" DB_IP="172.16.1.122" ...
- Sharding与数据库分区(Partition) 分表、分库、分片和分区
Sharding与数据库分区(Partition) http://blog.sina.com.cn/s/blog_72ef7bea0101cjtb.html https://www.2cto.com/ ...
随机推荐
- 一则ORACLE进程都在但是无法进入实例的问题
[oracle@localhost ~]$ ps -ef|grep smonoracle 14809 1 0 Sep25 ? 00:13:02 ora_smon_mailp3[oracle@local ...
- C语言数据结构基础学习笔记——静态查找表
查找:在数据集合中寻找满足某种条件的数据元素的过程称为查找. 查找表:用于查找的数据集合称为查找表,一般有以下操作:①查找是否在表中:②查找属性:③进行操作. 查找表又分为: ①静态查找表:只可以进行 ...
- windows 与 mac socket通信
#include <Winsock2.h> #include <stdio.h> void main() { // 以下的几句都是固定的 WORD wVersionReques ...
- django Table doesn't exist
1146 django Table '' doesn't exist 一:出错原因 手动在数据库中drop了一张表,重新执行python manage.py migrate时出错,提示不存在这 ...
- iOS下 UILabel 如何自动换行
背景: 相信很多朋友都遇到过,文本的内容长度不一,需要根据内容的多少来自动换行处理. 场景: 很多APP中评论,有的评论长,有的评论短,有的一行,有的多行. 下面以评论的实现为例来说说具体如何实现 ...
- 记一次使用getRequestDispatcher遇到的坑。。响应页面出现新建下载任务
getRequestDispatcher RequestDispatcher接口提供将请求转发送到另一个资源的功能,它可能是html,servlet或jsp等. 此接口也可用于包括另一资源的内容.它是 ...
- JavaScript:鼠标拖拽效果
(之前的那个模板方法模式实在没搞懂...等几天再去研究8) 预览效果: 限制拖动范围在视口内.调整窗口时自动居中... <!DOCTYPE html> <html lang=&quo ...
- C# ConfigurationManager不存在问题解决
在做串口通信的时候,需要使用"ConfigurationManager"类,但是添加"Using System.Configuration"命名空间后编译器依旧 ...
- Tensorflow卷积神经网络[转]
Tensorflow卷积神经网络 卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络, 在计算机视觉等领域被广泛应用. 本文将简单介绍其原理并分析Te ...
- (转)php读取文件使用redis的pipeline导入大批量数据
第一次写博客,哈哈,纯属用来记录一下自己工作中遇到的问题及解决办法. 昨天因为工作的需求,需要做一个后台上传TXT文件,读取其中的内容,然后导入redis库中.要求速度快,并且支持至少10W以上的数据 ...