多标签分类(multi-label classification)综述
意义
网络新闻往往含有丰富的语义,一篇文章既可以属于“经济”也可以属于“文化”。给网络新闻打多标签可以更好地反应文章的真实意义,方便日后的分类和使用。
难点
(1)类标数量不确定,有些样本可能只有一个类标,有些样本的类标可能高达几十甚至上百个。
(2)类标之间相互依赖,例如包含蓝天类标的样本很大概率上包含白云,如何解决类标之间的依赖性问题也是一大难点。
(3)多标签的训练集比较难以获取。
方法
目前有很多关于多标签的学习算法,依据解决问题的角度,这些算法可以分为两大类:一是基于问题转化的方法,二是基于算法适用的方法。基于问题转化的方法是转化问题数据,使之使用现有算法;基于算法适用的方法是指针对某一特定的算法进行扩展,从而能够处理多标记数据,改进算法,适用数据。
基于问题转化的方法
基于问题转化的方法中有的考虑标签之间的关联性,有的不考虑标签的关联性。最简单的不考虑关联性的算法将多标签中的每一个标签当成是单标签,对每一个标签实施常见的分类算法。具体而言,在传统机器学习的模型中对每一类标签做二分类,可以使用SVM、DT、Naïve Bayes、DT、Xgboost等算法;在深度学习中,对每一类训练一个文本分类模型(如:textCNN、textRNN等)。考虑多标签的相关性时候可以将上一个输出的标签当成是下一个标签分类器的输入。在传统机器学习模型中可以使用分类器链[1],在这种情况下,第一个分类器只在输入数据上进行训练,然后每个分类器都在输入空间和链上的所有之前的分类器上进行训练。让我们试着通过一个例子来理解这个问题。在下面给出的数据集里,我们将X作为输入空间,而Y作为标签。在分类器链中,这个问题将被转换成4个不同的标签问题,就像下面所示。黄色部分是输入空间,白色部分代表目标变量。

在深度学习中,于输出层加上一个时序模型,将每一时刻输入的数据序列中加入上一时刻输出的结果值。以Chen[2]的论文为例,在获得文章的整体语义(Text feature vector)后,将Text feature vector输入到一个RNN的序列中作为初始值,每一时刻输入是上一时刻的输出。从某种程度上来说,图一所示的模型将 多标签任务当成了序列生成任务来处理。除此以外,Yang[3]的论文中也用生成模型来做多标签的分类任务。

除了将标签分开看之外,还有将标签统一来看(Label Powerset)。在这方面,我们将问题转化为一个多类问题,一个多类分类器在训练数据中发现的所有唯一的标签组合上被训练。让我们通过一个例子来理解它。
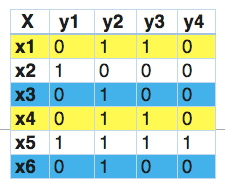
在这一点上,我们发现x1和x4有相同的标签。同样的,x3和x6有相同的标签。因此,标签powerset将这个问题转换为一个单一的多类问题,如下所示。

因此,标签powerset给训练集中的每一个可能的标签组合提供了一个独特的类。转化为单标签后就可以使用SVM、textCNN、textRNN等分类算法训练模型了。
感觉Label Powerset只适合标签数少的数据,一旦标签数目太多(假设有n个),使用Label Powerset后可能的数据集将分布在[0,2n-1]空间内,数据会很稀疏。
基于算法适用的方法
改编算法来直接执行多标签分类,而不是将问题转化为不同的问题子集。在传统机器学习模型中穿件的多标签分类模型有:kNN多标签版本MLkNN,SVM的多标签版本Rank-SVM等。在深度学习中常常是修改多分类模型的输出层,使其适用于多标签的分类,Mark J. Berger[4]在输出层对每一个标签的输出值使用sigmod函数进行2分类(标签之间无关联信息);Kurata在研究多标签分类时仍然使用了经典的CNN结构(如图2所示),不过在最后的全连接层的参数系数有些特别,也就是图2.1中Hidden layer到output layer的系数是经过特别设置的。
假设你总共有标签的个数为n(n=5)个,其分别是Λ=[λ1,λ2,λ3,λ4,,λ5,],假设共有两个样本,一个样本可能有标签为[λ1,λ4λ],另一个样本标签为[λ2,λ4,λ5],Hidden layer的单元个数假设为10个, Kurata把每个样本的标签作为一个标签共现模式(label co-occurrence pattern)有多少种不同的样本标签就有多少种不同的标签共现模式(样本可以无限很多,但是标签种类数最多有2n),然后对Hidden layer到output layer的权重参数进行设置(如下图2.2)。
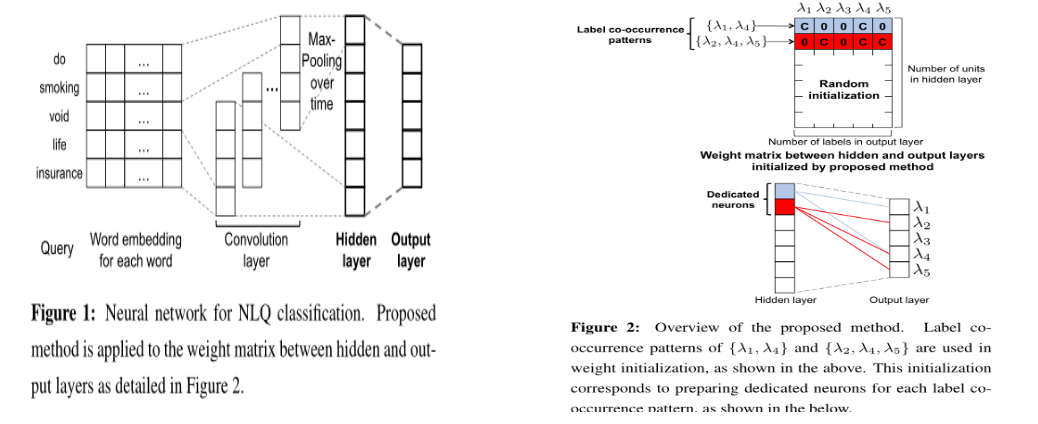
图2.1 XXXX 图2.2 XXX
James Mullenbach使用一般的CNN提取句子的语义信息,但考虑到句子表示的不同部分在句子分类的过程中会起不同的作用,故在进行分类时候使用了Attention机制(见图),使得在预测每一类时候句子的不同部分的表示起不同的作用。
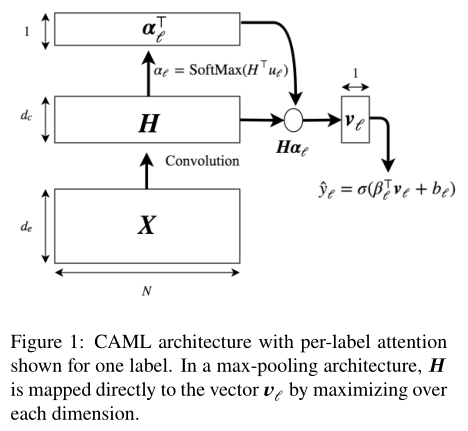
图3 XXXX
其他方法基本上大同小异,在此不再赘述。
现有可利用资源
3、2017知乎“看山杯”比赛(知乎问题多标签分类比赛,Github上面有代码)
4、https://drive.google.com/file/d/18-JOCIj9v5bZCrn9CIsk23W4wyhroCp_/view?usp=sharing(英文新闻多 标签分类数据集)
5、网上可采集的、质量较高的多标签分类数据集(豆瓣电影评论)
6、GitHub上比较完善的文本多标签分类项目
7、NLPCC2018,task6和tesk8均可以当成是多标签的分类任务;
[3] http://arxiv.org/pdf/1806.0482
[4] http://web.stanford.edu/class/cs224d/reports/BergerMark.pdf
多标签分类(multi-label classification)综述的更多相关文章
- keras multi-label classification 多标签分类
问题:一个数据又多个标签,一个样本数据多个类别中的某几类:比如一个病人的数据有多个疾病,一个文本有多种题材,所以标签就是: [1,0,0,0,1,0,1] 这种高维稀疏类型,如何计算分类准确率? 分类 ...
- 实战caffe多标签分类——汽车品牌与车辆外观(C++接口)[详细实现+数据集]
前言 很多地方我们都需要用到多标签分类,比如一张图片,上面有只蓝猫,另一张图片上面有一只黄狗,那么我们要识别的时候,就可以采用多标签分类这一思想了.任务一是识别出这个到底是猫还是狗?(类型)任务二是识 ...
- 使用 scikit-learn 实现多类别及多标签分类算法
多标签分类格式 对于多标签分类问题而言,一个样本可能同时属于多个类别.如一个新闻属于多个话题.这种情况下,因变量yy需要使用一个矩阵表达出来. 而多类别分类指的是y的可能取值大于2,但是y所属类别是唯 ...
- 从损失函数优化角度:讨论“线性回归(linear regression)”与”线性分类(linear classification)“的联系与区别
1. 主要观点 线性模型是线性回归和线性分类的基础 线性回归和线性分类模型的差异主要在于损失函数形式上,我们可以将其看做是线性模型在多维空间中“不同方向”和“不同位置”的两种表现形式 损失函数是一种优 ...
- CVPR2022 | 弱监督多标签分类中的损失问题
前言 本文提出了一种新的弱监督多标签分类(WSML)方法,该方法拒绝或纠正大损失样本,以防止模型记忆有噪声的标签.由于没有繁重和复杂的组件,提出的方法在几个部分标签设置(包括Pascal VOC 20 ...
- scikit-learn一般实例之八:多标签分类
本例模拟一个多标签文档分类问题.数据集基于下面的处理随机生成: 选取标签的数目:泊松(n~Poisson,n_labels) n次,选取类别C:多项式(c~Multinomial,theta) 选取文 ...
- CSS.02 -- 样式表 及标签分类(块、行、行内块元素)、CSS三大特性、背景属性
样式表书写位置 内嵌式写法 <head> <style type="text/css"> 样式表写法 </style> </head&g ...
- 前端 HTML 标签分类
三种: 1.块级标签: 独占一行,可设置宽度,高度.如果设置了宽度和高度,则就是当前的宽高.如果宽度和高度没有设置,宽度是父盒子的宽度,高度根据内容填充. 2.行内标签:在一行内显示,不能设置宽度,高 ...
- k-近邻算法 标签分类
k-近邻算法根据特征比较,然后提取样本集中特征最相似数据(最邻近)的分类标签.那么,如何进行比较呢? 怎么判断红色圆点标记的电影所属的类别呢? 如下图所示. 答:距离度量.这个电影分类的例子有2个特征 ...
随机推荐
- BZOJ 4004: [JLOI2015]装备购买 高斯消元解线性基
BZOJ严重卡精,要加 $long$ $double$ 才能过. 题意:求权和最小的极大线性无关组. 之前那个方法解的线性基都是基于二进制拆位的,这次不行,现在要求一个适用范围更广的方法. 考虑贪心 ...
- Confluence 6.15 修改历史(Change-History)宏
修改历史(Change-History)宏显示了页面一个的更新历史:版本号,作者,日期和备注.这些内容将会在同一栏中进行显示. 屏幕截图:Confluence 中的修改历史(Change-Histor ...
- UBUNTU 15.10 CAFFE安装教程(测试可用)
转帖:https://github.com/BVLC/caffe/wiki/Ubuntu-15.10-Installation-Guide Ubuntu 15.10 have been release ...
- 卸载brew
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/uninst ...
- luogu4212
P4212 外太空旅行 题目描述 在人类的触角伸向银河系的边缘之际,普通人上太空旅行已经变得稀松平常了.某理科试验班有n个人,现在班主任要从中选出尽量多的人去参加一次太空旅行活动. 可是n名同学并不是 ...
- [spring cloud] [error] java.lang.IllegalStateException: Only one connection receive subscriber allowed.
前言 最近在开发api-gateway的时候遇到了一个问题,网上能够找到的解决方案也很少,之后由公司的大佬解决了这个问题.写下这篇文章记录一下解决方案.希望可以帮助到更多的人. 环境 java版本:8 ...
- 用 Docker 搭建 ORACLE 数据库开发环境
用 Docker 搭建 ORACLE 数据库开发环境 需要安装 ORACLE 数据库做开发,直接安装的话因为各类平台的限制,非常复杂,会遇到很多问题. 还好,现在有 Docker 化的部署方式,省去很 ...
- C++入门经典-例8.7-多态,利用虚函数实现动态绑定
1:多态性是面向对象程序设计的一个重要特征,利用多态性可以设计和实现一个易于扩展的系统.在C++语言中,多态是指具有不同功能的函数可以用同一个函数名,这样就可以用一个函数名调用不同内容的函数,发出同样 ...
- SpringMVC @ResponseBody返回中文乱码
SpringMVC的@ResponseBody返回中文乱码的原因是SpringMVC默认处理的字符集是ISO-8859-1, 在Spring的org.springframework.http.conv ...
- python3.*之列表常用操作
首先定义一个列表:names= ["xiaoming","xiaogang","xiaomei","xiaohong"] ...