Mapreduce-实现webcount代码
参考博文:https://blog.csdn.net/qq_41035588/article/details/90514824
首先安装一个Hadoop-Eclipse-Plugin 方便来对于hdfs进行管理
参考地址:http://dblab.xmu.edu.cn/blog/hadoop-build-project-using-eclipse/
配置好Hadoop-Ecllipse-Plugin之后
建立一个txt文档,里面的内容如下:
买家id 商品id 收藏日期
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
-- ::
然后建立一个java项目
然后把所有的包都导进去,重点是mapreduce,common,yarn,hdfs的包
然后再输入代码:
package mapreduce; import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class doMapper extends Mapper<Object, Text, Text, IntWritable>{
//第一个object表示输入key的类型,第二个text表示输入value的类型;第三个text表示输出建的类型;
//第四个INtWritable表示输出值的类型 public static final IntWritable one = new IntWritable(1);
public static Text word = new Text();
@Override
protected void map(Object key, Text value, Context context)
//key value是输入的key value context是记录输入的key,value
throws IOException, InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(value.toString(), "\t");
//StringTokenizer是Java的工具包中的一个类,用于将字符串进行拆分
word.set(tokenizer.nextToken());
//返回当前位置到下一个分隔符之间的字符串
context.write(word, one);
//讲word存到容器中计一个数
}
}
public static class doReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
//输入键类型,输入值类型 输出建类型,输出值类型
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance();
job.setJobName("WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(doMapper.class);
job.setReducerClass(doReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path in = new Path("hdfs://localhost:9000/mymapreduce1/in/buyer_favorite1");
Path out = new Path("hdfs://localhost:9000/mymapreduce1/out");
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
然后运行之后查看左边的菜单:
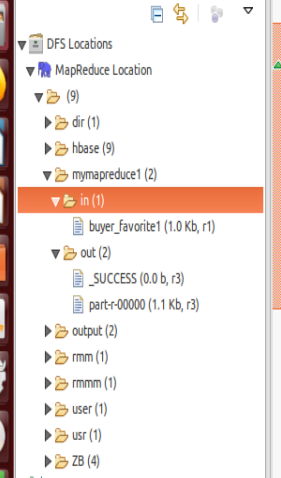
双击part-r-00000就有返回的值了

最重要的问题就是分隔的问题
- StringTokenizer tokenizer = new StringTokenizer(value.toString(),"\t");
这个是根据tab键来进行分割,但是我们复制粘贴后就是空格所以要换成空格
Mapreduce-实现webcount代码的更多相关文章
- MapReduce框架结构及代码示例
一个完整的 mapreduce 程序在分布式运行时有三类实例进程: 1.MRAppMaster:负责整个程序的过程调度及状态协调 2.MapTask:负责 map 阶段的整个数据处理流程 3.Redu ...
- [大牛翻译系列]Hadoop(15)MapReduce 性能调优:优化MapReduce的用户JAVA代码
6.4.5 优化MapReduce用户JAVA代码 MapReduce执行代码的方式和普通JAVA应用不同.这是由于MapReduce框架为了能够高效地处理海量数据,需要成百万次调用map和reduc ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- MapReduce工作流多种实现方式
学习 hadoop,必不可少的就是编写 MapReduce 程序.当然,对于简单的分析程序,我们只需一个 MapReduce 任务就能搞定,然而对于比较复杂的分析程序,我们可能需要多个Job或者多个M ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- [大牛翻译系列]Hadoop(19)MapReduce 文件处理:基于压缩的高效存储(二)
5.2 基于压缩的高效存储(续) (仅包括技术27) 技术27 在MapReduce,Hive和Pig中使用可分块的LZOP 如果一个文本文件即使经过压缩后仍然比HDFS的块的大小要大,就需要考虑选择 ...
- MapReduce链接作业
对于简单的分析程序,我们只需一个MapReduce就能搞定,然而对于比较复杂的分析程序,我们可能需要多个Job或者多个Map或者Reduce进行计算.下面我们来说说多个Job或者多个MapReduce ...
- 十九、Hadoop学记笔记————Hbase和MapReduce
概要: hadoop和hbase导入环境变量: 要运行Hbase中自带的MapReduce程序,需要运行如下指令,可在官网中找到: 如果遇到如下问题,则说明Hadoop的MapReduce没有权限访问 ...
- 从分治算法到 Hadoop MapReduce
从分治算法说起 要说 Hadoop MapReduce 就不得不说分治算法,而分治算法其实说白了,就是四个字 分而治之 .其实就是将一个复杂的问题分解成多组相同或类似的子问题,对这些子问题再分,然后再 ...
随机推荐
- 本地虚拟机NAT模式下怎么设置才可以访问外网
记:因为我要在本机虚拟机上安装Docker,结果发现虚拟机环境不能上网,是主机模式.我要调成net模式下才可以访问外网,这就需要怎么设置.下面文章记录一下. 在本机安装VMware软件后,系统中会自动 ...
- DRF框架中链表数据通过ModelSerializer深度查询方法汇总
DRF框架中链表数据通过ModelSerializer深度查询方法汇总 一.准备测试和理解准备 创建类 class Test1(models.Model): id = models.IntegerFi ...
- 你不知道的javascript(上卷)读后感(一)
三剑客 编译,顾名思义,就是源代码执行前会经历的过程,分三个步骤, 分词/词法分析,将我们写的代码字符串分解成多个词法单元 解析/语法分析,将词法单元集合生成抽象语法树(AST) 代码生成,抽象语法树 ...
- ASE19 团队项目 alpha 阶段 Frontend 组 scrum9 记录
本次会议于11月14日,11:30 在微软北京西二号楼13158,持续15分钟. 与会人员:Jingyi Xie, Jiaqi Xu, Jingwei Yi, Hanyue Tu 请假: Ziwei ...
- golang GC(一 原理)
golang中的gc采用三色标记法.在讲三色标记法之前,先了解一下Mark and Sweep算法,因为Mark and Sweep算法是三个标记法的一个改进版. Mark and Sweep算法: ...
- 【OGG 故障处理】OGG-01031
故障原因 -------------------- 网络异常,导致DP进程异常中断 故障现象 -------------------- 源端DP 进程全部挂起,且启动失败 GGSCI 34> ...
- 虚拟机mysql报错的问题
Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (111)解决方法 登陆mysql的时 ...
- Django:总结setting中的配置
一.Django setting配置说明 二.setting配置一览 一.Django setting配置说明 1.基础 DJANGO_SETTING_MODULE环境变量:让settings模块被包 ...
- java之数据结构与算法
1.了解基本数据结构及特点 如,有哪些二叉树,各有什么特点 树二叉搜索树 每个节点都包含一个值,每个节点至多有两棵子树,左孩子小于自己,右孩子大于自己,时间复杂度是O(log(n)),随着不断插入节点 ...
- WPF使用转换器(Converter)
1.作用:可以将源数据和目标数据之间进行特定的转化, 2.定义转换器,需要继承接口IValueConverter [ValueConversion(typeof(int), typeof(string ...