Java 之 HashMap 集合
一、HashMap 概述
java.util.HashMap<k,v> 集合 implements Map<k,v> 接口
HashMap 集合的特点:
1、HashMap 集合底层是哈希表:查询速度特别的快
JDK 1.8 之前:数组+单向链表
JDK 1.8 之后:数组+单向链表 | 红黑树(链表的长度超过8):提高查询的速度
2、HashMap 集合是一个无序的集合,存储元素和取出元素的顺序有可能不一致
二、HashMap 存储自定义类型键值
HashMap存储自定义类型键值
Map集合保证key是唯一的:作为key的元素,必须重写hashCode方法和equals方法,以保证key唯一
三、遍历集合
参考 Map 集合的遍历方式:Map 遍历
四、Hashmap 源码分析
1、hashCode 值
hash算法是一种可以从任何数据中提取出其“指纹”的数据摘要算法,它将任意大小的数据映射到一个固定大小的序列上,这个序列被称为hash code、数据摘要或者指纹。比较出名的hash算法有MD5、SHA。hash是具有唯一性且不可逆的,唯一性是指相同的“对象”产生的hash code永远是一样的。

2、Entry 数组
HashMap和Hashtable是散列表,其中维护了一个长度为2的幂次方的Entry类型的数组table,数组的每一个元素被称为一个桶(bucket),你添加的映射关系(key,value)最终都被封装为一个Map.Entry类型的对象,放到了某个table[index]桶中。
使用数组的目的是查询和添加的效率高,可以根据索引直接定位到某个table[index]。
(1)数组元素类型: Map.Entry

(2)初始容量:16

(3)扩容为原来的2倍

(4)那么 HashMap 是如何决定某个映射关系存在哪个桶的呢?
因为hash code是一个整数,而数组的长度也是一个整数,有两种思路:
①hash code值 % table.length会得到一个[0,table.length-1]范围的值,正好是下标范围,但是用%运算,不能保证均匀存放,可能会导致某些table[index]桶中的元素太多,而另一些太少,因此不合适。
②hash code值 & (table.length-1),因为table.length是2的幂次方,因此table.length-1是一个二进制低位全是1的数,所以&操作完,也会得到一个[0,table.length-1]范围的值。


3、HashMap 中的散列函数 hash()
JDK1.7和JDK1.8关于hash()的实现代码不一样,但是不管怎么样都是为了提高hash code值与 (table.length-1)的按位与完的结果,尽量的均匀分布。

这里用 JDK1.8 的实例分析一下:

思考:那么,JDK1.8为什么要保留高16位呢?
因为一个HashMap的table数组一般不会特别大,至少在不断扩容之前,那么table.length-1的大部分高位都是0,直接用hashCode和table.length-1进行&运算的话,就会导致总是只有最低的几位是有效的,那么就算你的hashCode()实现的再好也难以避免发生碰撞,这时保留高16位的意义就体现出来了。它对hashcode的低位添加了随机性并且混合了高位的部分特征,显著减少了碰撞冲突的发生。
4、如何解决冲突?
虽然从设计hashCode()到上面HashMap的hash()函数,都尽量减少冲突,但是仍然存在两个不同的对象返回的hashCode值相同,或者hashCode值就算不同,通过hash()函数计算后,得到的index也会存在大量的相同,因此key分布完全均匀的情况是不存在的。那么发生碰撞冲突时怎么办?
JDK1.8之间使用:数组+链表的结构。
JDK1.8之后使用:数组+链表/红黑树的结构。


5、JDK1.7里HashMap 中几个常量与变量是什么?
(1)默认数组容量

(2)默认加载因子

思考: loadFactor 设置为 0.1 与 0.9 有什么区别?
当 loadFactor 为 0.1 时,扩容太频繁
当 loadFactor 为 0.9时,会导致 table[index] 下面的链表会很长,查询速度会降低。
(3)加载因子

(4)阈值(临界值)

6、JDK 1.6 中HashMap 的构造方法是怎么样的?
图1
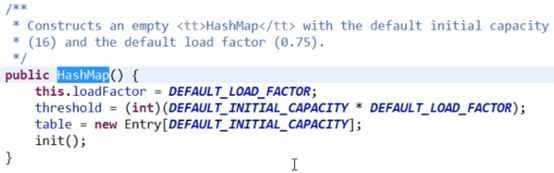
图2

可以看出 JDK1.6 中 table 数组初始化为了一个长度为 16 的空数组,默认加载因子为0.75,阈值为12。
6、JDK 1.7 中的 HashMap 的构造方法是怎么样的?
图1

图2
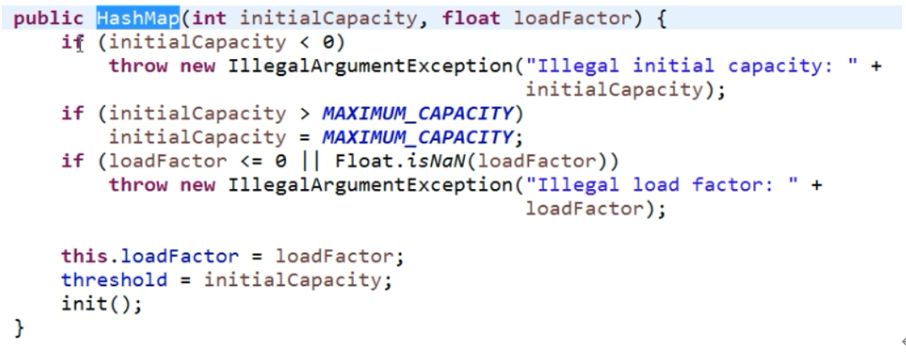
图3
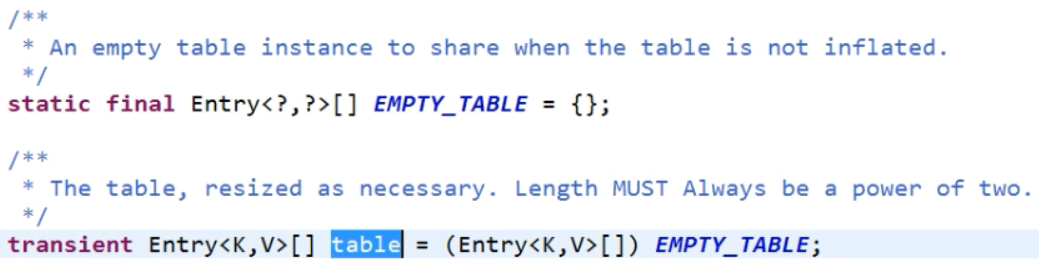
可以从无参构造中看出,调用了有参的构造,但是有参的构造方法中并没有做什么,但是从上面的图三可以看出 table 数组初始化为了一个长度为0的长度为0的数组。
7、JDK 1.8 中的 HashMap 的构造方法
8、JDK 1.7 中的 put 方法
源码分析:


执行步骤:
(1)先判断table是否为空数组,如果是,先初始化长度为16的Entry 类型的数组,并且把threshold计算为12;
这里如果你手动指定了数组的capacity,那么如果这个capacity不是2的n次方,会自动纠正为2的n次方;
(2)如果key是null,特殊对待,key为null的映射关系的hash值为0,index也为0;
(3)key 不是 null,那么先计算hash(key)获得 hash 值
(4)再通过处理过的hash值&(table.length-1)计算index,决定是在table[index],index在[0,table.length-1]范围内;
(5)判断table[index]桶下是否存在某个Entry的key与新的key的“相同”(hash值相同并且(满足key的地址相同或key的equals返回true)),如果是,用新的value替换原来的value;
(6)如果不存在,判断是否满足size达到阈值(threshold)并且table[index]不是null,如果是,先扩容;扩容会导致原来table中的所有元素都会重新计算位置,并调整存储位置;
(7)添加一个新的Entry对象至table[index](注意,这个index也是重新计算过的)中,并且把当前table[index]下的所有元素都连接到新的Entry的next下。
(8)size++,元素个数增加
思考:
1、为什么要把数组的长度纠正为2的n次方?
① 后面算index = hash & table.length-1,这样才能保证[0,table.length-1]范围内
② 2的次方,根据它的散列算法,可以保证比较均匀的分散在它的数组的各个位置
2、扩容的条件是什么?
① size达到阈值threshold
② table[index]下面已经有映射关系,即不为空
9、JDK 1.8 中常量与变量
(1)DEFAULT_INITIAL_CAPACITY:默认的初始容量 16
(2)MAXIMUM_CAPACITY:最大容量 1 << 30
(3)static final float DEFAULT_LOAD_FACTOR = 0.75:默认加载因子 0.75
(4)static final int TREEIFY_THRESHOLD = 8; 默认树化阈值8,该阈值的作用是判断是否需要树化,树化的目的是为了提高查询效率;当某个链表的结点个数达到这个值时,可能会导致树化
(5)static final int MIN_TREEIFY_CAPACITY = 64;最小树化容量64,当某个链表的结点个数达到8时,还要检查table的长度是否达到64,如果没有达到,先扩容解决冲突问题
(6)static final int UNTREEIFY_THRESHOLD = 6;默认反树化阈值6,当删除了结点时,如果某棵红黑树的结点个数已经低于该值时,会把树重新变成链表,目的是减少复杂度
(7)Node<K,V>[] table:数组
(8)int size:记录有效映射关系的对数,也是Entry对象的个数
(9)int threshold:阈值,当size达到阈值时,考虑扩容
(10)double loadFactor:加载因子,影响扩容的频率
10、JDK 1.8 的 put 方法
11、
12、
Java 之 HashMap 集合的更多相关文章
- JAVA之HashMap集合
/** * HashMap集合讲解 * HashMap集合不允许集合元素的Key重复 */package com.test; import java.util.*; public class test ...
- java中HashMap集合的常用方法
public Object clone() 返回hashMap集合的副本 其余的方法都是实现Map集合的 https://www.cnblogs.com/xiaostudy/p/9510763.htm ...
- JAVA双列集合HashMap
HashMap 双列集合HashMap是属于java集合框架3大类接口的Map类, Map接口储存一组成对的键-值对象,提供key(键)到value(值)的映射.Map中的key不要求有序,不允许 ...
- Java基础知识强化之集合框架笔记57:Map集合之HashMap集合(HashMap<Student,String>)的案例
1. HashMap集合(HashMap<Student,String>)的案例 HashMap<Student,String>键:Student 要求:如果两个对象 ...
- Java基础知识强化之集合框架笔记56:Map集合之HashMap集合(HashMap<String,Student>)的案例
1. HashMap集合(HashMap<String,Student>)的案例 HashMap是最常用的Map集合,它的键值对在存储时要根据键的哈希码来确定值放在哪里. HashMap的 ...
- Java基础知识强化之集合框架笔记55:Map集合之HashMap集合(HashMap<Integer,String>)的案例
1. HashMap集合(键是Integer,值是String的案例) 2. 代码示例: package cn.itcast_02; import java.util.HashMap; import ...
- Java基础知识强化之集合框架笔记54:Map集合之HashMap集合(HashMap<String,String>)的案例
1. HashMap集合 HashMap集合(HashMap<String,String>)的案例 2. 代码示例: package cn.itcast_02; import java.u ...
- java集合(2)- java中HashMap详解
java中HashMap详解 基于哈希表的 Map 接口的实现.此实现提供所有可选的映射操作,并允许使用 null 值和 null 键.(除了非同步和允许使用 null 之外,HashMap 类与 H ...
- JAVA基础学习-集合三-Map、HashMap,TreeMap与常用API
森林森 一份耕耘,一份收获 博客园 首页 新随笔 联系 管理 订阅 随笔- 397 文章- 0 评论- 78 JAVA基础学习day16--集合三-Map.HashMap,TreeMap与常用A ...
随机推荐
- Expression: __acrt_first_block == header
File: minkernel\crts\ucrt\src\appcrt\heap\debug_heap.cpp Line: 996 Expression: __acrt_first_block == ...
- osg::Camera 参数修改
#ifdef _WIN32 #include <Windows.h> #endif // _WIN32 #include<iostream> #include <osgV ...
- 123457---com.threeObj.Baobaoshizi01--- 宝宝识字01
com.threeObj.Baobaoshizi01--- 宝宝识字01
- 【Leetcode_easy】653. Two Sum IV - Input is a BST
problem 653. Two Sum IV - Input is a BST 参考 1. Leetcode_easy_653. Two Sum IV - Input is a BST; 完
- SMAP数据产品介绍与下载方法
1 SMAP(Soil Moisture Active and Passive)数据介绍 SMAP baseline science data products在下面的表格中展示,这些数据产品可以从两 ...
- 【C/C++开发】C++队列缓存的实现
C++队列缓存的实现 为什么使用队列缓存 c++的队列缓存主要用于解决大数据量并发时的数据存储问题,可以将并发时的数据缓存到队列中,当数据量变小时再匀速写入硬盘中. 引用queue队列 在头文件中引用 ...
- 最新 海看java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.海看等10家互联网公司的校招Offer,因为某些自身原因最终选择了海看.6.7月主要是做系统复习.项目复盘.LeetCode ...
- yarn和npm
Yarn和npm命令对比 npm install === yarn npm install taco --save === yarn add taco npm uninstall taco --sav ...
- 说一说Unsafe魔法类
这篇算是对 Unsafe 的一个总体概况,由于内容实在太多,后续会分开几篇文章对里面内容展开细讲 前言 Unsafe可以说是java的后门,类似西游记中的如来佛祖法力无边,Unsafe主要提供一些用于 ...
- v-radio
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...