Tushare金融大数据入门
Tushare金融大数据社区,是一个免费提供各类金融数据和区块链数据的平台 ,旨在助力智能投资与创新型投资。
- 积分
数据千万条,积分第一条
目前,提供的数据包含股票、基金、期货、债券、外汇、行业大数据,以及数字货币行情等区块链数据的全数据品类的金融大数据平台,这些数据在用户积分满足的情况下,统统都免费。因为,积分极度容易获取的原因,所以基本上可以算作免费。
不过,其中还是有部分数据会有些限制,好在大部分的数据,只要120积分就可以有权限调用,但是在权限会有所限制,积分越多,调取的速度越快。这个也理解,毕竟是免费调取,服务器租用等还是有成本的,调取数据的人那么多,根据贡献大小进行排序也无可厚非。
例如财务方面数据,则最低要求500积分:
提示:当前接口只能按单只股票获取其历史数据,如果需要获取某一季度全部上市公司数据,请使用income_vip接口(参数一致),需积攒5000积分。
个股资金流向:用户需要至少1500积分才可以调取,基础积分有流量控制,积分越多权限越大
所以,我们需要努力的挣取积分,那么作为普通的码农来说,挣取积分的方式总共有几种呢?
第一种方式:注册账号+修改个人真实资料,斩获120积分
第二种方式:推广,成功推荐一个有效用户,奖励50积分,例如:https://tushare.pro/register?reg=258045
第三种方式:推广,在自己博客或者互联网论坛,发表Tushare相关用途的文章,例如本篇文章,根据文章质量奖励100-1000分。真不知道1000分的文章是什么样的,好期待看看。
),并在社区群中帮助解答群友的问题。(感觉这个很难定义呀,我在群里也挺活跃的,但是也没加分)
第五种方式:捐钱,50RMB=500积分。目前,如果要满足高速获取财报数据的5000积分要求,只要500大洋就足够了。有钱任性!
有积分了,那么我们就可以调用这些接口了,好开心o(* ̄▽ ̄*)ブ
- 接口
积分有了,那么我们便可以开始调用可爱的数据宝宝了。
Tushare在接口上还是非常友好的,它一共提供了四种方式,分别为:
- 通过HTTP获取数据
- 通过Python SDK获取数据
- 通过Matlab SDK获取数据
- 通过R SDK获取数据
在这里,我主要说一下通过Python SDK获取数据以及如何将数据存储到数据库中。
那么,为什么要使用Python来进行获取数据呢?主要还是因为Python中用于数据分析Anaconda的包非常全,而且调用很简单。当然,更重要的原因是,我想多学一门语言,正好可以趁着有个练手的项目,一边犯错一边掌握。
闲话少说,言归正传。
既然要用Python做开发,那么IDE必不可少,好在Tushare早有准备,大家直接打开Tushare的官网,下拉到“相关工具”,你需要的一切都在这里:
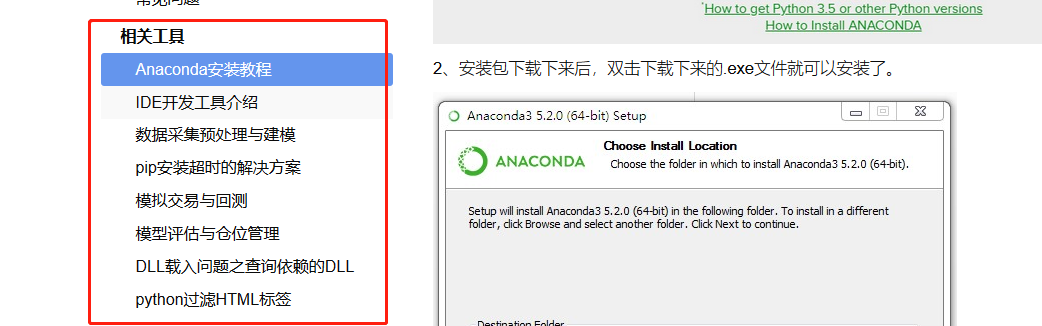
- 其他相关
1、对于新手来说,可以多关注一下Tushare作者“米哥”的公众号waditu,里面时不时会有米哥发表的干货,是他在做这个平台时遇到的某些问题的解决方案,大家可以参考参考。
2、对于新手来说,可以逮着一本书就好好学习,我建议可以看看菜鸟教程Python100题,做完基本上问题不大,可以处理简单的业务逻辑。
3、如果还想更深入的学习,可以试试这本书 Python数据科学手册 ,这本书,看完了记得告诉我怎么样,链接: https://pan.baidu.com/s/1o4G4GvIbe8QA10U4dYkRxQ 提取码: 2889 复制这段内容后打开百度网盘手机App,操作更方便哦
Tushare金融大数据入门的更多相关文章
- 个人永久性免费-Excel催化剂功能第98波-零代码零距离轻松接触并拥有金融大数据
数据产生价值的一个最突出的领域-金融领域,股票.证券.上市公司财务报表等,多少人在其中发掘出宝贵的数据价值.今天Excel催化剂联合Tushare金融大数据平台,让这一切的数据都能成为你我普通人零代码 ...
- Excel催化剂开源第42波-与金融大数据TuShare对接实现零门槛零代码获取数据
在金融大数据功能中,使用了TuShare的数据接口,其所有接口都采用WebAPI的方式提供,本来还在纠结着应该搬那些数据接口给用户使用,后来发现,所有数据接口都有其通用性,结合Excel灵活友好的输入 ...
- Data.gov.uk电子政务云,牛津大学NIE金融大数据实验室王宁:数据治理的现状和实践
牛津大学NIE金融大数据实验室王宁:数据治理的现状和实践 我是牛津互联网研究院的研究员,是英国开放互联网的一个主要的研究机构和相关政策制订的一个机构.今天主要给大家介绍一下英国数据治理的一些现状和实践 ...
- 大数据入门基础系列之Hadoop1.X、Hadoop2.X和Hadoop3.X的多维度区别详解(博主推荐)
不多说,直接上干货! 在前面的博文里,我已经介绍了 大数据入门基础系列之Linux操作系统简介与选择 大数据入门基础系列之虚拟机的下载.安装详解 大数据入门基础系列之Linux的安装详解 大数据入门基 ...
- 大数据入门:Hadoop安装、环境配置及检测
目录 1.导包Hadoop包 2.配置环境变量 3.把winutil包拷贝到Hadoop bin目录下 4.把Hadoop.dll放到system32下 5.检测Hadoop是否正常安装 5.1在ma ...
- 大数据入门第二十五天——elasticsearch入门
一.概述 推荐路神的ES权威指南翻译:https://es.xiaoleilu.com/010_Intro/00_README.html 官网:https://www.elastic.co/cn/pr ...
- 大数据入门第二十二天——spark(一)入门与安装
一.概述 1.什么是spark 从官网http://spark.apache.org/可以得知: Apache Spark™ is a fast and general engine for larg ...
- 大数据入门第六天——HDFS详解
一.概述 1.HDFS中的角色 Block数据: HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是 ...
- Java 程序员的大数据入门指南
项目 GitHub 地址:https://github.com/heibaiying/BigData-Notes ✒️ 前 言 大数据常用技术栈思维导图 大数据常用软件安装指南 一.Hadoop 分布 ...
随机推荐
- angular流程引擎集成
工作流在oa和erp中十分常见,现有成熟的工作流通常是在客户端实现的,web实现工作流的案例十分稀少.要实现web工作流必须要有强大的流程设计器,这里为大家介绍一款基于angular的流程控件,其功能 ...
- 执行sudo pip3 ...报错 Traceback (most recent call last): File "/usr/bin/pip3", line 9, in <module> from pip import main ImportError: cannot import name 'main'
对于普通pip,把pip3改成pip即可,其他的修改一样 1.执行命令 sudo gedit /usr/bin/pip3 2.改成下面的形式 from pip import __main__ # 需要 ...
- IE8"HTML Parsing Error:Unable to modify the parent container element before the child element is closed"错误
一.IE8报下面错误,解决办法:网页错误详细信息消息: HTML Parsing Error: Unable to modify the parent container element before ...
- 最简单之安装hadoop单机版
一,hadoop下载 (前提:先安装java环境) 下载地址:http://hadoop.apache.org/releases.html(注意是binary文件,source那个是源码) 二,解压配 ...
- loj2425 「NOIP2015」运输计划[二分答案+树上差分]
看到题意最小化最长路径,显然二分答案,枚举链长度不超过$\text{mid}$,然后尝试检验.````` 检验是否存在这样一个边置为0后,全部链长$\le\text{mid}$,其最终目标就是.要让所 ...
- Win7 右键 新建图标消失的解决办法
方法一: 把下面一段代码存在一个记事本上,再选择另存为1.cmd,最后运行! regsvr32 /u /s igfxpph.dll reg delete HKEY_CLASSES_ROOT\Direc ...
- c++两数组合并算法
#include <iostream> #define MAXSIZE 100 using namespace std; int combine(int a[],int b[],int c ...
- Spring Boot教程(四十一)LDAP来管理用户信息(1)
LDAP简介 LDAP(轻量级目录访问协议,Lightweight Directory Access Protocol)是实现提供被称为目录服务的信息服务.目录服务是一种特殊的数据库系统,其专门针对读 ...
- Xshell远程连接的具体操作和Xshell多会话设置小技巧
前几天给大家分享了Xshell的安装教程,今天给大家分享如何在Xshell中进行远程连接,并且分享一下如何设置一条命令可以发送多个终端,这里以Xshell6为例进行说明,具体的教程如下. 1.依次点击 ...
- [CSP-S模拟测试]:C(三分+贪心)
题目传送门(内部题46) 输入格式 第一行$3$个整数$n,m,t$.第二行$n$个整数,表示$P_i$.接下来$m$行每行两个整数,表示$L_i,R_i$. 输出格式 一行一个整数表示答案. 样例 ...