Understanding matrix factorization for recommendation
http://nicolas-hug.com/blog/matrix_facto_4
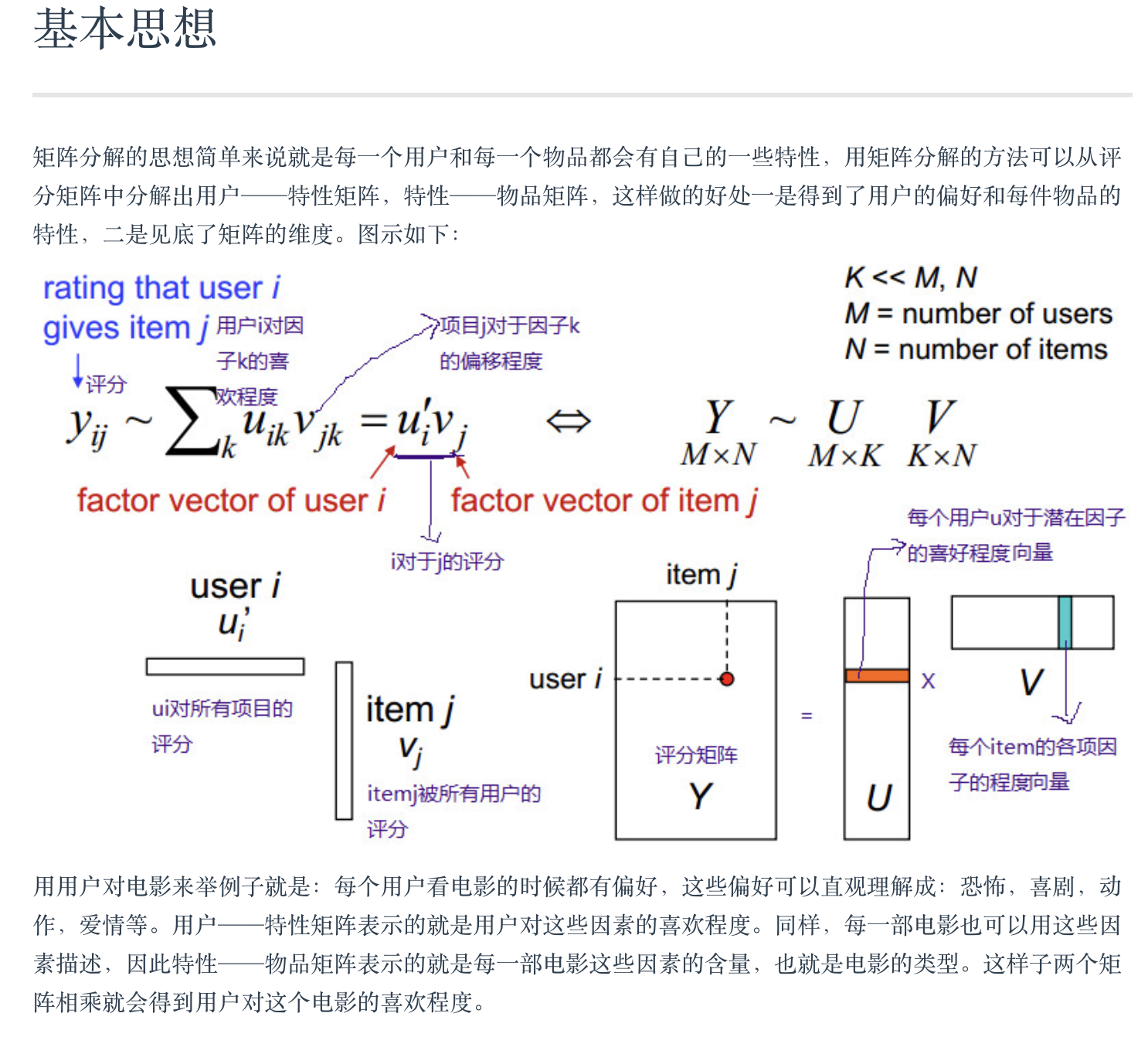
import numpy as np
import surprise # run 'pip install scikit-surprise' to install surprise
from surprise.model_selection import cross_validate
class MatrixFacto(surprise.AlgoBase):
'''A basic rating prediction algorithm based on matrix factorization.'''
def __init__(self, learning_rate, n_epochs, n_factors):
self.lr = learning_rate # learning rate for SGD
self.n_epochs = n_epochs # number of iterations of SGD
self.n_factors = n_factors # number of factors
def fit(self, trainset):
'''Learn the vectors p_u and q_i with SGD'''
print('Fitting data with SGD...')
# Randomly initialize the user and item factors.
p = np.random.normal(0, .1, (trainset.n_users, self.n_factors))
q = np.random.normal(0, .1, (trainset.n_items, self.n_factors))
# SGD procedure
for _ in range(self.n_epochs):
for u, i, r_ui in trainset.all_ratings():
err = r_ui - np.dot(p[u], q[i])
# Update vectors p_u and q_i
p[u] += self.lr * err * q[i]
q[i] += self.lr * err * p[u]
# Note: in the update of q_i, we should actually use the previous (non-updated) value of p_u.
# In practice it makes almost no difference.
self.p, self.q = p, q
self.trainset = trainset
def estimate(self, u, i):
'''Return the estmimated rating of user u for item i.'''
# return scalar product between p_u and q_i if user and item are known,
# else return the average of all ratings
if self.trainset.knows_user(u) and self.trainset.knows_item(i):
return np.dot(self.p[u], self.q[i])
else:
return self.trainset.global_mean
# data loading. We'll use the movielens dataset (https://grouplens.org/datasets/movielens/100k/)
# it will be downloaded automatically.
data = surprise.Dataset.load_builtin('ml-100k')
#data.split(2) # split data for 2-folds cross validation
algo = MatrixFacto(learning_rate=.01, n_epochs=10, n_factors=10)
#surprise.evaluate(algo, data, measures=['RMSE'])
cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
Understanding matrix factorization for recommendation的更多相关文章
- Matrix Factorization SVD 矩阵分解
Today we have learned the Matrix Factorization, and I want to record my study notes. Some kownledge ...
- 关于NMF(Non-negative Matrix Factorization )
著名的科学杂志<Nature>于1999年刊登了两位科学家D.D.Lee和H.S.Seung对数学中非负矩阵研究的突出成果.该文提出了一种新的矩阵分解思想――非负矩阵分解(Non-nega ...
- Matrix Factorization, Algorithms, Applications, and Avaliable packages
矩阵分解 来源:http://www.cvchina.info/2011/09/05/matrix-factorization-jungle/ 美帝的有心人士收集了市面上的矩阵分解的差点儿全部算法和应 ...
- 机器学习技法:15 Matrix Factorization
Roadmap Linear Network Hypothesis Basic Matrix Factorization Stochastic Gradient Descent Summary of ...
- 《Non-Negative Matrix Factorization for Polyphonic Music Transcription》译文
NMF(非负矩阵分解),由于其分解出的矩阵是非负的,在一些实际问题中具有非常好的解释,因此用途很广.在此,我给大家介绍一下NMF在多声部音乐中的应用.要翻译的论文是利用NMF转录多声部音乐的开山之作, ...
- 机器学习技法笔记:15 Matrix Factorization
Roadmap Linear Network Hypothesis Basic Matrix Factorization Stochastic Gradient Descent Summary of ...
- Non-negative Matrix Factorization 非负矩阵分解
著名的科学杂志<Nature>于1999年刊登了两位科学家D.D.Lee和H.S.Seung对数学中非负矩阵研究的突出成果.该文提出了一种新的矩阵分解思想――非负矩阵分解(Non-nega ...
- 【RS】Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering - 基于拉普拉斯分布的稀疏概率矩阵分解协同过滤
[论文标题]Sparse Probabilistic Matrix Factorization by Laplace Distribution for Collaborative Filtering ...
- 【RS】List-wise learning to rank with matrix factorization for collaborative filtering - 结合列表启发排序和矩阵分解的协同过滤
[论文标题]List-wise learning to rank with matrix factorization for collaborative filtering (RecSys '10 ...
随机推荐
- 兔子问题(Rabbit problem)
Description 有一种兔子,出生后一个月就可以长大,然后再过一个月一对长大的兔子就可以生育一对小兔子且以后每个月都能生育一对.现在,我们有一对刚出生的这种兔子,那么,n 个月过后,我们会有多少 ...
- ding
Import "shanhai.lua"Dim currHour,currMinute,currSecondDim mmRnd = 0Dim sumFor=Int(ReadUICo ...
- [Oracle] - 使用32位 PLSQL(PL/SQL Developer)登陆64位Oracle失败之解决
配置环境 Oracle服务端oracle_winx64_12c_database.iso Oracle客户端instantclient-basiclite-nt-12.1.0.1.0.zip 集成开发 ...
- JUC之原子类
在分析原子类之前,先来了解CAS操作 CAS CAS,compare and swap的缩写,中文翻译成比较并交换. CAS 操作包含三个操作数 —— 内存位置(V).预期原值(A)和新值(B).如果 ...
- C++ 用 vector 生成三维数组,并计算行、列、高
//Microsoft Visual Studio 2015 Enterprise //用vector生成三维数组,并计算行.列.高 #include <iostream> #includ ...
- 机器学习SVD笔记
机器学习中SVD总结 矩阵分解的方法 特征值分解. PCA(Principal Component Analysis)分解,作用:降维.压缩. SVD(Singular Value Decomposi ...
- PB计算两个日期相差月份(计算工龄)
ll_intime_y = year(date(this.object.in_factory_day[row])) ll_intime_m = month(date(this.object.in_fa ...
- 2.33模型--去除字符串两头空格.c
[注:本程序验证是使用vs2013版] #include <stdio.h> #include <stdlib.h> #include <string.h> #pr ...
- Educational Codeforces Round 61 (Div.2)
A.(c1=0&&c3>0)||(c1!=c4) #include<cstdio> #include<cstring> #include<algor ...
- javascript 之 扩展对象
注意点:在js中常见的几种方进行扩展 第一种:ES6提供的 Object.assign(); 第二种:ES5提供的 extend()方法 第三种:Object对象提供的 defineProperty( ...