pytorch中如何使用DataLoader对数据集进行批处理
最近搞了搞minist手写数据集的神经网络搭建,一个数据集里面很多个数据,不能一次喂入,所以需要分成一小块一小块喂入搭建好的网络。
pytorch中有很方便的dataloader函数来方便我们进行批处理,做了简单的例子,过程很简单,就像把大象装进冰箱里一共需要几步?
第一步:打开冰箱门。
我们要创建torch能够识别的数据集类型(pytorch中也有很多现成的数据集类型,以后再说)。
首先我们建立两个向量X和Y,一个作为输入的数据,一个作为正确的结果:

随后我们需要把X和Y组成一个完整的数据集,并转化为pytorch能识别的数据集类型:

我们来看一下这些数据的数据类型:

可以看出我们把X和Y通过Data.TensorDataset() 这个函数拼装成了一个数据集,数据集的类型是【TensorDataset】。
好了,第一步结束了,冰箱门打开了。
第二步:把大象装进去。
就是把上一步做成的数据集放入Data.DataLoader中,可以生成一个迭代器,从而我们可以方便的进行批处理。

DataLoader中也有很多其他参数:
dataset:Dataset类型,从其中加载数据
batch_size:int,可选。每个batch加载多少样本
shuffle:bool,可选。为True时表示每个epoch都对数据进行洗牌
sampler:Sampler,可选。从数据集中采样样本的方法。
num_workers:int,可选。加载数据时使用多少子进程。默认值为0,表示在主进程中加载数据。
collate_fn:callable,可选。
pin_memory:bool,可选
drop_last:bool,可选。True表示如果最后剩下不完全的batch,丢弃。False表示不丢弃。
好了,第二步结束了,大象装进去了。
第三步:把冰箱门关上。
好啦,现在我们就可以愉快的用我们上面定义好的迭代器进行训练啦。
在这里我们利用print来模拟我们的训练过程,即我们在这里对搭建好的网络进行喂入。

输出的结果是:
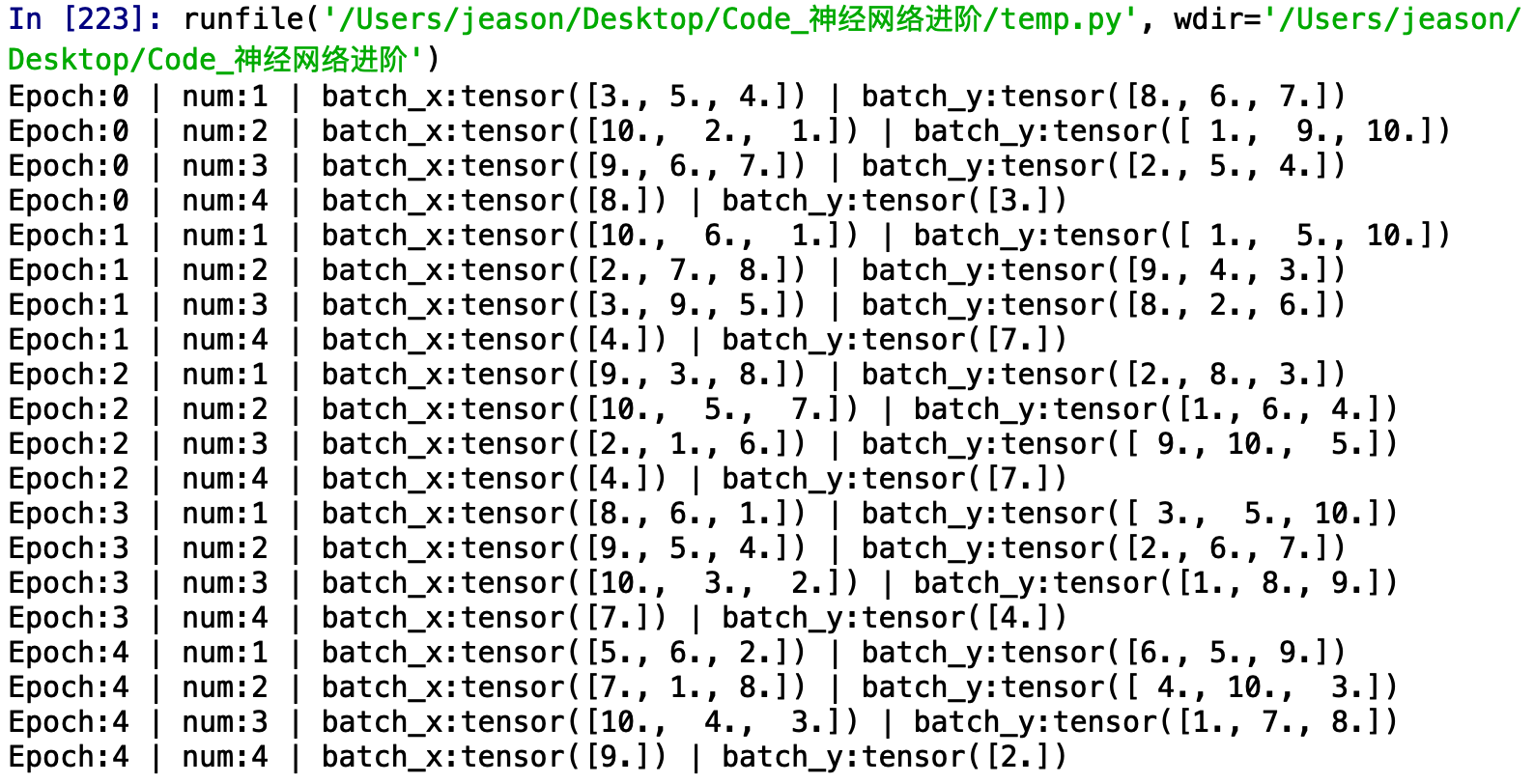
可以看到,我们一共训练了所有的数据训练了5次。数据中一共10组,我们设置的mini-batch是3,即每一次我们训练网络的时候喂入3组数据,到了最后一次我们只有1组数据了,比mini-batch小,我们就仅输出这一个。
此外,还可以利用python中的enumerate(),是对所有可以迭代的数据类型(含有很多东西的list等等)进行取操作的函数,用法如下:
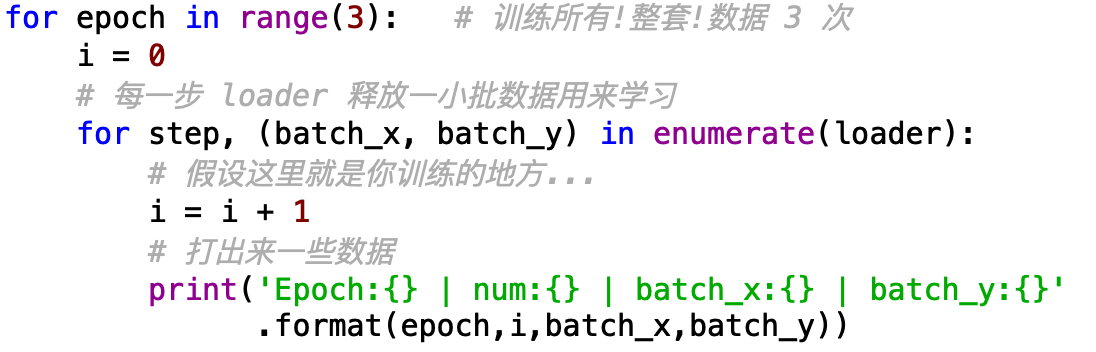
好啦,现在冰箱门就关上啦,(*^__^*)
pytorch中如何使用DataLoader对数据集进行批处理的更多相关文章
- pytorch Dataset数据集和Dataloader迭代数据集
import torch from torch.utils.data import Dataset,DataLoader class SmsDataset(Dataset): def __init__ ...
- pytorch中DataLoader, DataSet, Sampler之间的关系
转自:https://mp.weixin.qq.com/s/RTv0cUWvc0kuXBeNoXVu_A 自上而下理解三者关系 首先我们看一下DataLoader.__next__的源代码长什么样,为 ...
- PyTorch中的MIT ADE20K数据集的语义分割
PyTorch中的MIT ADE20K数据集的语义分割 代码地址:https://github.com/CSAILVision/semantic-segmentation-pytorch Semant ...
- pytorch中tensorboardX的用法
在代码中改好存储Log的路径 命令行中输入 tensorboard --logdir /home/huihua/NewDisk1/PycharmProjects/pytorch-deeplab-xce ...
- 转pytorch中训练深度神经网络模型的关键知识点
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/weixin_42279044/articl ...
- [深度学习] pytorch利用Datasets和DataLoader读取数据
本文简单描述如果自定义dataset,代码并未经过测试(只是说明思路),为半伪代码.所有逻辑需按自己需求另外实现: 一.分析DataLoader train_loader = DataLoader( ...
- 第五章——Pytorch中常用的工具
2018年07月07日 17:30:40 __矮油不错哟 阅读数:221 1. 数据处理 数据加载 ImageFolder DataLoader加载数据 sampler:采样模块 1. 数据处理 ...
- pytorch加载语音类自定义数据集
pytorch对一下常用的公开数据集有很方便的API接口,但是当我们需要使用自己的数据集训练神经网络时,就需要自定义数据集,在pytorch中,提供了一些类,方便我们定义自己的数据集合 torch.u ...
- PyTorch中使用深度学习(CNN和LSTM)的自动图像标题
介绍 深度学习现在是一个非常猖獗的领域 - 有如此多的应用程序日复一日地出现.深入了解深度学习的最佳方法是亲自动手.尽可能多地参与项目,并尝试自己完成.这将帮助您更深入地掌握主题,并帮助您成为更好的深 ...
随机推荐
- BZOJ2135 刷题计划(贪心+二分)
相邻数作差后容易转化成将这些数最多再切m刀能获得的最小偏差值.大胆猜想化一波式子可以发现将一个数平均分是最优的.并且划分次数越多能获得的偏差值增量越小.那么就可以贪心了:将所有差扔进堆里,每次取出增量 ...
- 微信access_token请求之简单缓存方法封装
还有东西要搞,就直接上代码 function.php <?php // 一个好玩的 curl 类 // https://github.com/metowolf/Meting/blob/maste ...
- Android 访问 Webapi 更新UI
首先,写一个访问webapi的工具类 import org.apache.http.HttpEntity; import org.apache.http.HttpResponse; import or ...
- BUPT2017 wintertraining(15) #1 题解
拖了一周才完成的题解,抛出一个可爱的表情 (っ'-')╮ =͟͟͞͞❤️.对我来说E.F比较难,都是线段树的题,有点久没写了. A - Infinite Sequence CodeForces - 6 ...
- luogu P2644 树上游戏
一道点分难题 首先很自然的想法就是每种颜色的贡献可以分开计算,然后如果你会虚树就可以直接做了 点分也差不多,考虑每个分治重心的子树对它的贡献以及它对它子树的贡献 首先,处理一个\(cnt\)数组,\( ...
- JavaScript中解决jQuery和Prototype.js同时引入冲突问题
两个库同时都定义了一个叫$的函数,所以在同时使用的时候会发生冲突.jQuery( http://jquery.com/ https://jquery.org/ )中提供了一种返还$的使用权给其他js库 ...
- configParse模块(二十七)
configparser用于处理特定格式的文件,其本质上是利用open来操作文件. # 注释1 ; 注释2 [section1] # 节点 k1 = v1 # 值 k2:v2 # 值 [section ...
- NOIP 普及组 2013 表达式求值
传送门 https://www.cnblogs.com/violet-acmer/p/9898636.html 题解: 哇哇哇,又是一发暴力AC. 用字符数组存储表达式. 然后将表达式中的 数字 与 ...
- 洛谷 P4378 [USACO18OPEN]Out of Sorts S(树状数组求冒泡排序循环次数)
传送门:Problem P4378 https://www.cnblogs.com/violet-acmer/p/9833502.html 要回宿舍休息了,题解明天再补吧. 题解: 定义一数组 a[m ...
- springboot的小知识总结
1.RestTemplate提交表单数据的三种方法 https://blog.csdn.net/yiifaa/article/details/77939282 2.spring data的分页实现:p ...