BP
下面内容抄袭这里的:galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop.html
Principles of training multi-layer neural network using backpropagation
The project describes teaching process of multi-layer neural network employing backpropagation algorithm. To illustrate this process the three layer neural network with two inputs and one output,which is shown in the picture below, is used:
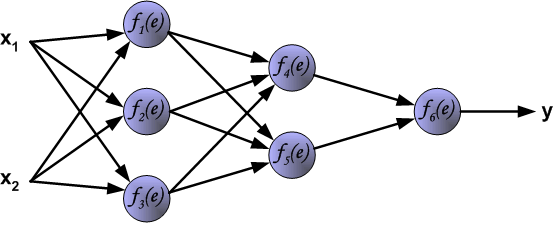
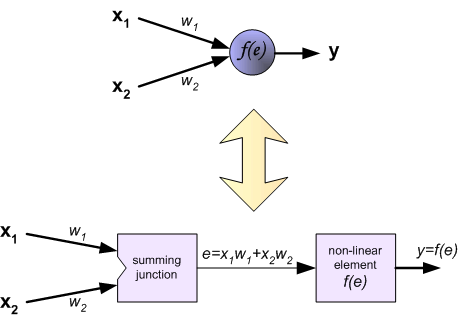
Each neuron is composed of two units. First unit adds products of weights coefficients and input signals. The second unit realise nonlinear
function, called neuron activation function. Signal e is adder output signal, and y = f(e) is output signal of nonlinear
element. Signal y is also output signal of neuron.
To teach the neural network we need training data set. The training data set consists of input signals (x1 and
x2 ) assigned with corresponding target (desired output) z. The network training is an iterative process. In each
iteration weights coefficients of nodes are modified using new data from training data set. Modification is calculated using algorithm
described below:
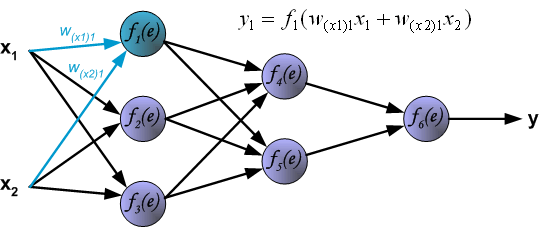
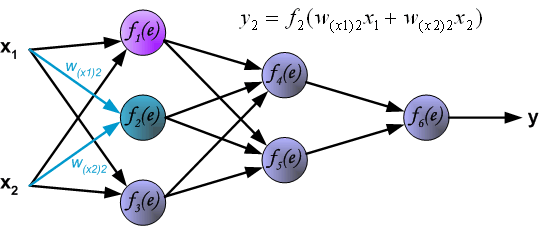
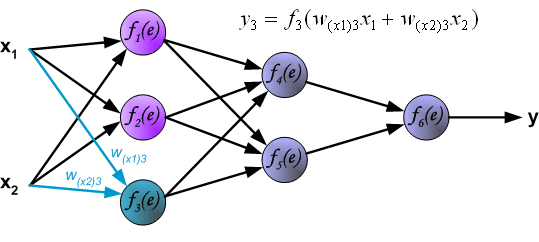
Each teaching step starts with forcing both input signals from training set. After this stage we can determine output signals values for
each neuron in each network layer. Pictures below illustrate how signal is propagating through the network, Symbols w(xm)n
represent weights of connections between network input xm and neuron n in input layer. Symbols yn
represents output signal of neuron n.
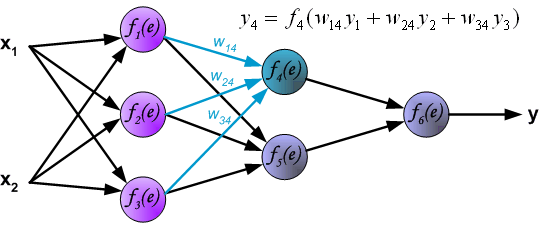
Propagation of signals through the hidden layer. Symbols wmn represent weights of connections between output of neuron
m and input of neuron n in the next layer.
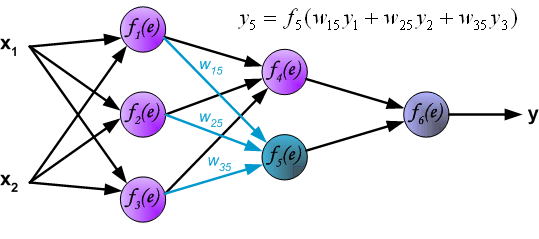
Propagation of signals through the output layer.
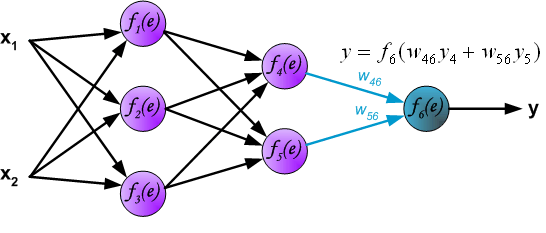
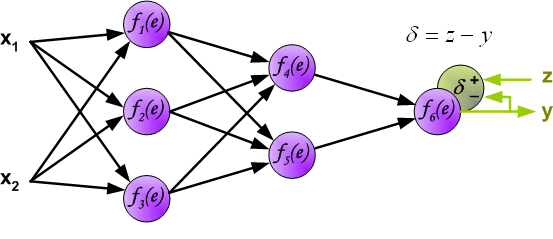
In the next algorithm step the output signal of the network y is compared with the desired output value (the target), which is found
in training data set. The difference is called error signal d of
output layer neuron.
下面才是反向传播部分
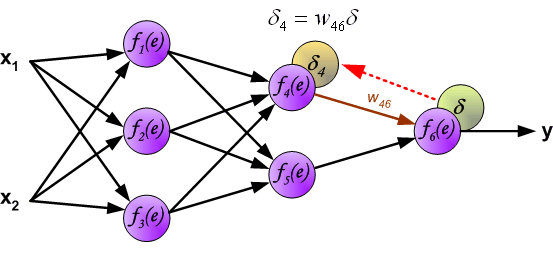
It is impossible to compute error signal for internal neurons directly, because output values of these neurons are unknown. For many years
the effective method for training multiplayer networks has been unknown. Only in the middle eighties the backpropagation algorithm has been
worked out. The idea is to propagate error signal d (computed in
single teaching step) back to all neurons, which output signals were input for discussed neuron.
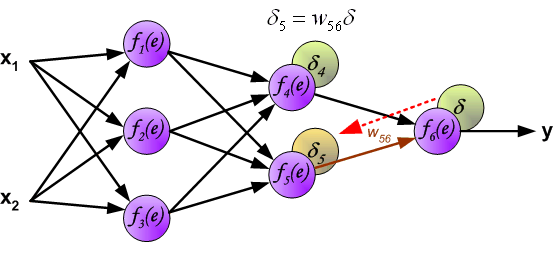
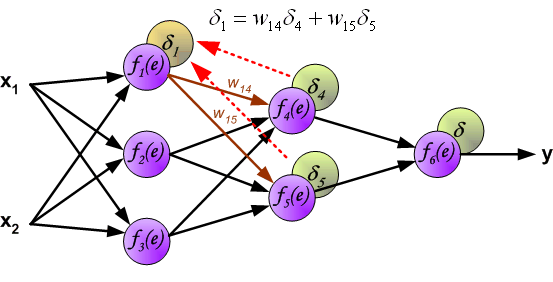
The weights' coefficients wmn used to propagate errors back are equal to this used during computing output value. Only the
direction of data flow is changed (signals are propagated from output to inputs one after the other[一个接一个地]). This technique is used for all network
layers. If propagated errors came from few[几个] neurons they are added. The illustration is below:
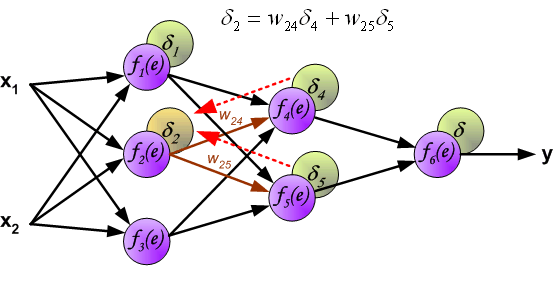
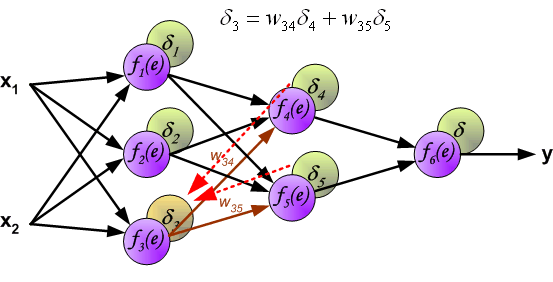
When the error signal for each neuron is computed, the weights coefficients of each neuron input node may be modified. In formulas below
df(e)/de represents derivative of neuron activation function (which weights are modified).
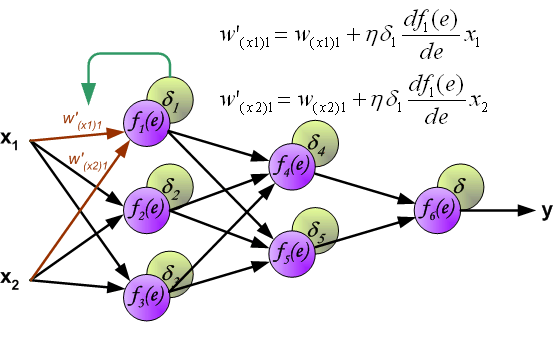
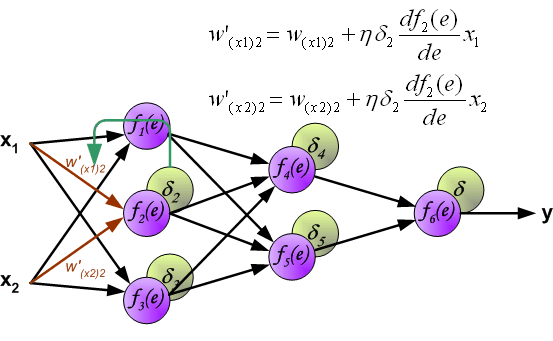
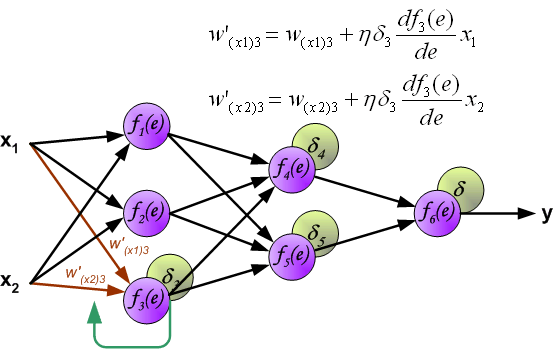
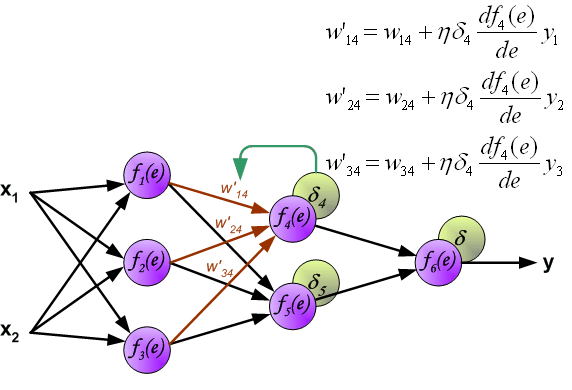
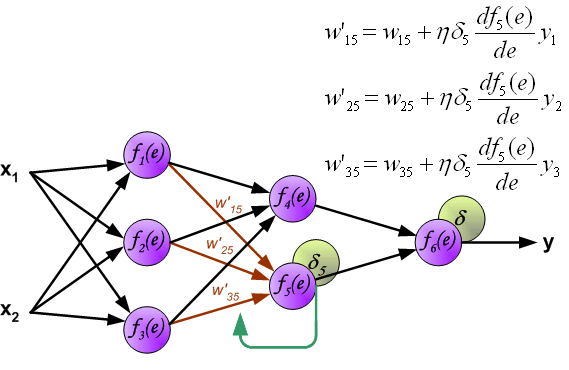
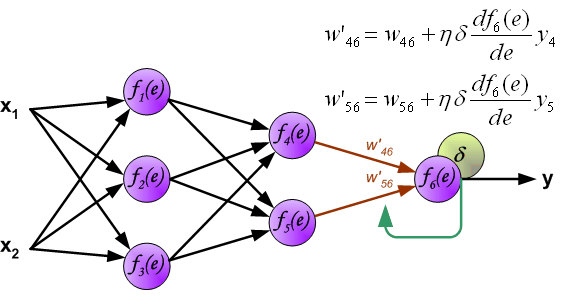
Coefficient h affects network teaching speed. There are a few
techniques to select this parameter. The first method is to start teaching process with large value of the parameter. While weights
coefficients are being established the parameter is being decreased gradually. The second, more complicated, method starts teaching with
small parameter value. During the teaching process the parameter is being increased when the teaching is advanced and then decreased again in
the final stage. Starting teaching process with low parameter value enables to determine weights coefficients signs.
通过上面的内容,最起码知道了反向传播更新参数的流程,但是没发现链式法则体现在哪里??
更新参数是从前往后进行的,那么y1、y2等是更新参数之前的取值还是更新参数之后的取值呢??私以为是前者。
下面是抄袭这里的:https://www.zhihu.com/question/27239198/answer/89853077
深度学习同样也是为了这个目的,只不过此时,样本点不再限定为(x, y)点对,而可以是由向量、矩阵等等组成的广义点对(X,Y)。而此时,(X,Y)之间的关系也变得十分复杂,不太可能用一个简单函数表示。然而,人们发现可以用多层神经网络来表示这样的关系,而多层神经网络的本质就是一个多层复合的函数。借用网上找到的一幅图[1],来直观描绘一下这种复合关系。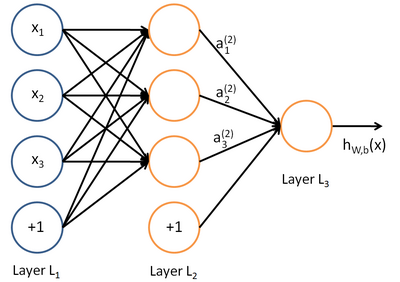
其对应的表达式如下:
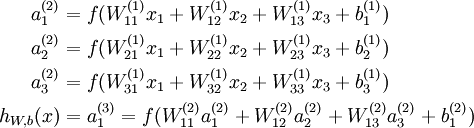 上面式中的Wij就是相邻两层神经元之间的权值,它们就是深度学习需要学习的参数,也就相当于直线拟合y=k*x+b中的待求参数k和b。
上面式中的Wij就是相邻两层神经元之间的权值,它们就是深度学习需要学习的参数,也就相当于直线拟合y=k*x+b中的待求参数k和b。
和直线拟合一样,深度学习的训练也有一个目标函数,这个目标函数定义了什么样的参数才算一组“好参数”,不过在机器学习中,一般是采用成本函数(cost function),然后,训练目标就是通过调整每一个权值Wij来使得cost达到最小。cost函数也可以看成是由所有待求权值Wij为自变量的复合函数,而且基本上是非凸的,即含有许多局部最小值。但实际中发现,采用我们常用的梯度下降法就可以有效的求解最小化cost函数的问题。
梯度下降法需要给定一个初始点,并求出该点的梯度向量,然后以负梯度方向为搜索方向,以一定的步长进行搜索,从而确定下一个迭代点,再计算该新的梯度方向,如此重复直到cost收敛。那么如何计算梯度呢?
假设我们把cost函数表示为, 那么它的梯度向量就等于
【偏导数相加】, 其中
表示正交单位向量。为此,我们需求出cost函数H对每一个权值Wij的偏导数。而BP算法正是用来求解这种多层复合函数的所有变量的偏导数的利器。
我们以求e=(a+b)*(b+1)的偏导为例。
它的复合关系画出图可以表示如下: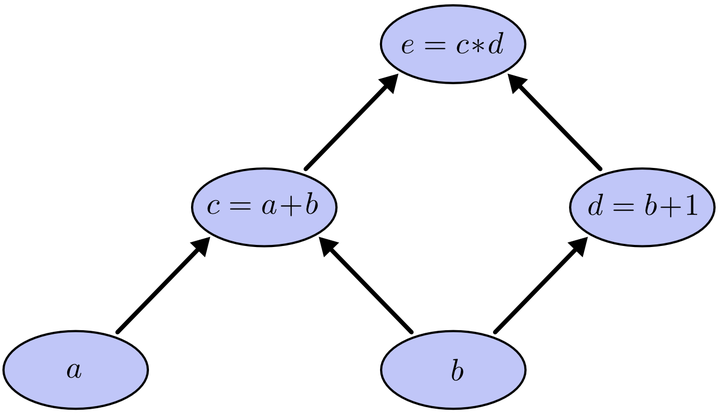 在图中,引入了中间变量c,d。
在图中,引入了中间变量c,d。
为了求出a=2, b=1时,e的梯度,我们可以先利用偏导数的定义求出不同层之间相邻节点的偏导关系,如下图所示。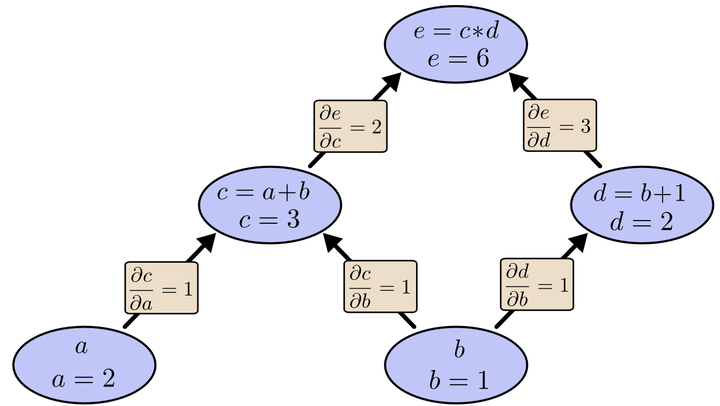 利用链式法则我们知道:
利用链式法则我们知道:以及
。
链式法则在上图中的意义是什么呢?其实不难发现,的值等于从a到e的路径上的偏导值的乘积,而
的值等于从b到e的路径1(b-c-e)上的偏导值的乘积与路径2(b-d-e)上的偏导值的乘积之和。也就是说,对于上层节点p和下层节点q,要求得
,需要找到从q节点到p节点的所有路径,并且对每条路径,求得该路径上的所有偏导数之乘积,然后将所有路径的 “乘积” 累加起来才能得到
的值。
大家也许已经注意到,这样做是十分冗余的,因为很多路径被重复访问了。比如上图中,a-c-e和b-c-e就都走了路径c-e。对于权值动则数万的深度模型中的神经网络,这样的冗余所导致的计算量是相当大的。
同样是利用链式法则,BP算法则机智地避开了这种冗余,它对于每一个路径只访问一次就能求顶点对所有下层节点的偏导值。
正如反向传播(BP)算法的名字说的那样,BP算法是反向(自上往下)来寻找路径的。
从最上层的节点e开始,初始值为1,以层为单位进行处理。对于e的下一层的所有子节点,将1乘以e到某个节点路径上的偏导值,并将结果“堆放”在该子节点中。等e所在的层按照这样传播完毕后,第二层的每一个节点都“堆放"些值,然后我们针对每个节点,把它里面所有“堆放”的值求和,就得到了顶点e对该节点的偏导。然后将这些第二层的节点各自作为起始顶点,初始值设为顶点e对它们的偏导值,以"层"为单位重复上述传播过程,即可求出顶点e对每一层节点的偏导数。
以上图为例,节点c接受e发送的1*2并堆放起来,节点d接受e发送的1*3并堆放起来,至此第二层完毕,求出各节点总堆放量并继续向下一层发送。节点c向a发送2*1并对堆放起来,节点c向b发送2*1并堆放起来,节点d向b发送3*1并堆放起来,至此第三层完毕,节点a堆放起来的量为2,节点b堆放起来的量为2*1+3*1=5, 即顶点e对b的偏导数为5.
举个不太恰当的例子,如果把上图中的箭头表示欠钱的关系,即c→e表示e欠c的钱。以a, b为例,直接计算e对它们俩的偏导相当于a, b各自去讨薪。a向c讨薪,c说e欠我钱,你向他要。于是a又跨过c去找e。b先向c讨薪,同样又转向e,b又向d讨薪,再次转向e。可以看到,追款之路,充满艰辛,而且还有重复,即a, b 都从c转向e。
而BP算法就是主动还款。e把所欠之钱还给c,d。c,d收到钱,乐呵地把钱转发给了a,b,皆大欢喜。
BP的更多相关文章
- BP神经网络原理及python实现
[废话外传]:终于要讲神经网络了,这个让我踏进机器学习大门,让我读研,改变我人生命运的四个字!话说那么一天,我在乱点百度,看到了这样的内容: 看到这么高大上,这么牛逼的定义,怎么能不让我这个技术宅男心 ...
- 手机开发中的AP与BP的概念
转自:http://blog.csdn.net/macong01/article/details/15504611 手机的AP和BP: AP:ApplicationProcessor,即应用芯片 BP ...
- 反向传播(BP)算法
著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处.作者:刘皮皮链接:https://www.zhihu.com/question/24827633/answer/29120394来源 ...
- 转--脉络清晰的BP神经网络讲解,赞
http://www.cnblogs.com/wengzilin/archive/2013/04/24/3041019.html 学 习是神经网络一种最重要也最令人注目的特点.在神经网络的发展进程中, ...
- 视觉机器学习读书笔记--------BP学习
反向传播算法(Back-Propagtion Algorithm)即BP学习属于监督式学习算法,是非常重要的一种人工神经网络学习方法,常被用来训练前馈型多层感知器神经网络. 一.BP学习原理 1.前馈 ...
- [DL学习笔记]从人工神经网络到卷积神经网络_1_神经网络和BP算法
前言:这只是我的一个学习笔记,里边肯定有不少错误,还希望有大神能帮帮找找,由于是从小白的视角来看问题的,所以对于初学者或多或少会有点帮助吧. 1:人工全连接神经网络和BP算法 <1>:人工 ...
- 关于BP网络的一些总结
背景 前段时间,用过一些模型如vgg,lexnet,用于做监督学习训练,顺带深入的学习了一下相关模型的结构&原理,对于它的反向传播算法记忆比较深刻, 就自己的理解来描述一下BP网络. 关于BP ...
- BP神经网络
秋招刚结束,这俩月没事就学习下斯坦福大学公开课,想学习一下深度学习(这年头不会DL,都不敢说自己懂机器学习),目前学到了神经网络部分,学习起来有点吃力,把之前学的BP(back-progagation ...
- bx, bp, si, di寄存器的使用规则
首先,都可以单独使用. 另外,组合使用的情况下: 记住这张图片就行了=_= 意思就是,bx只能和si,di组合.bp只能和si,di组合.
- bx、si、di 和 bp
bx.si.di 和 bp 在 8086CPU 中,只有这 4 个寄存器可以用在 "[...]" 中来进行内存单元的寻址. mov ax, [bx] mov ax, [bx+si] ...
随机推荐
- Spark机器学习(1):线性回归算法
线性回归算法,是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法. 1. 梯度下降法 线性回归可以使用最小二乘法,但是速度比较慢,因此一般使用梯度下降法(Grad ...
- Json解析包FastJson使用
阿里巴巴FastJson是一个Json处理工具包,包括“序列化”和“反序列化”两部分,它具备如下特征:速度最快,测试表明,fastjson具有极快的性能,超越任其他的Java Json parser. ...
- 利用Xmanager Enterprise 5的passive显示远程linux主机图形化信息
问题描述: 最初的需求是,安装oracle数据(第一次安装都是图形化linxu进去一步步操作,后续发现可以命令静默安装不调用图形化,学习就是步步入深,方得始终),最初实现window弹出linux主机 ...
- 15款HTML5/CSS3案例展示,导航,日历,钟表。
对于前端开发者来说,分享一些优秀的HTML5应用可以直接拿来用,更重要的是可以激发创作的灵感.今天我们要分享9款精挑细选的HTML5应用,个个都是干货. 1.HTML5/CSS3滑块动画菜单 图标动画 ...
- Linux ext3/ext4数据恢复
2012年12月9日 测试环境: Ubuntu 12.04 X86 +ext4 恢复文件使用的工具:extundelete(点击下载) 说明:当文件异常消失或者rm误删除后,避免在该分区中继 ...
- funny
var life = { "work_hard","have_fun","make_history" };
- AaronYang WCF教程目录
============================原创,讲究实践===================== 1. 那天有个小孩教我WCF[一][1/3] 基本搭建 阅读 ...
- MySQL -- 异步I/O
linux上,innodb使用异步IO子系统(native AIO)来对数据文件页进行预读和写请求.行为受到参数innodb_use_native_aio控制.默认是开启的,且只是适用于linux平台 ...
- swift学习之常量和变量
常量:就是在初始化时(试试定义时不赋值会不会报错)赋予一个准确的值,能够在非常多地方直接用到,用letkeyword生命 变量:这个就不用说了,就是能够在下一秒你能够随便改变的量,用varkeywor ...
- stale element reference: element is not attached to the page document 异常
在执行脚本时,有时候引用一些元素对象会抛出如下异常 org.openqa.selenium.StaleElementReferenceException: stale element referenc ...