gawk命令详解
GNU awk:
sort、cut、uniq、wc等参考:
https://blog.csdn.net/lk07828/article/details/46324807
https://blog.csdn.net/dexter_wang/article/details/64482594
https://www.jianshu.com/p/a29f32e35dc5
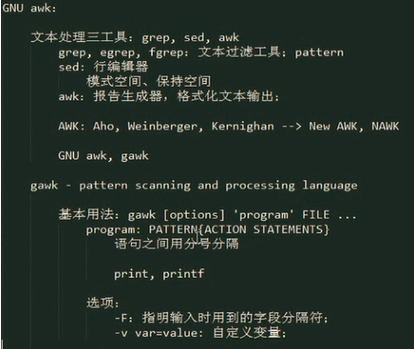
文本处理三工具:grep, sed, awk
grep, egrep, fgrep:文本过滤工具;pattern
sed: 行编辑器
模式空间、保持空间
awk:报告生成器,格式化文本输出;
AWK: Aho, Weinberger, Kernighan --> New AWK, NAWK
GNU awk, 简称gawk

gawk - pattern scanning and processing language
基本用法:gawk [options] 'program' FILE ...
program: PATTERN{ACTION STATEMENTS}
语句之间用分号分隔
print, printf 是ACTION STATEMENTS的两个选项
选项:
-F:指明输入时用到的字段分隔符;
-v var=value: 自定义变量;

1、print

print item1, item2, ...
要点:
(1) 逗号分隔符;
(2) 输出的各item可以是字符串,也可以是数值;当前记录的字段、变量或awk的表达式;
(3) 如省略item,相当于print $0;



2、变量

2.1 内建变量
FS:input field seperator,输入时的字段分隔符,默认为空白字符;
OFS:output field seperator,输出时的字段分隔符默认为空白字符;



RS:input record seperator,输入时的换行符;
ORS:output record seperator,输出时的换行符;


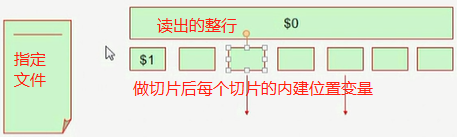
NF:number of field,每一行的字段数量
{print NF}, {print $NF}
如果引用awk内部的变量(比如NF)的话,是不能加$的,像$1,$2这是字段


NR:number of record, 行数;

FNR:各文件分别计数;行数;

FILENAME:当前文件名;
ARGC:命令行参数的个数;
ARGV:数组,保存的是命令行所给定的各参数;

2.2 自定义变量
1、 -v var=value 自定义变量
变量名区分字符大小写;


2、 在program中直接定义
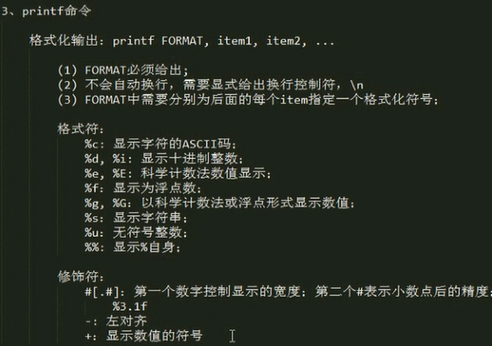
3、printf命令
格式化输出:printf FORMAT, item1, item2, ...
(1) FORMAT必须给出;
(2) 不会自动换行,需要显式给出换行控制符,\n
(3) FORMAT中需要分别为后面的每个item指定一个格式化符号;
FORMAT格式符:
%c: 显示字符的ASCII码;
%d, %i: 显示十进制整数;
%e, %E: 科学计数法数值显示;
%f:显示为浮点数;
%g, %G:以科学计数法或浮点形式显示数值;
%s:显示字符串;
%u:无符号整数;
%%: 显示%自身;
 以字符串形式显示文件的第一个字段
以字符串形式显示文件的第一个字段


修饰符:
#[.#]:第一个数字控制显示的宽度;第二个#表示小数点后的精度;
%3.1f
-:左对齐
+:显示数值的符号


4、操作符
算术操作符:
x+y, x-y, x*y, x/y, x^y, x%y
-x:负x
+x:把字符串转换为数值;
字符串操作符:
没有符号的操作符,表示字符串连接
赋值操作符:
=, +=, -=, *=, /=, %=, ^=
++, --
比较操作符:
>, >=, <, <=, !=, ==
模式匹配符:
~:是否匹配
!~:是否不匹配
逻辑操作符:
&&
||
!
函数调用:
function_name(argu1, argu2, ...)
条件表达式:
selector?if-true-expression:if-false-expression
selector:条件表达式
?:判断为真还是为假,为真则执行if-true-expression,为假则执行if-false-expression
# awk -F: '{$3>=1000?usertype="Common User":usertype="Sysadmin or SysUser";printf "%15s:%-s\n",$1,usertype}' /etc/passwd

# awk -F: '{$3>=500?usertype="common user":usertype="sysadmin";printf "%15s: %4d: %s\n",$1,$3,usertype}' /etc/passwd
5、PATTERN
(1) empty:空模式,匹配每一行;
(2) /regular expression/:仅处理能够被此处的模式匹配到的行;
(3) relational expression: 关系表达式;结果有“真”有“假”;结果为“真”才会被处理;真:结果为非0值,非空字符串;
# awk -F: '$3>=500{print $1,$3}' /etc/passwd 大于500才会处理
polkitd 999
# awk -F: '$NF=="/bin/bash"{print $1,$NF}' /etc/passwd
root /bin/bash
# awk -F: '$NF~/bash$/{print $1,$NF}' /etc/passwd /bash$/ 模式要用//括起来,$表示以bash结尾,~表示模式匹配符号
root /bin/bash
# awk -F: '$3>=40{printf "%15s: %d\n",$1,$3}' /etc/passwd | sort -n -k 2 -t:
apache: 48
tcpdump: 72
sshd: 74
dbus: 81
postfix: 89
nobody: 99
systemd-network: 192
polkitd: 999
(4) line ranges:行范围,指定起始结束行
startline,endline:/pat1/,/pat2/
#awk -F: '/^nobody/,/^sshd/{print $1}' /etc/passwd
# awk -F: '/^root/,/^mysql/{print $1}' /etc/passwd
注意: 不支持直接给出数字的格式
# awk -F: '(NR>=2&&NR<=10){print $1}' /etc/passwd
# awk '(NR==2)' /etc/passwd //打印第二行
# awk '(NR==2)' /etc/passwd //打印第二行
或
# awk 'NR==1{print}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
如何取/etc/passwd第二行,去重后排序(未完成)
# sed -n "2,1p" /etc/passwd | awk -F: '{print $1,$2,$3,$4,$5,$6,$7}'
bin x 1 1 bin /bin /sbin/nologin
(5) BEGIN/END模式
BEGIN{}: 仅在开始处理文件中的文本之前执行一次;
# awk -F: 'BEGIN{print " username uid\n-----"}{printf "%15s,%8s\n",$1,$3}' /etc/passwd //打印表头
END{}:仅在文本处理完成之后执行一次;
#awk -F: 'BEGIN{print " username uid\n-----"}{printf "%15s,%8s\n",$1,$3}END{print "===========\n END"}' /etc/passwd
注:如果不对文件做处理,可以在前面加BEGIN
# awk 'BEGIN{weekdays["mon"]="monday";weekdays["tue"]="Tuesday";print weekdays["mon"]}'
6、常用的action
(1) Expressions 表达式
(2) Control statements:控制语句 ,比如if, while等;
(3) Compound statements:组合语句;
(4) input statements:输入语句
(5) output statements:输出语句
7、控制语句
if(condition) {statments} 单分支语句
if(condition) {statments} else {statements}组合语句
while(conditon) {statments} while循环
do {statements} while(condition) do循环
for(expr1;expr2;expr3) {statements} for循环
break 控制语句
continue
delete array[index] 从数组中删除指定元素
delete array 删除整个数组
exit
{ statements } 组合语句
gawk命令详解的更多相关文章
- linux awk命令详解
linux awk命令详解 简介 awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,以空格为默认分 ...
- linux awk命令详解,使用system来内嵌系统命令, awk合并两列
linux awk命令详解 简介 awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,以空格为默认分 ...
- Shell学习(五)—— awk命令详解
一.awk简介 awk是一个非常好用的数据处理工具,相对于sed常常作用于一整个行的处理,awk则比较倾向于一行当中分成数个[字段]处理,因此,awk相当适合处理小型的数据数据处理.awk是一种报 ...
- Git初探--笔记整理和Git命令详解
几个重要的概念 首先先明确几个概念: WorkPlace : 工作区 Index: 暂存区 Repository: 本地仓库/版本库 Remote: 远程仓库 当在Remote(如Github)上面c ...
- linux yum命令详解
yum(全称为 Yellow dog Updater, Modified)是一个在Fedora和RedHat以及SUSE中的Shell前端软件包管理器.基於RPM包管理,能够从指定的服务器自动下载RP ...
- Linux下ps命令详解 Linux下ps命令的详细使用方法
http://www.jb51.net/LINUXjishu/56578.html Linux下的ps命令比较常用 Linux下ps命令详解Linux上进程有5种状态:1. 运行(正在运行或在运行队列 ...
- Docker命令详解
Docker命令详解 最近学习Docker,将docker所有命令实验了一番,特整理如下: # docker --help Usage: docker [OPTIONS] COMMAND [arg ...
- android adb 命令详解
ADB (Android Debug Bridge) 是android SDK中的工具,需要先配置环境变量才能使用.起调试桥的作用,可以管理安卓设备.(也叫debug工具) ---------查看设 ...
- Git 常用命令详解
Git 是一个很强大的分布式版本管理工具,它不但适用于管理大型开源软件的源代码(如:linux kernel),管理私人的文档和源代码也有很多优势(如:wsi-lgame-pro) Git 的更多介绍 ...
随机推荐
- requests 学习笔记
除了get 方式外 还有post 等等 注意字典里值为 None 的键都不会被添加到 URL 的查询字符串里 import requests getpara = {"key1":& ...
- 栈(stack)和堆(heap)
栈(stack)和堆(heap), Java程序在运行时都要开辟空间,任何软件在运行时都要在内存中开辟空间,Java虚拟机运行时也是要开辟空间的.JVM运行时在内存中开辟一片内存区域,启动时在自己的内 ...
- JDK8 元空间
1. 运行时常量池和静态变量都存储到了堆中,MetaSpace存储类的元数据,MetaSpace直接申请在本地内存中(Native memory),这样类的元数据分配只受本地内存大小的限制,OOM问题 ...
- navicat 连接postgresql报错pg_hba.conf
PostgreSQ数据库为了安全,它不会监听除本地以外的所有连接请求,当用户通过JDBC访问是,会报一些如下的异常: org.postgresql.util.PSQLException: FATAL: ...
- websocket 原理
自己写一个websocket import socket, hashlib, base64 sock = socket.socket() sock.bind(('127.0.0.1', 9000)) ...
- ECharts + Jquery 做大屏展示
HTML <!doctype html> <html> <head> <meta charset="utf-8"> <meta ...
- SpringMVC中参数接收
/** * * SpringMVC中参数接收 * 1.接收简单类型 int String * 2.可以使用对象pojo接收 * 3.可以使用集合数据接收参数 * 页面: name="ids ...
- 启动项详解和更改deepin启动内核的方法
内容来自网上查找和总结以及自己的尝试 boot里面的启动项是根据其它文件生成的,如果改boot里面,会在你更新grub后再次回到原来的状态.(之后 我(有显卡驱动问题的用户)通过在开机时选择系统页面按 ...
- Google翻译实现
https://blog.csdn.net/yingshukun/article/details/53470424 Google翻译实现
- sql 思路
先 django 定好sql框架 再 sqlalchemy 根据框架写...