入门大数据---Flink开发环境搭建
一、安装 Scala 插件
Flink 分别提供了基于 Java 语言和 Scala 语言的 API ,如果想要使用 Scala 语言来开发 Flink 程序,可以通过在 IDEA 中安装 Scala 插件来提供语法提示,代码高亮等功能。打开 IDEA , 依次点击 File => settings => plugins 打开插件安装页面,搜索 Scala 插件并进行安装,安装完成后,重启 IDEA 即可生效。
二、Flink 项目初始化
2.1 使用官方脚本构建
Flink 官方支持使用 Maven 和 Gradle 两种构建工具来构建基于 Java 语言的 Flink 项目;支持使用 SBT 和 Maven 两种构建工具来构建基于 Scala 语言的 Flink 项目。 这里以 Maven 为例进行说明,因为其可以同时支持 Java 语言和 Scala 语言项目的构建。需要注意的是 Flink 1.9 只支持 Maven 3.0.4 以上的版本,Maven 安装完成后,可以通过以下两种方式来构建项目:
1. 直接基于 Maven Archetype 构建
直接使用下面的 mvn 语句来进行构建,然后根据交互信息的提示,依次输入 groupId , artifactId 以及包名等信息后等待初始化的完成:
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.9.0
注:如果想要创建基于 Scala 语言的项目,只需要将 flink-quickstart-java 换成 flink-quickstart-scala 即可,后文亦同。
2. 使用官方脚本快速构建
为了更方便的初始化项目,官方提供了快速构建脚本,可以直接通过以下命令来进行调用:
$ curl https://flink.apache.org/q/quickstart.sh | bash -s 1.9.0
该方式其实也是通过执行 maven archetype 命令来进行初始化,其脚本内容如下:
PACKAGE=quickstart
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=${1:-1.8.0} \
-DgroupId=org.myorg.quickstart \
-DartifactId=$PACKAGE \
-Dversion=0.1 \
-Dpackage=org.myorg.quickstart \
-DinteractiveMode=false
可以看到相比于第一种方式,该种方式只是直接指定好了 groupId ,artifactId ,version 等信息而已。
2.2 使用 IDEA 构建
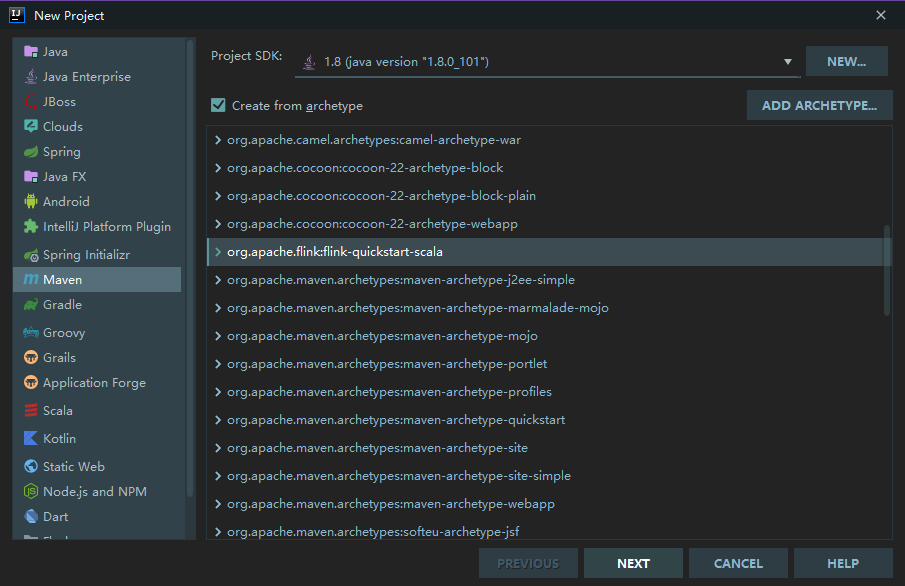
如果你使用的是开发工具是 IDEA ,可以直接在项目创建页面选择 Maven Flink Archetype 进行项目初始化:
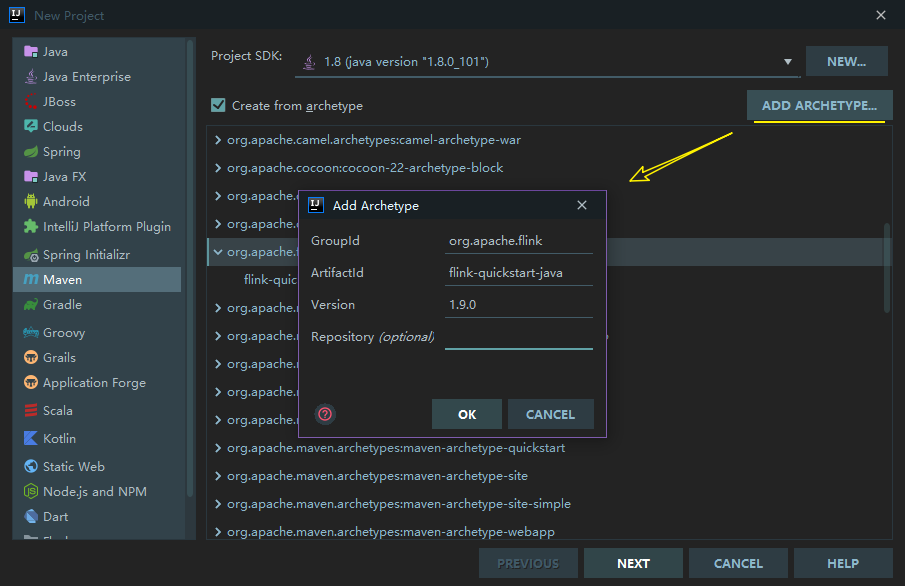
如果你的 IDEA 没有上述 Archetype, 可以通过点击右上角的 ADD ARCHETYPE ,来进行添加,依次填入所需信息,这些信息都可以从上述的 archetype:generate 语句中获取。点击 OK 保存后,该 Archetype 就会一直存在于你的 IDEA 中,之后每次创建项目时,只需要直接选择该 Archetype 即可:
选中 Flink Archetype ,然后点击 NEXT 按钮,之后的所有步骤都和正常的 Maven 工程相同。
三、项目结构
3.1 项目结构
创建完成后的自动生成的项目结构如下:
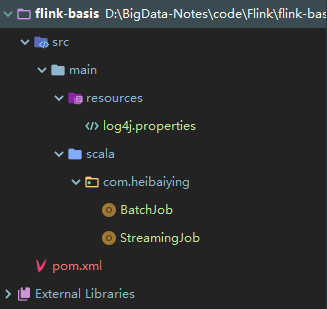
其中 BatchJob 为批处理的样例代码,源码如下:
import org.apache.flink.api.scala._
object BatchJob {
def main(args: Array[String]) {
val env = ExecutionEnvironment.getExecutionEnvironment
....
env.execute("Flink Batch Scala API Skeleton")
}
}
getExecutionEnvironment 代表获取批处理的执行环境,如果是本地运行则获取到的就是本地的执行环境;如果在集群上运行,得到的就是集群的执行环境。如果想要获取流处理的执行环境,则只需要将 ExecutionEnvironment 替换为 StreamExecutionEnvironment, 对应的代码样例在 StreamingJob 中:
import org.apache.flink.streaming.api.scala._
object StreamingJob {
def main(args: Array[String]) {
val env = StreamExecutionEnvironment.getExecutionEnvironment
...
env.execute("Flink Streaming Scala API Skeleton")
}
}
需要注意的是对于流处理项目 env.execute() 这句代码是必须的,否则流处理程序就不会被执行,但是对于批处理项目则是可选的。
3.2 主要依赖
基于 Maven 骨架创建的项目主要提供了以下核心依赖:其中 flink-scala 用于支持开发批处理程序 ;flink-streaming-scala 用于支持开发流处理程序 ;scala-library 用于提供 Scala 语言所需要的类库。如果在使用 Maven 骨架创建时选择的是 Java 语言,则默认提供的则是 flink-java 和 flink-streaming-java 依赖。
<!-- Apache Flink dependencies -->
<!-- These dependencies are provided, because they should not be packaged into the JAR file. -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- Scala Library, provided by Flink as well. -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<scope>provided</scope>
</dependency>
需要特别注意的以上依赖的 scope 标签全部被标识为 provided ,这意味着这些依赖都不会被打入最终的 JAR 包。因为 Flink 的安装包中已经提供了这些依赖,位于其 lib 目录下,名为 flink-dist_*.jar ,它包含了 Flink 的所有核心类和依赖:

scope 标签被标识为 provided 会导致你在 IDEA 中启动项目时会抛出 ClassNotFoundException 异常。基于这个原因,在使用 IDEA 创建项目时还自动生成了以下 profile 配置:
<!-- This profile helps to make things run out of the box in IntelliJ -->
<!-- Its adds Flink's core classes to the runtime class path. -->
<!-- Otherwise they are missing in IntelliJ, because the dependency is 'provided' -->
<profiles>
<profile>
<id>add-dependencies-for-IDEA</id>
<activation>
<property>
<name>idea.version</name>
</property>
</activation>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<scope>compile</scope>
</dependency>
</dependencies>
</profile>
</profiles>
在 id 为 add-dependencies-for-IDEA 的 profile 中,所有的核心依赖都被标识为 compile,此时你可以无需改动任何代码,只需要在 IDEA 的 Maven 面板中勾选该 profile,即可直接在 IDEA 中运行 Flink 项目:
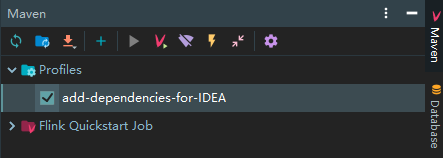
四、词频统计案例
项目创建完成后,可以先书写一个简单的词频统计的案例来尝试运行 Flink 项目,以下以 Scala 语言为例,分别介绍流处理程序和批处理程序的编程示例:
4.1 批处理示例
import org.apache.flink.api.scala._
object WordCountBatch {
def main(args: Array[String]): Unit = {
val benv = ExecutionEnvironment.getExecutionEnvironment
val dataSet = benv.readTextFile("D:\\wordcount.txt")
dataSet.flatMap { _.toLowerCase.split(",")}
.filter (_.nonEmpty)
.map { (_, 1) }
.groupBy(0)
.sum(1)
.print()
}
}
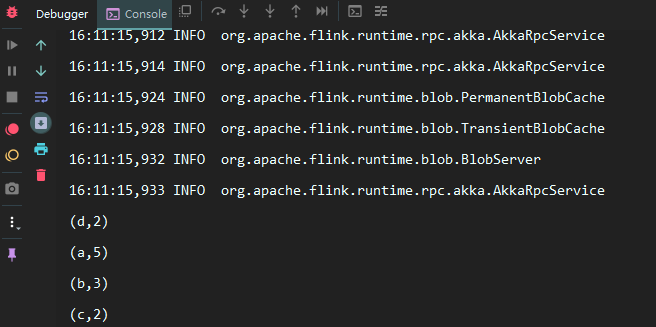
其中 wordcount.txt 中的内容如下:
a,a,a,a,a
b,b,b
c,c
d,d
本机不需要配置其他任何的 Flink 环境,直接运行 Main 方法即可,结果如下:
4.2 流处理示例
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object WordCountStreaming {
def main(args: Array[String]): Unit = {
val senv = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream: DataStream[String] = senv.socketTextStream("192.168.0.229", 9999, '\n')
dataStream.flatMap { line => line.toLowerCase.split(",") }
.filter(_.nonEmpty)
.map { word => (word, 1) }
.keyBy(0)
.timeWindow(Time.seconds(3))
.sum(1)
.print()
senv.execute("Streaming WordCount")
}
}
这里以监听指定端口号上的内容为例,使用以下命令来开启端口服务:
nc -lk 9999
之后输入测试数据即可观察到流处理程序的处理情况。
五、使用 Scala Shell
对于日常的 Demo 项目,如果你不想频繁地启动 IDEA 来观察测试结果,可以像 Spark 一样,直接使用 Scala Shell 来运行程序,这对于日常的学习来说,效果更加直观,也更省时。Flink 安装包的下载地址如下:
https://flink.apache.org/downloads.html
Flink 大多数版本都提供有 Scala 2.11 和 Scala 2.12 两个版本的安装包可供下载:

下载完成后进行解压即可,Scala Shell 位于安装目录的 bin 目录下,直接使用以下命令即可以本地模式启动:
./start-scala-shell.sh local
命令行启动完成后,其已经提供了批处理 (benv 和 btenv)和流处理(senv 和 stenv)的运行环境,可以直接运行 Scala Flink 程序,示例如下:

最后解释一个常见的异常:这里我使用的 Flink 版本为 1.9.1,启动时会抛出如下异常。这里因为按照官方的说明,目前所有 Scala 2.12 版本的安装包暂时都不支持 Scala Shell,所以如果想要使用 Scala Shell,只能选择 Scala 2.11 版本的安装包。
[root@hadoop001 bin]# ./start-scala-shell.sh local
错误: 找不到或无法加载主类 org.apache.flink.api.scala.FlinkShell
入门大数据---Flink开发环境搭建的更多相关文章
- 入门大数据---Spark开发环境搭建
一.安装Spark 1.1 下载并解压 官方下载地址:http://spark.apache.org/downloads.html ,选择 Spark 版本和对应的 Hadoop 版本后再下载: 解压 ...
- 【JAVA零基础入门系列】Day1 开发环境搭建
[JAVA零基础入门系列](已完结)导航目录 Day1 开发环境搭建 Day2 Java集成开发环境IDEA Day3 Java基本数据类型 Day4 变量与常量 Day5 Java中的运算符 Day ...
- Apache Flink 开发环境搭建和应用的配置、部署及运行
https://mp.weixin.qq.com/s/noD2Jv6m-somEMtjWTJh3w 本文是根据 Apache Flink 系列直播课程整理而成,由阿里巴巴高级开发工程师沙晟阳分享,主要 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- Flink学习笔记:Flink开发环境搭建
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Unix/Linux环境C编程入门教程(18) kali-linuxCCPP开发环境搭建
1. Kali linux是BT5的晋级版本,用于信息安全.基于Debian7内核.新建虚拟机. 2. 选择默认虚拟机 3. 选择稍后安装操作系统 4.选择Linux Debian7 64位,因为Ka ...
- Unix/Linux环境C编程入门教程(15) BT5开发环境搭建
1. Backtrack 是处于世界领先地位的渗透测试和信息安全审计发行版本.有着上百种预先安装好的工具软件,并确定能完美运行,Backtrack5 提供了一个强大的渗透测试平台--从Web hack ...
- Unix/Linux环境C编程入门教程(7) OPENBSDCCPP开发环境搭建
1. 年发起了OpenBSD 专案,希望创造一个注重安全的操作系统. 2.创建一个虚拟机. 3.选择默认的workstation10.0 4.我们选择稍后安装操作系统. 5.我们选择FreeBSD64 ...
- 大数据基础-2-Hadoop-1环境搭建测试
Hadoop环境搭建测试 1 安装软件 1.1 规划目录 /opt [root@host2 ~]# cd /opt [root@host2 opt]# mkdir java [root@host2 o ...
随机推荐
- jchdl - GSL实例 - Concat
https://mp.weixin.qq.com/s/oJY6Xj9_oM1gSmvH_dHkJg Concat节点把多根输入线线组合成一排线输出. 参考链接 https://github.c ...
- URL跳转与钓鱼
从登录页跳转到另一个页面就叫做URL跳转. 1.URL跳转 URL跳转一般分为两种,(1)客户端跳转:(2)服务端跳转.对用户来说,两种跳转都是透明的,都是指向或者跳转到另一个页面,页面发生了改变.但 ...
- 【Hadoop】hdfs文件上传流程图
- EntityFramework数据持久化 Linq语法应用
Linq基础语法 LINQ概述 LINQ(Language Integrated Query,语言集成查询)提供了一种跨数据源和数据格式查询的统一模型. LINQ的组成: LINQ To Object ...
- Java实现 LeetCode 143 重排链表
143. 重排链表 给定一个单链表 L:L0→L1→-→Ln-1→Ln , 将其重新排列后变为: L0→Ln→L1→Ln-1→L2→Ln-2→- 你不能只是单纯的改变节点内部的值,而是需要实际的进行节 ...
- Python爬虫之request +re
什么是爬虫? 它是指向网站发起请求,获取资源后分析并提取有用数据的程序: 爬虫的步骤: 1.发起请求 使用http库向目标站点发起请求,即发送一个Request Request包含:请求头.请求体等 ...
- 从windows到Mac的那些坑
今年入职一家新公司 公司办公统一使用Mac pro,所有国产软件不允许使用,只允许装国外的.开源的软件,,,,(这对一个从来没用过Mac的人来说,可真是头疼了一阵子) 经过几天的摸索,作一个简单的小总 ...
- 哦,Vendor
vendor踩坑笔记: 接过公司里面X平台golang部分的后端后,需要新添加一个业务功能,美滋滋~ 拿过项目一顿写之后后遇到事了. 报错的描述如下: 报错的大意说:方法的入参类型不匹配,我们不能把 ...
- Fiddler13模拟弱网络环境测试
前言现在的Android软件,基本上都会有网络请求,有些APP需要频繁的传输数据时对于网络请求的稳定性和在特殊网络条件下的兼容性有要求,但是我们在测试的时候又很难模拟那种弱网络差网络的情况,今天就给大 ...
- opencl(3)程序、内核
1:程序 1)从上下文中创建程序 cl_program clCreateProgramWithSource( cl_context context, //上下文 cl_uint count, //文本 ...