python库之-------Pandas
包括两个数据结构:DataFrame和Series
官方文档地址:
pandas https://pandas.pydata.org/pandas-docs/stable/index.html
series https://pandas.pydata.org/pandas-docs/stable/reference/series.html
dataframe https://pandas.pydata.org/pandas-docs/stable/reference/frame.html
一、 Pandas简介
1、Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
2、Pandas是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
转自:https://blog.csdn.net/qq_26591517/article/details/80041296
3、Pandas是Python的一个大数据处理模块。Pandas使用一个二维的数据结构DataFrame来表示表格式的数据,相比较于Numpy,Pandas可以存储混合的数据结构,同时使用NaN来表示缺失的数据,而不用像Numpy一样要手工处理缺失的数据,并且Pandas使用轴标签来表示行和列。
DataFrame类:
DataFrame有四个重要的属性:
index:行索引。
columns:列索引。
values:值的二维数组。
name:名字。
原文链接:https://blog.csdn.net/qq_26591517/article/details/80041296
4、pandas和numpy
pandas是python环境下最有名的数据统计包,而DataFrame翻译为数据框,是一种数据组织方式,这么说你可能无法从感性上认识它,举个例子,你大概用过Excel,而它也是一种数据组织和呈现的方式,简单说就是表格,而在在pandas中用DataFrame组织数据,如果你不print DataFrame,你看不到这些数据。
pandas和numpy的区别:
(1)numpy是数值计算的扩展包,panadas是做数据处理。
(2)NumPy简介:N维数组容器NumPy系统是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix))。据说NumPy将Python相当于变成一种免费的更强大的MatLab系统 。
Pandas简介:表格容器 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量快速便捷地处理数据的函数和方法。使Python成为强大而高效的数据分析环境的重要因素之一。
参考:https://blog.csdn.net/yang9520/article/details/79847964
二、Series和DataFrame
pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包。
类似于 Numpy 的核心是 ndarray,pandas 也是围绕着 Series 和 DataFrame 两个核心数据结构展开的 。Series 和 DataFrame 分别对应于一维的序列和二维的表结构。pandas 约定俗成的导入方法如下:
- from pandas import Series,DataFrame
- import pandas as pd
Series:

Series 对象包含两个主要的属性:index 和 values,分别为上例中左右两列。

Series 对象的元素会严格依照给出的 index 构建,这意味着:如果 data 参数是有键值对的,那么只有 index 中含有的键会被使用;以及如果 data 中缺少响应的键,即使给出 NaN 值,这个键也会被添加。
DataFrame:
DataFrame 是一个表格型的数据结构,它含有一组有序的列(类似于 index),每列可以是不同的值类型(不像 ndarray 只能有一个 dtype)。基本上可以把 DataFrame 看成是共享同一个 index 的 Series 的集合。
DataFrame 的构造方法与 Series 类似,只不过可以同时接受多条一维数据源,每一条都会成为单独的一列:

DataFrame.loc([行名称],[列名称])
DataFrame.iloc([行号],[列号])
https://blog.csdn.net/llx1026/article/details/77722608
参考:https://blog.csdn.net/qq_34941023/article/details/53317805
三、总结图
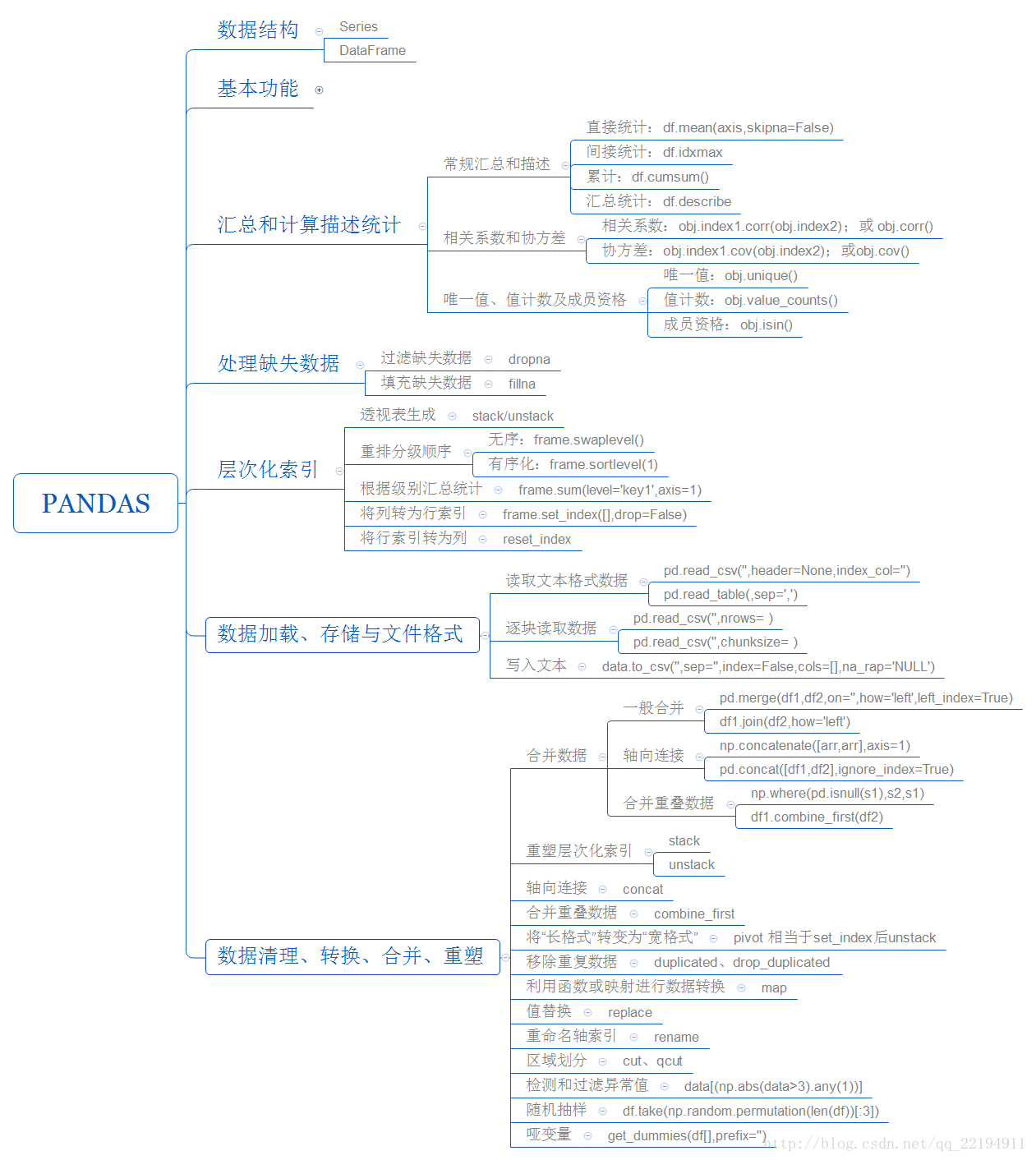
参考:https://www.jianshu.com/p/1b751406a7b6
python库之-------Pandas的更多相关文章
- Python库
--Python库之Pandas库-------- 自主选择学习了Python中的Pandas库,以下是本人对Pandas库的认识: Pandas库是Python最受欢迎的库之一,主要用于数据的操作. ...
- 顶级Python库
绝不能错过的24个顶级Python库 Python有以下三个特点: · 易用性和灵活性 · 全行业高接受度:Python无疑是业界最流行的数据科学语言 · 用于数据科学的Python库的数量优势 事实 ...
- 一文总结数据科学家常用的Python库(上)
概述 这篇文章中,我们挑选了24个用于数据科学的Python库. 这些库有着不同的数据科学功能,例如数据收集,数据清理,数据探索,建模等,接下来我们会分类介绍. 您觉得我们还应该包含哪些Python库 ...
- 总结数据科学家常用的Python库
概述 这篇文章中,我们挑选了24个用于数据科学的Python库. 这些库有着不同的数据科学功能,例如数据收集,数据清理,数据探索,建模等,接下来我们会分类介绍. 您觉得我们还应该包含哪些Python库 ...
- Python之使用Pandas库实现MySQL数据库的读写
本次分享将介绍如何在Python中使用Pandas库实现MySQL数据库的读写.首先我们需要了解点ORM方面的知识. ORM技术 对象关系映射技术,即ORM(Object-Relational ...
- 11个并不广为人知,但值得了解的Python库
这是一篇译文,文中提及了一些不常见但是有用的Python库 原文地址:http://blog.yhathq.com/posts/11-python-libraries-you-might-not-kn ...
- 【Python实战】Pandas:让你像写SQL一样做数据分析(一)
1. 引言 Pandas是一个开源的Python数据分析库.Pandas把结构化数据分为了三类: Series,1维序列,可视作为没有column名的.只有一个column的DataFrame: Da ...
- python 数据处理学习pandas之DataFrame
请原谅没有一次写完,本文是自己学习过程中的记录,完善pandas的学习知识,对于现有网上资料的缺少和利用python进行数据分析这本书部分知识的过时,只好以记录的形势来写这篇文章.最如果后续工作定下来 ...
- Python 库大全
作者:Lingfeng Ai链接:http://www.zhihu.com/question/24590883/answer/92420471来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非 ...
随机推荐
- linux下的hashpump安装
hashpump是linux上的一个进行hash长度拓展攻击的工具 安装: git clone https://github.com/bwall/HashPump apt-get install g+ ...
- mysql6数据库安装与配置
详细步骤可以参考这篇文章 https://www.cnblogs.com/duguangming/p/10623520.html 1.下载并打开mysql6数据库安装文件 2.默认点击下一步 3.点击 ...
- ServiceComb 集成 Shiro 实践|火影专场发布
Shiro简介 Apache Shiro是一款功能强大.易用的轻量级开源Java安全框架,它主要提供认证.鉴权.加密和会话管理等功能.Spring Security可能是业界用的最广泛的安全框架,但是 ...
- vim,neovim 配置文件
插件管理用的是 https://github.com/junegunn/vim-plug 打开网址,会有示例,如何安装它本身,以及一些插件,照做,很容易完成 里面有两个可用的配置文件,cp_vimrc ...
- ZJNU 1067 - 约瑟夫——中级
打表处理(否则Case 1超时) 对m进行枚举,每次枚举进行一次判断 因为好人坏人均为k个,那么只要让下一个死亡的人的位置p保证在1~剩余坏人数量之间即可,不满足则直接break枚举下一个m 实际上对 ...
- JavaSE--类加载器
参考:http://www.importnew.com/6581.html Java 编译器会为虚拟机转换源指令.虚拟机代码存储在以 .class 为扩展名的类文件中,每个类文件都包含某个类或者接口的 ...
- Linux进程的引入
1.什么是进程? (1).进程是一个动态过程而不是静态实物 (2).进程就是程序的一次运行过程,一个静态的可执行程序a.out的一次运行过程(./a.out从运行到结束)就是一个进程. (3).进程控 ...
- idea远程调试tomcat部署项目(windows环境)
1.tomcat启动之前,修改apache-tomcat-8.5.34\bin\catalina.bat文件,设置调试端口 如下设置(windows环境): rem ----------------- ...
- apt源换国内源
vim /etc/apt/sources.list deb http://mirrors.163.com/debian/ jessie main non-free contribdeb http:// ...
- Patroni 修改配置
Patroni 修改配置 背景 使用 Patroni 部署 postgresql 集群的时候,不能单独修改单点的配置,这里需要通过 Patroni 来修改配置. 修改步骤 1. 修改 postgres ...