python库之-------Pandas
包括两个数据结构:DataFrame和Series
官方文档地址:
pandas https://pandas.pydata.org/pandas-docs/stable/index.html
series https://pandas.pydata.org/pandas-docs/stable/reference/series.html
dataframe https://pandas.pydata.org/pandas-docs/stable/reference/frame.html
一、 Pandas简介
1、Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
2、Pandas是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。
转自:https://blog.csdn.net/qq_26591517/article/details/80041296
3、Pandas是Python的一个大数据处理模块。Pandas使用一个二维的数据结构DataFrame来表示表格式的数据,相比较于Numpy,Pandas可以存储混合的数据结构,同时使用NaN来表示缺失的数据,而不用像Numpy一样要手工处理缺失的数据,并且Pandas使用轴标签来表示行和列。
DataFrame类:
DataFrame有四个重要的属性:
index:行索引。
columns:列索引。
values:值的二维数组。
name:名字。
原文链接:https://blog.csdn.net/qq_26591517/article/details/80041296
4、pandas和numpy
pandas是python环境下最有名的数据统计包,而DataFrame翻译为数据框,是一种数据组织方式,这么说你可能无法从感性上认识它,举个例子,你大概用过Excel,而它也是一种数据组织和呈现的方式,简单说就是表格,而在在pandas中用DataFrame组织数据,如果你不print DataFrame,你看不到这些数据。
pandas和numpy的区别:
(1)numpy是数值计算的扩展包,panadas是做数据处理。
(2)NumPy简介:N维数组容器NumPy系统是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix))。据说NumPy将Python相当于变成一种免费的更强大的MatLab系统 。
Pandas简介:表格容器 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量快速便捷地处理数据的函数和方法。使Python成为强大而高效的数据分析环境的重要因素之一。
参考:https://blog.csdn.net/yang9520/article/details/79847964
二、Series和DataFrame
pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包。
类似于 Numpy 的核心是 ndarray,pandas 也是围绕着 Series 和 DataFrame 两个核心数据结构展开的 。Series 和 DataFrame 分别对应于一维的序列和二维的表结构。pandas 约定俗成的导入方法如下:
- from pandas import Series,DataFrame
- import pandas as pd
Series:

Series 对象包含两个主要的属性:index 和 values,分别为上例中左右两列。

Series 对象的元素会严格依照给出的 index 构建,这意味着:如果 data 参数是有键值对的,那么只有 index 中含有的键会被使用;以及如果 data 中缺少响应的键,即使给出 NaN 值,这个键也会被添加。
DataFrame:
DataFrame 是一个表格型的数据结构,它含有一组有序的列(类似于 index),每列可以是不同的值类型(不像 ndarray 只能有一个 dtype)。基本上可以把 DataFrame 看成是共享同一个 index 的 Series 的集合。
DataFrame 的构造方法与 Series 类似,只不过可以同时接受多条一维数据源,每一条都会成为单独的一列:

DataFrame.loc([行名称],[列名称])
DataFrame.iloc([行号],[列号])
https://blog.csdn.net/llx1026/article/details/77722608
参考:https://blog.csdn.net/qq_34941023/article/details/53317805
三、总结图
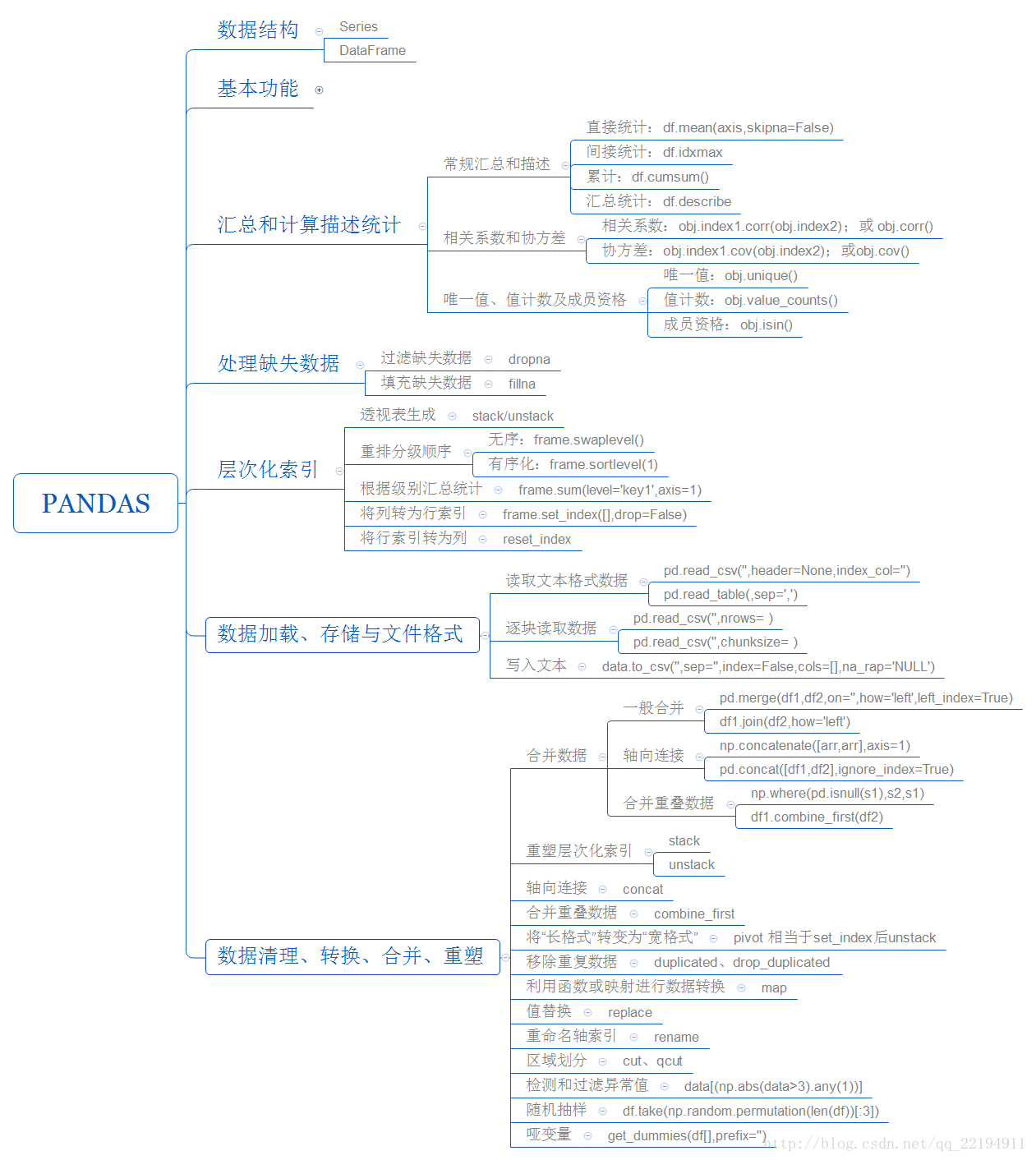
参考:https://www.jianshu.com/p/1b751406a7b6
python库之-------Pandas的更多相关文章
- Python库
--Python库之Pandas库-------- 自主选择学习了Python中的Pandas库,以下是本人对Pandas库的认识: Pandas库是Python最受欢迎的库之一,主要用于数据的操作. ...
- 顶级Python库
绝不能错过的24个顶级Python库 Python有以下三个特点: · 易用性和灵活性 · 全行业高接受度:Python无疑是业界最流行的数据科学语言 · 用于数据科学的Python库的数量优势 事实 ...
- 一文总结数据科学家常用的Python库(上)
概述 这篇文章中,我们挑选了24个用于数据科学的Python库. 这些库有着不同的数据科学功能,例如数据收集,数据清理,数据探索,建模等,接下来我们会分类介绍. 您觉得我们还应该包含哪些Python库 ...
- 总结数据科学家常用的Python库
概述 这篇文章中,我们挑选了24个用于数据科学的Python库. 这些库有着不同的数据科学功能,例如数据收集,数据清理,数据探索,建模等,接下来我们会分类介绍. 您觉得我们还应该包含哪些Python库 ...
- Python之使用Pandas库实现MySQL数据库的读写
本次分享将介绍如何在Python中使用Pandas库实现MySQL数据库的读写.首先我们需要了解点ORM方面的知识. ORM技术 对象关系映射技术,即ORM(Object-Relational ...
- 11个并不广为人知,但值得了解的Python库
这是一篇译文,文中提及了一些不常见但是有用的Python库 原文地址:http://blog.yhathq.com/posts/11-python-libraries-you-might-not-kn ...
- 【Python实战】Pandas:让你像写SQL一样做数据分析(一)
1. 引言 Pandas是一个开源的Python数据分析库.Pandas把结构化数据分为了三类: Series,1维序列,可视作为没有column名的.只有一个column的DataFrame: Da ...
- python 数据处理学习pandas之DataFrame
请原谅没有一次写完,本文是自己学习过程中的记录,完善pandas的学习知识,对于现有网上资料的缺少和利用python进行数据分析这本书部分知识的过时,只好以记录的形势来写这篇文章.最如果后续工作定下来 ...
- Python 库大全
作者:Lingfeng Ai链接:http://www.zhihu.com/question/24590883/answer/92420471来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非 ...
随机推荐
- 【mac相关bash文件】
mac 下 关于 .bashrc 和 .bash_profile 1.首先.bashrc 可能自带的系统里没有这个文件. 2.bash_profile 里边一半放的是PATH相关. 3. .bash ...
- Dart异步编程-future
Dart异步编程包含两部分:Future和Stream 该篇文章中介绍Future 异步编程:Futures Dart是一个单线程编程语言.如果任何代码阻塞线程执行都会导致程序卡死.异步编程防止出现阻 ...
- Ubuntu16.04编译tensorflow的C++接口
原文:https://www.bearoom.xyz/2018/09/27/ubuntu1604buildtf4cpp/ 之前有一篇介绍到在windows下利用VS2015编译tensorflow的C ...
- 为什么常用 Map<> map = new HashMap()
在初学Java的时候,经常能看到教材上的写法,使用了接口Map来引用一个map,而不是它的具体实现,那么这样做的好处是什么呢? <Effective Java>第52条:通过接口引用对象 ...
- tensorflow函数解析:Session.run和Tensor.eval
原问题链接: http://stackoverflow.com/questions/33610685/in-tensorflow-what-is-the-difference-between-sess ...
- 产品对话 | 愿云原生不再只有Kubernete
从2013年,云原生(Cloud Native)的概念由 Pivotal 的 MattStine 首次提出,到现在,其技术细节不断得到社区的完善.云原生逐渐演变出包括 DevOps.持续交付.微服务. ...
- MySQL--MySQL 日志
在 MySQL中,有 4 种不同的日志,分别是错误日志.二进制日志(BINLOG 日志).查询日志和慢查询日志. 1.错误日志 错误日志是 MySQL 中最重要的日志之一,它记录了当 mysqld 启 ...
- 了解Kafka生产者
了解Kafka生产者 之前对kafka的整体架构有浅显的了解,这次正好有时间,准备深入了解一下kafka,首先先从数据的生产者开始吧. 生产者的整体架构 可以看到整个生产者进程主要由两个线程进 ...
- \_\_getattribute\_\_
__getattribute__ 一.__getattr__ 不存在的属性访问,触发__getattr__ class Foo: def __init__(self, x): self.x = x d ...
- 二、NOSQL之Memcached缓存服务实战精讲第一部
1.Memcached是一套数据缓存系统或软件. 用于在动态应用系统中缓存数据库的数据,减少数据库的访问压力,达到提升网站系统性能的目的:Memcached在企业应用场景中一般是用来作为数据库的cac ...