CVPR2020|3D-VID:基于LiDar Video信息的3D目标检测框架
作者:蒋天园Date:2020-04-18
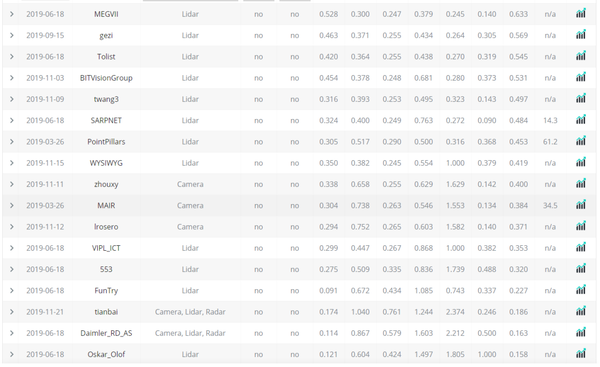
- 当前的基于LiDar输入的目标检测网络都是只使用了单帧的信息,都没有使用连续点云之间的时空信息。所以本文作者提出了一种处理点云序列的end2end的online的视频检测方法。
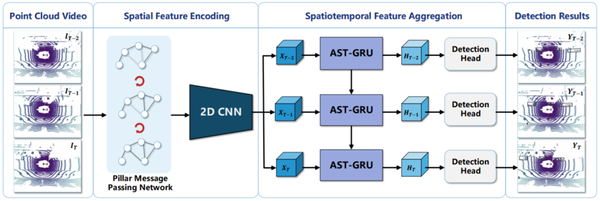
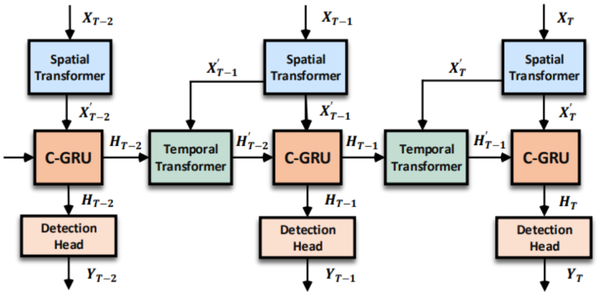
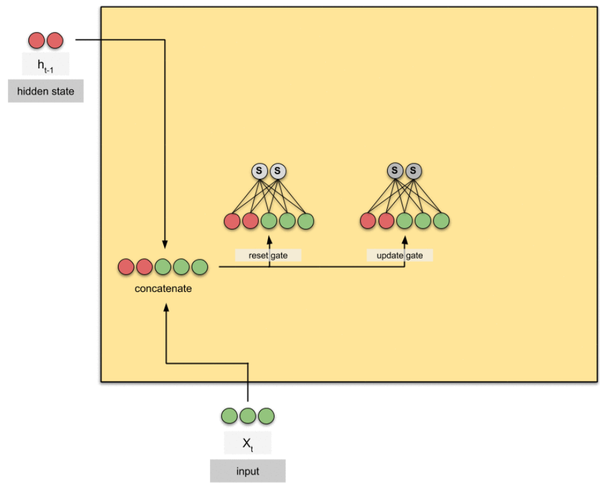
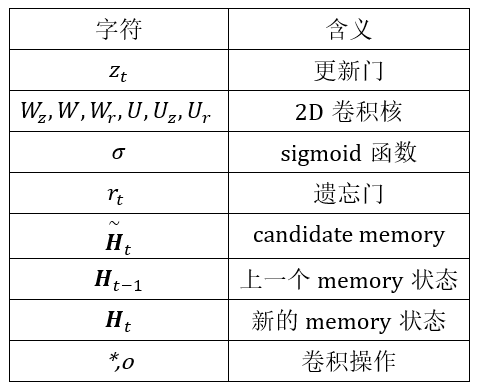
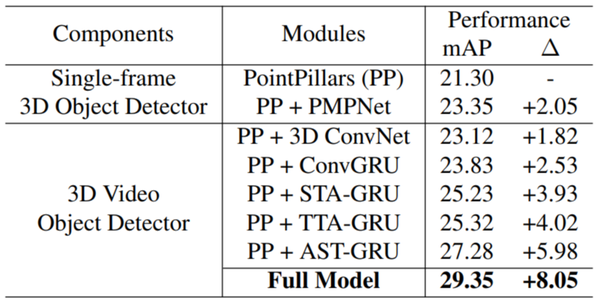
- 本文提出的模型由空间特征编码模块和时空特征融合模块两部分组成。这里的空间特征编码模块——PMPNet(PillarMessage Passing Network)用于编码独立的每一帧的点云特征,该模块通过迭代消息传递,自适应地从相邻节点处为该pillarnode收集节点信息,有效地扩大了该pillarnode的感受野。时空特征融合模块则是采用的时空注意力结合GRU的设计(AST-GRU)来整合时空信息,该模块通过一个attentivememory gate来加强传统的ConvGRU。其中AST-GRU模块又包含了一个空间注意力模块(STA)和TTA模块(TemporalTransformer Attention ),使得AST-GRU可以注意到前景物体和配准动态物体。
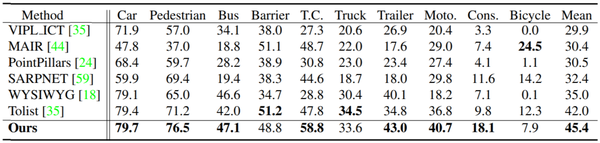
- 在nuscence上得到了sota的效果
- point cloud video的定义点云视频是一系列点云帧的集合,在数据集Nuscence中,采用的32线每一秒可以捕获20帧的点云的激光雷达。
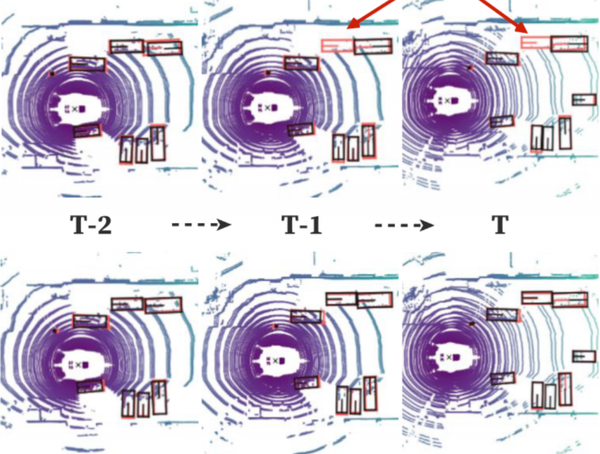
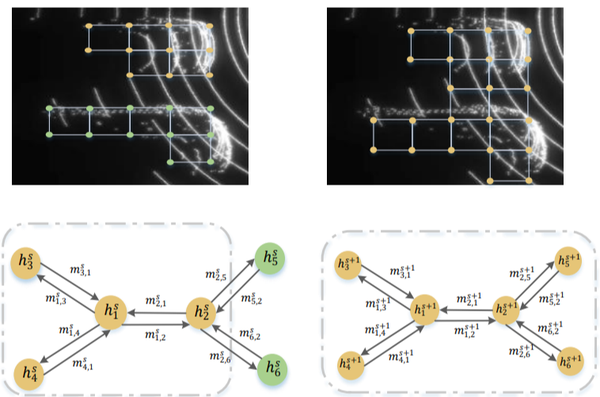
- 单帧检测方法的弊端如果采用单帧图像直接处理就受到单帧图像就必须受到单帧图像稀疏性过大的影响,再严重一点,距离和遮挡都会成为单帧检测方法的重大阻碍。如下图所示,最上一层的检测经常处才能False-negative的结果,但是本文提出的online3D video 检测方法就可以做到更好的效果。这是因为point cloud video具有更加丰富的物体特征。 当前比较流行的一些单帧检测方法有可分为voxel-based的voxelnet、second、pointpillars和point-based的pointrcnn等方法,在本文中,作者也是采用的这种Pillar划分的方式提取特征,但是这种方法只会关注局部特征。所以作者对此提出了graph-based的方法PMPnet
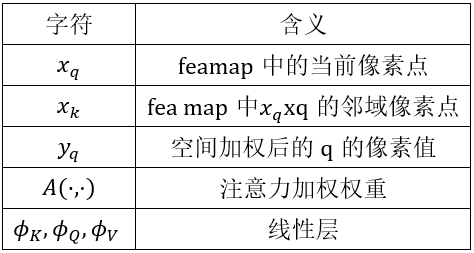
- 核心问题 (1)构建3D video 目标检测的关键问题在于如何对连续的时空特征信息进行建模表示,本文中,作者提出了融合graph-based空间编码特征的模块并结合时空注意力感知模块,来捕获视频一致性。 (2)上文提到作者为了改变pillars特征提取仅仅提取一个Pillar中的特征的问题,自己设计了PMPnet,该网络把每一个非空的pillar当做图的一个节点,通过mesh从旁边节点融合特征的方式来扩大感受野,因此PMPNet通过在K-NNgraph中采用迭代的方式可以深度挖掘不同pillar节点之间的相对关系,该网络是在同一帧的点云中进行空间的特征融合。 (3)上面的PMPnet仅仅在同一帧的空间中提取到感受野更多的特征信息,然后将这些单帧的特征在作者设计的第二个网络结构AST-GRU中进行融合,ConvGRU这一篇ICLR16年的文章证实了在2Dvideo中ConvGRU是非常有效的,作者设计的AST-GRU则是把该工作通过一个注意力内存门机制来捕获连续帧点云之间的依赖关系来扩展到三维点云中处理中。 (4)在俯视图下,前景物体仅仅只占一小部分区域,背景点占据了大部分的区域,这会使得在迭代过程中,背景噪声会越来越大,因此作者采用了空间注意力模块来缓解背景噪声并强调前景物体。(5)更新memory时,旧的空间特征和新的输入之间存在没配准的问题,如果是静态物体,可以采用ego-pose信息配准,但是具有很大运动幅度的动态物体则是不能的,为了解决这问题,作者采用了短暂注意力机制(TTA)模块,自适应的捕捉连续帧中的运动关系。
- 整体设计作者首先通过PMPNet模块自适应扩大感受野的提取每一帧的空间特征,再将输出的特征序列送入AST-GRU模块。
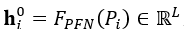
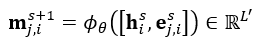
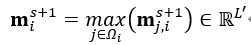
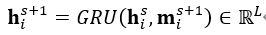
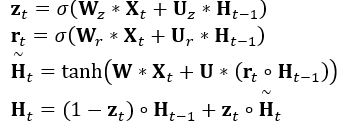
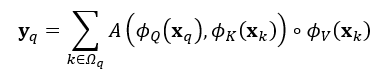
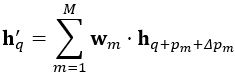

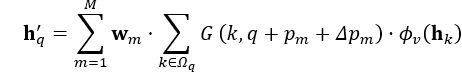
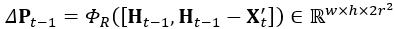
- 1000个场景,每个场景20s,这些场景使用人类专家进行了仔细注释
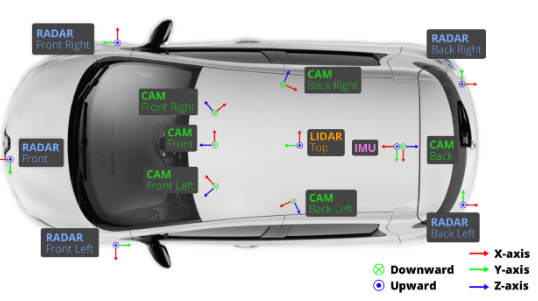
- 传感器安装位置和采集的数据命名:
- 数据注释:
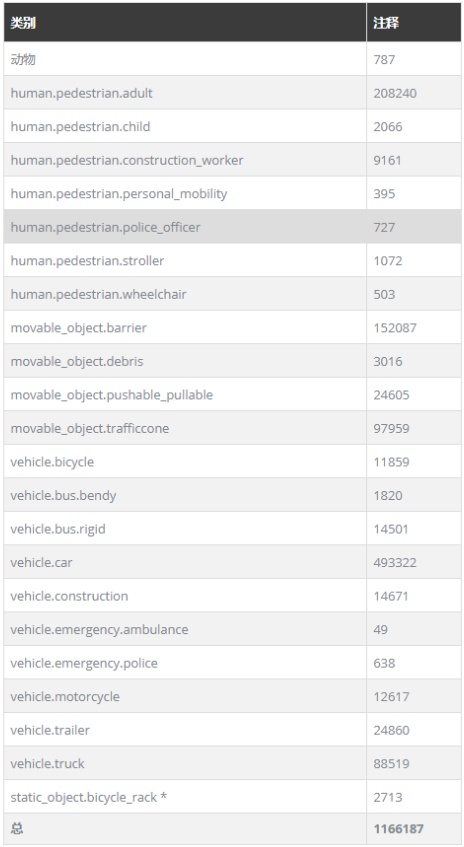
- 数量一共有1000多个场景,其中700个提供为训练,150个场景作为测试,大概是KITTI的7倍左右视频中关键帧每隔0.5s标注,由10个非关键帧融合得到。信息包含为,其中最后一个信息是KITTI不含有的,表示离关键帧的时间从0~0.45.
- 对于关键帧,输入场景大小设置为[−50,50] × [−50, 50] ×[−5, 3],Pillar的划分为[0.5×0.5]。
- 点云数量的输入为16384,从原始的2w+的点云中采样得到,每个pillar中最多包含点云数量为60
- 最初的输入维度是5,在GNN中的维度变为64
- 最终在backbone中的fea map为100 × 100 × 384(和voxelnet一样的两层concat)
CVPR2020|3D-VID:基于LiDar Video信息的3D目标检测框架的更多相关文章
- ICCV2019论文点评:3D Object Detect疏密度点云三维目标检测
ICCV2019论文点评:3D Object Detect疏密度点云三维目标检测 STD: Sparse-to-Dense 3D Object Detector for Point Cloud 论文链 ...
- [OpenCV]基于特征匹配的实时平面目标检测算法
一直想基于传统图像匹配方式做一个融合Demo,也算是对上个阶段学习的一个总结. 由此,便采购了一个摄像头,在此基础上做了实时检测平面目标的特征匹配算法. 代码如下: # coding: utf-8 ' ...
- 基于候选区域的深度学习目标检测算法R-CNN,Fast R-CNN,Faster R-CNN
参考文献 [1]Rich feature hierarchies for accurate object detection and semantic segmentation [2]Fast R-C ...
- CVPR2020论文解读:3D Object Detection三维目标检测
CVPR2020论文解读:3D Object Detection三维目标检测 PV-RCNN:Point-Voxel Feature Se tAbstraction for 3D Object Det ...
- 3D惯导Lidar SLAM
3D惯导Lidar SLAM LIPS: LiDAR-Inertial 3D Plane SLAM 摘要 本文提出了最*点*面表示的形式化方法,并分析了其在三维室内同步定位与映射中的应用.提出了一个利 ...
- ILSVRC2016目标检测任务回顾——视频目标检测(VID)
转自知乎<深度学习大讲堂> 雷锋网(公众号:雷锋网)按:本文作者王斌,中科院计算所前瞻研究实验室跨媒体计算组博士生,导师张勇东研究员.2016年在唐胜副研究员的带领下,作为计算所MCG-I ...
- CVPR2020:三维实例分割与目标检测
CVPR2020:三维实例分割与目标检测 Joint 3D Instance Segmentation and Object Detection for Autonomous Driving 论文地址 ...
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.object detection要解决的问题就是物体在哪里,是什么这整个流程的问题.然而,这个问题 ...
- (转)基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
object detection我的理解,就是在给定的图片中精确找到物体所在位置,并标注出物体的类别.object detection要解决的问题就是物体在哪里,是什么这整个流程的问题.然而,这个问题 ...
随机推荐
- Effective Python读书笔记
有些位置可能翻译理解的不到位,各位看官如有疑问,欢迎留言赐教. Pythonic Thinking 大家经常用Pythonic来形容python语法风格的编程方式:简单优美,没有之一:通过import ...
- Blazor-断开连接后重新加载浏览器
在大多数情况下,Blazor将与以前相同的线路上重新连接到服务器.但有时无法重新连接,需要重新加载web浏览器才能使网站重新工作.如果服务器回收应用程序池,则需要手动重新加载页面在没有调试的情况下在I ...
- GPP(Group Policy Preference)组策略偏好漏洞利用
总结与反思: GPP中管理员给域成员添加的账号信息存在xml,可以直接破解拿到账号密码. Windows Sever 2008 的组策略选项(GPP)是一个新引入的插件,方便管理员管理的同时也引入了安 ...
- Django配置站点
一 修改hosts文件 """ hosts文件涉及的dns解析 1.找到hosts文件 windows: C:\Windows\System32\drivers\etc\ ...
- POJ1523 Tarjan求割点以及删除割点之后强连通分量的数量
题目链接:http://poj.org/problem?id=1523 SPF:A Single Point of Failure也就是割点(一个点导致网络之间的不连通),由于给出的图是无向图,所以只 ...
- 【转载】因为我们是OIer
我们是OIer, 所以我们 不用在跑道上挥汗如雨: 不用在球场上健步如飞: 更不用在没事的时候, 经受非人的体能训练-- 但是, 我们却要把头脑 高速运转, 还要接受一大堆 大学生也只是 " ...
- OpenCV-Python 如何使用背景分离方法 | 四十六
目标 背景分离(BS)是一种通过使用静态相机来生成前景掩码(即包含属于场景中的移动对象像素的二进制图像)的常用技术. 顾名思义,BS计算前景掩码,在当前帧与背景模型之间执行减法运算,其中包含场景的静态 ...
- 不可思议的hexo,五分钟教你免费搭一个高逼格技术博客
引言 作为程序员拥有一个属于自己的个人技术博客,绝对是百利无一害的事,不仅方便出门装b,面试时亮出博客地址也会让面试官对你的好感度倍增.经常能在很多大佬的技术文章的文末,看到这样一句话: " ...
- 分库分表实践-Sharding-JDBC
最近一段时间在研究分库分表的一些问题,正好周末有点时间就简单做下总结,也方便自己以后查看. 关于为什么要做分库分表,什么是水平分表,垂直分表等概念,相信大家都知道,这里就不在赘述了. 本文只讲述使用S ...
- Java中如何调用静态方法
Java中如何调用静态方法: 1.如果想要调用的静态方法在本类中,可直接使用方法名调用 2.调用其他类的静态方法,可使用类名.方法名调用 关于静态方法能被什么调用 1.实例方法 2.静态发放