数据结构和算法(Golang实现)(17)常见数据结构-树
树
树是一种比较高级的基础数据结构,由n个有限节点组成的具有层次关系的集合。
树的定义:
- 有节点间的层次关系,分为父节点和子节点。
- 有唯一一个根节点,该根节点没有父节点。
- 除了根节点,每个节点有且只有一个父节点。
- 每一个节点本身以及它的后代也是一棵树,是一个递归的结构。
- 没有后代的节点称为叶子节点,没有节点的树称为空树。
二叉树:每个节点最多只有两个儿子节点的树。
满二叉树:叶子节点与叶子节点之间的高度差为0的二叉树,即整颗树是满的,树呈满三角形结构。在国外的定义,非叶子节点儿子都是满的树就是满二叉树。我们以国内为准。
完全二叉树:完全二叉树是由满二叉树而引出来的,设二叉树的深度为k,除第k层外,其他各层的节点数都达到最大值,且第k层所有的节点都连续集中在最左边。
树根据儿子节点的多寡,有二叉树,三叉树,四叉树等,我们这里主要介绍二叉树。
一、二叉树的数学特征
- 高度为
h≥0的二叉树至少有h+1个结点,比如最不平衡的二叉树就是退化的线性链表结构,所有的节点都只有左儿子节点,或者所有的节点都只有右儿子节点。 - 高度为
h≥0的二叉树至多有2^h+1个节点,比如这颗树是满二叉树。 - 含有
n≥1个结点的二叉树的高度至多为n-1,由1退化的线性链表可以反推。 - 含有
n≥1个结点的二叉树的高度至少为logn,由2满二叉树可以反推。 - 在二叉树的第
i层,至多有2^(i-1)个节点,比如该层是满的。
二、二叉树的实现
二叉树可以使用链表来实现。如下:
// 二叉树
type TreeNode struct {
Data string // 节点用来存放数据
Left *TreeNode // 左子树
Right *TreeNode // 右字树
}
当然,数组也可以用来表示二叉树,一般用来表示完全二叉树。
对于一颗有n个节点的完全二叉树,从上到下,从左到右进行序号编号,对于任一个节点,编号i=0表示树根节点,编号i的节点的左右儿子节点编号分别为:2i+1,2i+2,父亲节点编号为:i/2,整除操作去掉小数。
如图是一颗完全二叉树,数组的表示:
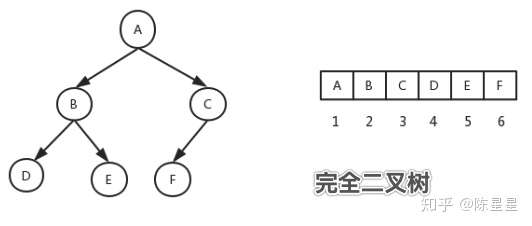
我们一般使用二叉树来实现查找的功能,所以树节点结构体里存放数据的Data字段。
三、遍历二叉树
构建一颗树后,我们希望遍历它,有四种遍历方法:
- 先序遍历:先访问根节点,再访问左子树,最后访问右子树。
- 后序遍历:先访问左子树,再访问右子树,最后访问根节点。
- 中序遍历:先访问左子树,再访问根节点,最后访问右子树。
- 层次遍历:每一层从左到右访问每一个节点。
先序,后序和中序遍历较简单,代码如下:
package main
import (
"fmt"
)
// 二叉树
type TreeNode struct {
Data string // 节点用来存放数据
Left *TreeNode // 左子树
Right *TreeNode // 右字树
}
// 先序遍历
func PreOrder(tree *TreeNode) {
if tree == nil {
return
}
// 先打印根节点
fmt.Print(tree.Data, " ")
// 再打印左子树
PreOrder(tree.Left)
// 再打印右字树
PreOrder(tree.Right)
}
// 中序遍历
func MidOrder(tree *TreeNode) {
if tree == nil {
return
}
// 先打印左子树
MidOrder(tree.Left)
// 再打印根节点
fmt.Print(tree.Data, " ")
// 再打印右字树
MidOrder(tree.Right)
}
// 后序遍历
func PostOrder(tree *TreeNode) {
if tree == nil {
return
}
// 先打印左子树
MidOrder(tree.Left)
// 再打印右字树
MidOrder(tree.Right)
// 再打印根节点
fmt.Print(tree.Data, " ")
}
func main() {
t := &TreeNode{Data: "A"}
t.Left = &TreeNode{Data: "B"}
t.Right = &TreeNode{Data: "C"}
t.Left.Left = &TreeNode{Data: "D"}
t.Left.Right = &TreeNode{Data: "E"}
t.Right.Left = &TreeNode{Data: "F"}
fmt.Println("先序排序:")
PreOrder(t)
fmt.Println("\n中序排序:")
MidOrder(t)
fmt.Println("\n后序排序")
PostOrder(t)
}
表示将以下结构的树进行遍历:
结果如下:
先序排序:
A B D E C F
中序排序:
D B E A F C
后序排序
D B E F C A
层次遍历较复杂,用到一种名叫广度遍历的方法,需要使用辅助的先进先出的队列。
- 先将树的根节点放入队列。
- 从队列里面
remove出节点,先打印节点值,如果该节点有左子树节点,左子树入栈,如果有右子树节点,右子树入栈。 - 重复2,直到队列里面没有元素。
核心逻辑如下:
func LayerOrder(treeNode *TreeNode) {
if treeNode == nil {
return
}
// 新建队列
queue := new(LinkQueue)
// 根节点先入队
queue.Add(treeNode)
for queue.size > 0 {
// 不断出队列
element := queue.Remove()
// 先打印节点值
fmt.Print(element.Data, " ")
// 左子树非空,入队列
if element.Left != nil {
queue.Add(element.Left)
}
// 右子树非空,入队列
if element.Right != nil {
queue.Add(element.Right)
}
}
}
完整代码:
package main
import (
"fmt"
"sync"
)
// 二叉树
type TreeNode struct {
Data string // 节点用来存放数据
Left *TreeNode // 左子树
Right *TreeNode // 右字树
}
func LayerOrder(treeNode *TreeNode) {
if treeNode == nil {
return
}
// 新建队列
queue := new(LinkQueue)
// 根节点先入队
queue.Add(treeNode)
for queue.size > 0 {
// 不断出队列
element := queue.Remove()
// 先打印节点值
fmt.Print(element.Data, " ")
// 左子树非空,入队列
if element.Left != nil {
queue.Add(element.Left)
}
// 右子树非空,入队列
if element.Right != nil {
queue.Add(element.Right)
}
}
}
// 链表节点
type LinkNode struct {
Next *LinkNode
Value *TreeNode
}
// 链表队列,先进先出
type LinkQueue struct {
root *LinkNode // 链表起点
size int // 队列的元素数量
lock sync.Mutex // 为了并发安全使用的锁
}
// 入队
func (queue *LinkQueue) Add(v *TreeNode) {
queue.lock.Lock()
defer queue.lock.Unlock()
// 如果栈顶为空,那么增加节点
if queue.root == nil {
queue.root = new(LinkNode)
queue.root.Value = v
} else {
// 否则新元素插入链表的末尾
// 新节点
newNode := new(LinkNode)
newNode.Value = v
// 一直遍历到链表尾部
nowNode := queue.root
for nowNode.Next != nil {
nowNode = nowNode.Next
}
// 新节点放在链表尾部
nowNode.Next = newNode
}
// 队中元素数量+1
queue.size = queue.size + 1
}
// 出队
func (queue *LinkQueue) Remove() *TreeNode {
queue.lock.Lock()
defer queue.lock.Unlock()
// 队中元素已空
if queue.size == 0 {
panic("over limit")
}
// 顶部元素要出队
topNode := queue.root
v := topNode.Value
// 将顶部元素的后继链接链上
queue.root = topNode.Next
// 队中元素数量-1
queue.size = queue.size - 1
return v
}
// 队列中元素数量
func (queue *LinkQueue) Size() int {
return queue.size
}
func main() {
t := &TreeNode{Data: "A"}
t.Left = &TreeNode{Data: "B"}
t.Right = &TreeNode{Data: "C"}
t.Left.Left = &TreeNode{Data: "D"}
t.Left.Right = &TreeNode{Data: "E"}
t.Right.Left = &TreeNode{Data: "F"}
fmt.Println("\n层次排序")
LayerOrder(t)
}
输出:
层次排序
A B C D E F
系列文章入口
我是陈星星,欢迎阅读我亲自写的 数据结构和算法(Golang实现),文章首发于 阅读更友好的GitBook。
- 数据结构和算法(Golang实现)(1)简单入门Golang-前言
- 数据结构和算法(Golang实现)(2)简单入门Golang-包、变量和函数
- 数据结构和算法(Golang实现)(3)简单入门Golang-流程控制语句
- 数据结构和算法(Golang实现)(4)简单入门Golang-结构体和方法
- 数据结构和算法(Golang实现)(5)简单入门Golang-接口
- 数据结构和算法(Golang实现)(6)简单入门Golang-并发、协程和信道
- 数据结构和算法(Golang实现)(7)简单入门Golang-标准库
- 数据结构和算法(Golang实现)(8.1)基础知识-前言
- 数据结构和算法(Golang实现)(8.2)基础知识-分治法和递归
- 数据结构和算法(Golang实现)(9)基础知识-算法复杂度及渐进符号
- 数据结构和算法(Golang实现)(10)基础知识-算法复杂度主方法
- 数据结构和算法(Golang实现)(11)常见数据结构-前言
- 数据结构和算法(Golang实现)(12)常见数据结构-链表
- 数据结构和算法(Golang实现)(13)常见数据结构-可变长数组
- 数据结构和算法(Golang实现)(14)常见数据结构-栈和队列
- 数据结构和算法(Golang实现)(15)常见数据结构-列表
- 数据结构和算法(Golang实现)(16)常见数据结构-字典
- 数据结构和算法(Golang实现)(17)常见数据结构-树
- 数据结构和算法(Golang实现)(18)排序算法-前言
- 数据结构和算法(Golang实现)(19)排序算法-冒泡排序
- 数据结构和算法(Golang实现)(20)排序算法-选择排序
- 数据结构和算法(Golang实现)(21)排序算法-插入排序
- 数据结构和算法(Golang实现)(22)排序算法-希尔排序
- 数据结构和算法(Golang实现)(23)排序算法-归并排序
- 数据结构和算法(Golang实现)(24)排序算法-优先队列及堆排序
- 数据结构和算法(Golang实现)(25)排序算法-快速排序
- 数据结构和算法(Golang实现)(26)查找算法-哈希表
- 数据结构和算法(Golang实现)(27)查找算法-二叉查找树
- 数据结构和算法(Golang实现)(28)查找算法-AVL树
- 数据结构和算法(Golang实现)(29)查找算法-2-3树和左倾红黑树
- 数据结构和算法(Golang实现)(30)查找算法-2-3-4树和普通红黑树
数据结构和算法(Golang实现)(17)常见数据结构-树的更多相关文章
- 数据结构和算法(Golang实现)(11)常见数据结构-前言
常见数据结构及算法 数据结构主要用来组织数据,也作为数据的容器,载体. 各种各样的算法,都需要使用一定的数据结构来组织数据. 常见的典型数据结构有: 链表 栈和队列 树 图 上述可以延伸出各种各样的术 ...
- 数据结构和算法(Golang实现)(12)常见数据结构-链表
链表 讲数据结构就离不开讲链表.因为数据结构是用来组织数据的,如何将一个数据关联到另外一个数据呢?链表可以将数据和数据之间关联起来,从一个数据指向另外一个数据. 一.链表 定义: 链表由一个个数据节点 ...
- 数据结构和算法(Golang实现)(13)常见数据结构-可变长数组
可变长数组 因为数组大小是固定的,当数据元素特别多时,固定的数组无法储存这么多的值,所以可变长数组出现了,这也是一种数据结构.在Golang语言中,可变长数组被内置在语言里面:切片slice. sli ...
- 数据结构和算法(Golang实现)(14)常见数据结构-栈和队列
栈和队列 一.栈 Stack 和队列 Queue 我们日常生活中,都需要将物品排列,或者安排事情的先后顺序.更通俗地讲,我们买东西时,人太多的情况下,我们要排队,排队也有先后顺序,有些人早了点来,排完 ...
- 数据结构和算法(Golang实现)(15)常见数据结构-列表
列表 一.列表 List 我们又经常听到列表 List数据结构,其实这只是更宏观的统称,表示存放数据的队列. 列表List:存放数据,数据按顺序排列,可以依次入队和出队,有序号关系,可以取出某序号的数 ...
- 数据结构和算法(Golang实现)(16)常见数据结构-字典
字典 我们翻阅书籍时,很多时候都要查找目录,然后定位到我们要的页数,比如我们查找某个英文单词时,会从英语字典里查看单词表目录,然后定位到词的那一页. 计算机中,也有这种需求. 一.字典 字典是存储键值 ...
- 数据结构和算法(Golang实现)(25)排序算法-快速排序
快速排序 快速排序是一种分治策略的排序算法,是由英国计算机科学家Tony Hoare发明的, 该算法被发布在1961年的Communications of the ACM 国际计算机学会月刊. 注:A ...
- 数据结构和算法(Golang实现)(1)简单入门Golang-前言
数据结构和算法在计算机科学里,有非常重要的地位.此系列文章尝试使用 Golang 编程语言来实现各种数据结构和算法,并且适当进行算法分析. 我们会先简单学习一下Golang,然后进入计算机程序世界的第 ...
- 数据结构和算法(Golang实现)(2)简单入门Golang-包、变量和函数
包.变量和函数 一.举个例子 现在我们来建立一个完整的程序main.go: // Golang程序入口的包名必须为 main package main // import "golang&q ...
随机推荐
- Redis详解(一)
redis简介 redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多 包括string(字符串).list(链表).set(集合).zset(sor ...
- 一文带你熟悉SpringIOC
Spring的IOC: IOC是Spring的一个核心组件,理解IOC是迈向Spring大门的重要一步 现实生活中,我们写字用的笔会有多种颜色,为了做不同的标记,需要用不同颜色的笔.如果只是使用一两种 ...
- Shell中的参数传递
原文链接 我们先来定义一个方法 function methodName() { paramName1=$1 paramName2=$2 paramName3=$3 # 依此类推,参数是从1开始标号,而 ...
- masql数据库的表查询
昨日回顾 表与表之间建关系 一对多 换位思考 图书与出版社 先站在左表: 考虑左表的多条数据能否对应右表的一条数据 翻译:多本书能否被一个出版社出版 可以! 注意:单站在一张得出的表关系并不能明确两张 ...
- hdu1856 并查集
题目链接:http://icpc.njust.edu.cn/Problem/Hdu/1856/ 题目就是要求并查集中各树的大小的最大值,我们只要在根节点处存树的大小就可以,合并也是合并根节点的数,最后 ...
- shell脚本的函数介绍和使用案例
#前言:今天我们来聊聊shell脚本中的函数知识,看一下函数的优势,执行过程和相关的使用案例,我们也来看一下shell和python的函数书写方式有什么不同 #简介 .函数也具有别名类似的功能 .函数 ...
- 【狂神说】JAVA Mybatis 笔记+源码
简介 自学的[狂神JAVA]MyBatis GitHub源码: https://github.com/Donkequan/Mybatis-Study 分享自写源码和笔记 配置用的 jdk13.0.2 ...
- sqoop面试题
1.1 Sqoop 在工作中的定位是会用就行1.1.1 Sqoop导入数据到hdfs中的参数 /opt/module/sqoop/bin/sqoop import \ --connect \ # 特殊 ...
- Hive的数据模型及各模块的应用场景
Hive的数据模型 Hive数据模型.png 数据模型组成及应用场景 Hive的数据模型主要有:database.table.partition.bucket四部分: 数据模型之database ...
- test命令的使用以及判断语法
test命令 Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值.字符和文件三个方面的测试. 语法:test EXPRESSION 或者 [ EXPRESSION ] 字符串判断( ...