DPDK Mempool 库原理(学习笔记)
1 前置知识点学习(了解)
从CPU到实际的存储节点,依据层级划分:Channel > DIMM > Rank > Chip > Bank > Row /Column
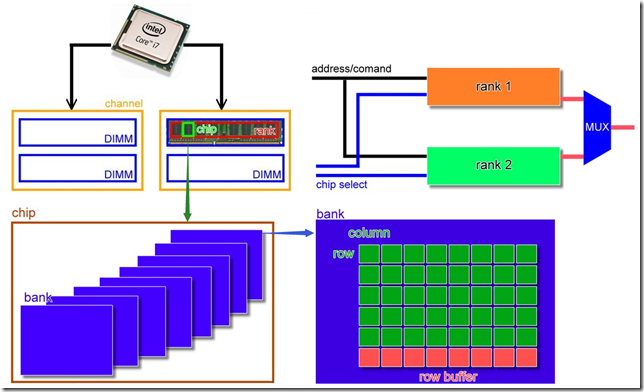
1.1 channel
CPU到内存的通路是channel,每个channel对应一个CPU的内存控制器,每个channel可以配有多个DIMM。
双通道:CPU外核或北桥有两个内存控制器,每个控制器控制一个内存通道。理论上内存带宽增加一倍。
四通道同理。
1.2 DIMM
全称Dual-Inline-Memory-Modules(双列直插式存储模块),是目前最常见的内存模块( 可以理解为内存条)。
以前的主机是直接将存储芯片(chip)插在主板上的,然后发展出SIMM(Single In-line Memory Module),将多个chip焊在一片电路板上,成为内存模块,再将它插到主板上。
1.3 Rank
DIMM上一部分或所有chip组成一个rank(64bit),因此内存至少需要有16片4bit的chip或者8bit的chip(不存在4bit和8bit芯片混搭的情况)。
内存控制器只允许CPU每次与内存进行一组64bits的数据交换,对应的就是一个rank。rank也可以理解为连接到同一个CS(chip select)的一组chip。
rank分类:
- Single-Rank(1R),要动用到DIMM上所有的chip,这些chip由同一个片选信号控制。
- Double-Rank(2R),产生2个64位rank,由2个片选信号控制,这2个片选信号是交错的,不争抢内存总线。
- Quad-Rank(4R),产生4个64位rank,由4个片选信号控制,这4个片选信号是交错的,不争抢内存总线。
在地址选择时,只有当片选信号有效时,此片所连的地址线才有效。
1.4 chip
内存条上的黑色芯片就是chip,提供4bit/8bit/16bit/32bit的数据,提供4bit的芯片记作x4,提供8bit的芯片记作x8。
1.5 其他
再往下的bank、Row /Column这里可以暂时不用关心了,通过上文的示意图中了解一下就行。
2 DPDK Mempool 库
内存池是一个具有固定大小的对象分配器。 在DPDK中,它由名称唯一标识,并且使用mempool handler来存储空闲对象。 默认的mempool handler是基于ring的。它提供了一些可选的服务,例如“per-core缓存”和“内存对齐”,内存对齐能确保对象被填充,以在所有DRAM或DDR3通道上均匀分布。
这个库由 Mbuf Library 使用。
2.1 Cookies保护字段
在调试模式中(CONFIG_RTE_LIBRTE_MEMPOOL_DEBUG is enabled),将在块的开头和结尾处添加cookies。 分配的对象包含保护字段,以帮助调试缓冲区溢出。
2.2 Stats统计信息
在调试模式中(CONFIG_RTE_LIBRTE_MEMPOOL_DEBUG is enabled),从池中获取、释放的统计信息存放在mempool结构体中。 为了避免并发访问统计计数器,统计信息是per-lcore的。
2.3 内存对齐约束
根据X86架构上的硬件内存配置,可以通过在对象之间添加特定的填充来极大地提高性能。目的是确保每个对象的起始位置被均匀的分布在不同的channel和rank上,以便实现所有通道的负载均衡。
当执行L3转发或流分类时,对于包缓冲区尤其如此。只访问前64个字节,因此可以通过将对象的开始地址分布在不同的通道中来提高性能。
DIMM上的rank数目是可访问DIMM完整数据位宽的独立DIMM集合的数量。 由于他们共享相同的路径,因此rank不能被同时访问。 DIMM上的DRAM芯片的物理布局不一定与rank数目相关。
当运行app时,EAL命令行选项提供了添加内存通道和rank数目的能力。
注:命令行必须始终指定处理器的内存通道数目。
不同DIMM架构的对齐示例如下两张图所示 。在例子中,我们假设包是16个64字节的块(在实际应用中这是不正确的)。
例1:Two Channels and Quad-ranked DIMM Example

例2:Three Channels and Two Dual-ranked DIMM Example
Intel® 5520芯片组有三个通道,因此,在大多数情况下,对象之间不需要填充。(除了大小为n x 3 x 64B的块)

当创建一个新池时,用户可以指定使用此功能。
我的疑问:
这里的例子是从dpdk官网拷贝过来的,我有个疑问,如果有谁知道麻烦给我留言。
例2中的pkt0根据图上看明明是starts at channel 0, rank0,为什么图上标注的是rank1?如果从图上看,这里只保证了起始于不同channel,但仍是同一个rank而且是同一个DIMM。根据原文描述,pkt只要不是n x 3 x 64B的大小就不需要填充,感觉只是保证起始在不同channel就可以了。这个问题搜索了很久没有满意的答案。
2.4 本地缓存
在CPU使用率方面,由于每个访问需要compare-and-set (CAS)操作,所以多核访问内存池的空闲缓冲区成本比较高。 为了避免对内存池ring的访问请求太多,内存池分配器可以维护per-core cache,并通过实际内存池中具有较少锁定的缓存对内存池ring执行批量请求。 通过这种方式,每个core都可以访问自己空闲对象的缓存(带锁), 只有当缓存填充时,内核才需要将某些空闲对象重新放回到缓冲池ring,或者当缓存空时,从缓冲池中获取更多对象。
虽然这意味着一些buffer可能在某些core的缓存上处于空闲状态,但是core可以无锁访问其自己的缓存提供了性能上的提升。
缓存由一个小型的per-core表及其长度组成。可以在创建池时启用/禁用此缓存。
缓存大小的最大值是静态配置,并在编译时定义的(CONFIG_RTE_MEMPOOL_CACHE_MAX_SIZE)。

不同于per-lcore内部缓存,应用程序可以通过接口 rte_mempool_cache_create() , rte_mempool_cache_free() 和 rte_mempool_cache_flush() 创建和管理外部缓存。 这些用户拥有的缓存可以被显式传递给 rte_mempool_generic_put() 和 rte_mempool_generic_get() 。 接口 rte_mempool_default_cache() 返回默认内部缓存。 与默认缓存相反,用户拥有的高速缓存可以由非EAL线程使用。
2.5 Mempool handlers
这允许外部存储子系统,如外部硬件存储管理系统和软件存储管理与DPDK一起使用。
mempool handler包括两方面:
- 添加新的mempool操作代码。这是通过添加mempool ops代码,并使用 MEMPOOL_REGISTER_OPS 宏来实现的。
- 使用新的API调用 rte_mempool_create_empty() 及 rte_mempool_set_ops_byname() 用于创建新的mempool,并制定用户要使用的操作。
在同一个应用程序中可能会使用几个不同的mempool处理。 可以使用 rte_mempool_create_empty() 创建一个新的mempool,然后用 rte_mempool_set_ops_byname() 将mempool指向相关的 mempool处理回调(ops)结构体。
传统的应用程序可能会继续使用旧的 rte_mempool_create() API调用,它默认使用基于ring的mempool处理。 这些应用程序需要修改为新的mempool处理。
对于使用 rte_pktmbuf_create() 的应用程序,有一个配置设置(RTE_MBUF_DEFAULT_MEMPOOL_OPS),允许应用程序使用另一个mempool处理。
2.6 用例
需要高性能的所有分配器应该使用内存池实现。 以下是一些使用实例:
- Mbuf Library
- Environment Abstraction Layer
- 任何需要在程序中分配固定大小对象,并将被系统持续使用的应用程序
引用参考资料:
1)dpdk官方文档:http://doc.dpdk.org/guides-20.02/prog_guide/mempool_lib.html
3)DDR扫盲——single rank与dual-rank:https://www.sohu.com/a/168446287_781333
DPDK Mempool 库原理(学习笔记)的更多相关文章
- DPDK LPM库(学习笔记)
1 LPM库 DPDK LPM库组件为32位的key实现了最长前缀匹配(LPM)表查找方法,该方法通常用于在IP转发应用程序中找到最佳路由匹配. 2 LPM API概述 LPM组件实例的主要配置参数是 ...
- [Python ]小波变化库——Pywalvets 学习笔记
[Python ]小波变化库——Pywalvets 学习笔记 2017年03月20日 14:04:35 SNII_629 阅读数:24776 标签: python库pywavelets小波变换 更多 ...
- Unity3D 骨骼动画原理学习笔记
最近研究了一下游戏中模型的骨骼动画的原理,做一个学习笔记,便于大家共同学习探讨. ps:最近改bug改的要死要活,博客写的吭哧吭哧的~ 首先列出学习参考的前人的文章,本文较多的参考了其中的表述: 1. ...
- DPDK Mbuf Library(学习笔记)
1 Mbuf库 Mbuf库提供了分配和释放缓冲区(mbufs)的功能,DPDK应用程序可以使用这些mbufs来存储消息缓冲. 消息缓冲存储在内存池中,使用Mempool库. 数据结构rte_mbuf通 ...
- DPDK IP分片及重组库(学习笔记)
1 前置知识学习 1.1 MTU MTU是最大传输单元( Maximum Transmission Unit)的缩写,指一个接口无需分片所能发送的数据包的最大字节数. MTU范围在46 ~ 1500 ...
- Java并发之底层实现原理学习笔记
本篇博文将介绍java并发底层的实现原理,我们知道java实现的并发操作最后肯定是由我们的CPU完成的,中间经历了将java源码编译成.class文件,然后进行加载,然后虚拟机执行引擎进行执行,解释为 ...
- elasticsearch原理学习笔记
https://mp.weixin.qq.com/s/dn1n2FGwG9BNQuJUMVmo7w 感谢,透彻的讲解 整理笔记 请说出 唐诗中 包含 前 的诗句 ...... 其实你都会,只是想不起 ...
- 《C标准库》学习笔记整理
简介 <C标准库>书中对 C 标准库中的 15 个头文件的内容进行了详细的介绍,包括各头文件设计的背景知识.头文件中的内容.头文件中定义的函数和变量的使用.实现.测试等. 我学习此书的目的 ...
- TCP/IP协议原理学习笔记
昨天学习了杨宁老师的TCP/IP协议原理第一讲和第二讲,主要介绍了OSI模型,整理如下: OSI是open system innerconnection的简称,即开放式系统互联参考模型,它把网络协议从 ...
随机推荐
- linux下的.ssh文件夹路径等
1.linux下的.ssh文件夹在~下,直接cd ~/.ssh即可 2.tp经过gd类处理过的水印图片格式为png 3.前端扒下别人家的网站如果自己本地打开有出现相同的代码段则有可能是js动态添加的, ...
- 我们常听到的WAL到底是什么
什么是 WAL WAL(Write Ahead Log)预写日志,是数据库系统中常见的一种手段,用于保证数据操作的原子性和持久性. 在计算机科学中,预写式日志(Write-ahead logging, ...
- NGINX反向代理,后端服务器获取真实IP
一般使用中间件做一个反向代理后,后端的web服务器是无法获取到真实的IP地址. 但是生产上,这又是不允许的,那么怎么解决? 1.在NGINX反向代理服务器上进行修改 2.修改后端web服务器配置文件 ...
- HTML中使用CSS样式(上)
在每一个标签上都可以设置style属性,这就是CSS样式: <div style="height:48px;border: 1px solid red;text-align:cente ...
- memcached 原子性操作 CAS模式
2019独角兽企业重金招聘Python工程师标准>>> 应用场景分析: 如原来MEMCACHED中的KES的内容为A,客户端C1和客户端C2都把A取了出来,C1往准备往其中加B,C2 ...
- salesforce零基础学习(九十六)Platform Event浅谈
本篇参考:https://developer.salesforce.com/blogs/2018/07/which-streaming-event-do-i-use.html https://trai ...
- unittest(@classmethod 装饰器)
1.前言: 前面讲到unittest里面setUp可以在每次执行用例前执行,这样有效的减少了代码量,但是有个弊端,比如打开浏览器操作,每次执行用例时候都会重新打开,这样就会浪费很多时间. 于是就想是不 ...
- Jenkins 构建 Jmeter 项目
1.启动 Jenkins(windows 版本) 2.新建自由风格的项目 定时任务 构建操作 安装 HTML Publisher 插件 构建后操作 最后保存构建,查看报告
- 绕WAF文章收集
在看了bypassword的<在HTTP协议层面绕过WAF>之后,想起了之前做过的一些研究,所以写个简单的短文来补充一下文章里“分块传输”部分没提到的两个技巧. 技巧1 使用注释扰乱分块数 ...
- 学习Vue第四节,v-model和双向数据绑定
Vue指令之v-model和双向数据绑定 <!DOCTYPE html> <html> <head> <meta charset="utf-8&qu ...