MySQL笔记(8)-- 索引类型
一、背景
前面我们讲了SQL分析和索引优化都涉及到了索引,那么什么是索引,它的模型有什么,实现的机制是什么,今天我们来好好讨论下。
二、索引的介绍
索引就相当书的目录,比如一本500页的书,如果你想快速找到其中的某一个知识点,在不借助目录的情况下,你得一点点慢慢的找,要找好一会儿。同样,对于数据库的表,而言,索引就是它的“目录”,提高了数据查询的效率。
比如要运行下面的查询:
select first_name from actor where actor_id=5;
如果在actor_id列上建有索引,则MySQL将使用该索引找到actor_id为5的行,也就是说,MySQL先在索引上按值查找,然后返回所有包含该值的数据行。
三、索引的常见模型和实现机制
1.哈希索引
哈希索引是一种以键-值(key-value)存储数据的结构,只有精确匹配索引所有列的查询才有效。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码,哈希码是一个较小的值,并且不同键值的行计算出来的哈希码也不一样。哈希索引将所有的哈希码存储在索引中,同时在哈希表中保存指向每个数据行的指针。即我们只要输入待查找的值即key,就可以找到其对应的值即value。
哈希的思路很简单,把值放在数组里,用一个哈希函数把key换算成一个确定的位置,然后把value放在数组的这个位置。
当然不可避免地,多个key值经过哈希函数的换算,会出现同一个值的情况。处理这种情况的一种方法是,拉出一个链,即索引会以链表的方式存放多个记录指针到同一个哈希条目中。
在MySQL中,只有Memory引擎显式支持哈希索引,也是 Memory引擎表的默认索引类型。
下面来看一个例子:
create table testhash(
fname varchar(50) not null,
lname varchar(50) not null,
key using HASH(fname)
)ENGINE=MEMORY;
表中包含如下数据:
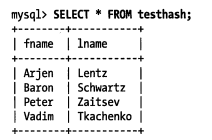
假设索引使用假想的哈希函数f(),它返回下面的值:

则哈希索引的数据结构如下:

注意每个槽的编号是顺序的,但是数据行不是。假如我们进行下面的查询:
select lname from testhash where fname='Peter';
MySQL先计算'Peter'的哈希值,并使用该值寻找对于的记录指针。因为f('Peter')=8784,所以MySQL在索引中查找8784,可以找到指向第三行的指针,最后一步是比较第三行的值是否为'Peter',以确保就是要查找的行。
因为索引自身只需存储对应的哈希值,所以索引的结构十分紧凑,所以哈希索引的查找很快。但它还是有下面的缺点:
- 哈希索引只包含哈希值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行。不过,访问内存中的行速度很快,大部分情况这一点对性能的影响并不明显;
- 哈希索引数据并不是按照索引值顺序存储的,所以无法用于排序;
- 哈希索引不支持部分索引列匹配查找,因为哈希索引是使用索引列的全部内容来计算哈希值的,例如在数据列(A,B)上建立哈希索引,如果查询只有数据列A,则无法使用该索引;
- 哈希索引只支持等值比较查询,包括=、in()、<=>,不支持任何范围查询,比如where price>100,因为如果你进行范围查找,就必须进行全表扫描;
- 当出现哈希冲突时,存储引擎必须遍历链表中所有的行指针,逐行进行比较,直到找到所有符合条件的行。
- 如果哈希冲突很多的话,一些索引维护操作的代价很高。比如当哈希冲突很多时,当从表中删除一行时,存储引擎需要遍历对应哈希值的链表中的每一行,找到并删除对应行的引用,冲突越多,代价越大。
InnoDB引擎有一个特殊的功能叫“自适应哈希索引”,当InnoDB注意到某些索引列被使用得非常频繁时,它会在内存中基于B-Tree索引之上再建立一个哈希索引,这样就让B-Tree索引也具有哈希索引的一些优点,比如快速的哈希查找。这是一个完全自动的、内部的行为,用户无法控制或配置,不过如果有必要,完全可以关闭该功能。
2.有序数组索引
有序数组索引在等值查询和范围查询场景中的性能都非常优秀。比如我们维护一个身份证信息和姓名的表,根据身份证号查找名字,我们使用有序数组来实现的话,示意图如下:
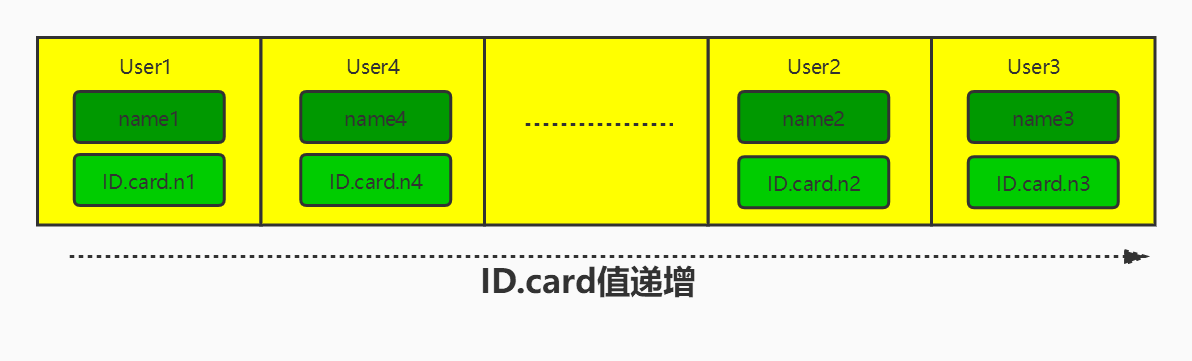
这里我们假设身份证号没有重复,这个数组就是按照身份证号递增的顺序保存的。这个时候如果你要查ID_card_n2对应的名字,用二分法就可以快速得到,这个时间复杂度是O(log(N))。
同时很显然,这个索引结构支持范围查询。如果你要查身份证号在[ID_card_X,ID_card_Y]区间的User,可以先用二分法找到ID_card_X(如果不存在ID_card_X,就找到大于ID_card_X的第一个User),然后向右遍历,直到找到第一个大于ID_card_Y的身份证号,退出循环。
如果仅仅看查询效率,有序数组就是最好的数据结构了,但是,对于更新数据时就很麻烦了,你往中间插入一个记录就必须挪动后面的所有记录,成本太高了。所以有序数组索引只适用于静态存储引擎。
3.二叉搜索树
根据上面身份证号查名字的例子,使用二叉搜索树来实现的示意图:

二叉搜索树的特点是:每个节点的左儿子小于父节点,父节点又小于右节点。这样如果你要查ID_card_n2的话,按照图中的搜索顺序就是按照UserA->UserC->UserF->User2这个路径得到。这个时间复杂度是O(log(N))。当然为了维持O(log(N))的查询复杂度,你就需要保持这棵树是平衡二叉树。为了做这个保证,更新的时间复杂度也是O(log(N))。
树可以有二叉,也可以有多叉。多叉树就是每个节点有多个儿子,儿子之间的大小保证从左到右递增。二叉树是搜索效率最高的,但是实际上大多数的数据库存储却并不使用二叉树。其原因是,索引不止存在内存中,还要写到磁盘上。
你可以想象一下一棵 100 万节点的平衡二叉树,树高 20。一次查询可能需要访问 20 个数据块。在机械硬盘时代,从磁盘随机读一个数据块需要 10 ms 左右的寻址时间。也就是说,对于一个 100 万行的表,如果使用二叉树来存储,单独访问一个行可能需要 20 个 10 ms 的时间,这个查询可真够慢的。
为了让一个查询尽量少地读磁盘,就必须让查询过程访问尽量少的数据块。那么,我们就不应该使用二叉树,而是要使用“N 叉”树。这里,“N 叉”树中的“N”取决于数据块的大小。
以 InnoDB 的一个整数字段索引为例,这个 N 差不多是 1200。这棵树高是 4 的时候,就可以存 1200 的 3 次方个值,这已经 17 亿了。考虑到树根的数据块总是在内存中的,一个 10 亿行的表上一个整数字段的索引,查找一个值最多只需要访问 3 次磁盘。其实,树的第二层也有很大概率在内存中,那么访问磁盘的平均次数就更少了。
N 叉树由于在读写上的性能优点,以及适配磁盘的访问模式,已经被广泛应用在数据库引擎中了。
在InnoDB中使用的是B+ 树索引,数据都是存储在 B+ 树中的。表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。
每一个索引在 InnoDB 里面对应一棵 B+ 树。
假设,我们有一个主键列为 ID 的表,表中有字段 k,并且在 k 上有索引。下面是表创建语句:
create table T(
id int primary key,
k int not null,
name varchar(16),
index (k)
)engine=InnoDB;
表中 R1~R5 的 (ID,k) 值分别为 (100,1)、(200,2)、(300,3)、(500,5) 和 (600,6),两棵树的示例示意图如下:
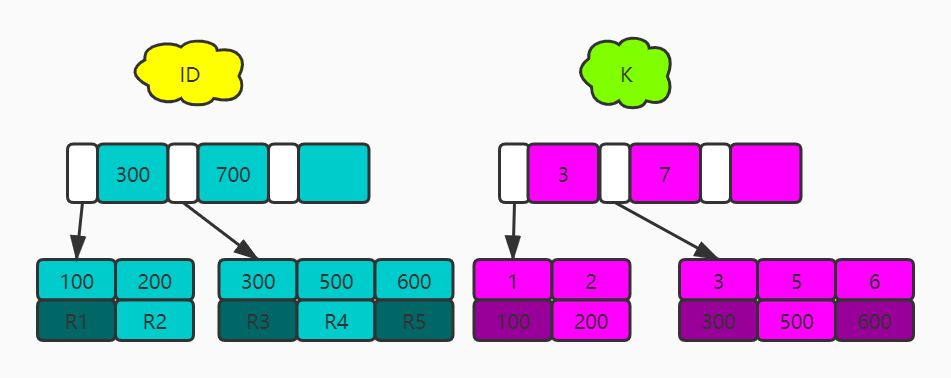
从图中不难看出,根据叶子节点的内容,索引类型分为主键索引和非主键索引。
主键索引的叶子节点存的是整行数据,在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
根据上面的索引结构说明,我们来讨论一个问题:基于主键索引和普通索引的查询有什么区别?
- 如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
- 如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
那么额外讨论下一个问题:在下面这个表 T 中,如果我执行 select * from T where k between 3 and 5,需要执行几次树的搜索操作,会扫描多少行?
现在,我们一起来看看这条SQL查询语句的执行流程:
- 在k索引树上找到k=3的记录,取得ID=300;
- 再到ID索引树查到ID=300对应的R3;
- 在k索引树取下一个值k=5,取得ID=500;
- 到ID索引树查到ID=500对应的R4;
- 在k索引树取下一个值k=6,不满足条件,循环结束。
在这个过程中,回到主键索引树搜索的过程为回表。可以看到,这个查询过程读了k索引树的3条记录(步骤1、3和5),回表了两次(步骤2和4)。
在这个例子中,由于查询结果所需要的数据只在主键索引上有,所以不得不回表。【可以通过索引优化策略来避免回表,比如覆盖索引、聚簇索引等】
B+ 树为了维护索引有序性,在插入新值的时候需要做必要的维护。以上面这个图为例,如果插入新的行 ID 值为 700,则只需要在 R5 的记录后面插入一个新记录。如果新插入的 ID 值为 400,就相对麻烦了,需要逻辑上挪动后面的数据,空出位置。
而更糟的情况是,如果 R5 所在的数据页已经满了,根据 B+ 树的算法,这时候需要申请一个新的数据页,然后挪动部分数据过去。这个过程称为页分裂。
在这种情况下,性能自然会受影响。除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低大约 50%。
当然有分裂就有合并。当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并。合并的过程,可以认为是分裂过程的逆过程。
基于上面的索引维护过程说明,我们来讨论一个案例:
你可能在一些建表规范里面见到过类似的描述,要求建表语句里一定要有自增主键。当然事无绝对,我们来分析一下哪些场景下应该使用自增主键,而哪些场景下不应该。
自增主键是指自增列上定义的主键,在建表语句中一般是这么定义的: NOT NULL PRIMARY KEY AUTO_INCREMENT。
插入新记录的时候可以不指定 ID 的值,系统会获取当前 ID 最大值加 1 作为下一条记录的 ID 值。
也就是说,自增主键的插入数据模式,正符合了我们前面提到的递增插入的场景。每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂。
而有业务逻辑的字段做主键,则往往不容易保证有序插入,这样写数据成本相对较高。
除了考虑性能外,我们还可以从存储空间的角度来看。假设你的表中确实有一个唯一字段,比如字符串类型的身份证号,那应该用身份证号做主键,还是用自增字段做主键呢?
由于每个非主键索引的叶子节点上都是主键的值。如果用身份证号做主键,那么每个二级索引的叶子节点占用约 20 个字节,而如果用整型做主键,则只要 4 个字节,如果是长整型(bigint)则是 8 个字节。
显然,主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
所以,从性能和存储空间方面考量,自增主键往往是更合理的选择。
有没有什么场景适合用业务字段直接做主键的呢?还是有的。比如,有些业务的场景需求是这样的:
- 只有一个索引;
- 该索引必须是唯一索引。
你一定看出来了,这就是典型的 KV 场景。
由于没有其他索引,所以也就不用考虑其他索引的叶子节点大小的问题。
这时候我们就要优先考虑上一段提到的“尽量使用主键查询”原则,直接将这个索引设置为主键,可以避免每次查询需要搜索两棵树。
4.空间数据索引
MyISAM表支持空间索引,可以用作地理数据存储,该索引无须前缀查询。空间索引会从所有维度来索引数据。查询时,可以有效地使用任意维度来组合查询。必须使用MySQL的GIS相关函数如MBRCONTAINS()等来维护数据。
5.全文索引
全文索引是一种特殊类型的索引,它查找的是文本中的关键词,而不是直接比较索引中的值。全文索引适用于MATCH AGAINST操作,而不是普通的WHERE条件操作。
全文索引支持各种字符内容的搜索(包括char、varchar和text类型),也支持自然语言搜索和布尔搜索。
四、讨论
对于上面例子中的 InnoDB 表 T,如果你要重建索引 k,你的两个 SQL 语句可以这么写:
alter table T drop index k;
alter table T add index(k);
如果你要重建主键索引,也可以这么写:
alter table T drop primary key;
alter table T add primary key(id);
对于上面这两个重建索引的作法,有什么不合适的,为什么,更好的方法是什么?
答案:重建索引 k 的做法是合理的,可以达到省空间的目的。但是,重建主键的过程不合理。不论是删除主键还是创建主键,都会将整个表重建。所以连着执行这两个语句的话,第一个语句就白做了。这两个语句,你可以用这个语句代替 : alter table T engine=InnoDB。
MySQL笔记(8)-- 索引类型的更多相关文章
- Mysql几种索引类型的区别及适用情况
如大家所知道的,Mysql目前主要有以下几种索引类型:FULLTEXT,HASH,BTREE,RTREE. 那么,这几种索引有什么功能和性能上的不同呢? FULLTEXT 即为全文索引,目前只有MyI ...
- [转]Mysql几种索引类型的区别及适用情况
此为转载文章,仅做记录使用,方便日后查看,原文链接:https://www.cnblogs.com/yuan-shuai/p/3225417.html Mysql几种索引类型的区别及适用情况 如大 ...
- MySQL笔记(5)---索引与算法
1.前言 本章记录MySQL中的索引机制,了解索引可以让数据库更快.索引太多会造成性能损耗,索引太少肯定查询效率不高. 2.InnoDB存储引擎所有概述 InnoDB中常见的索引有: B+树索引 全文 ...
- mysql数据库的索引类型
MySQL索引类型: 1.普通索引 最基本的索引,它没有任何限制,用于加速查询. 创建方法: a. 建表的时候一起创建 CREATE TABLE mytable ( name VARCHAR(32 ...
- MYSQL里的索引类型介绍
首先要明白索引(index)是在存储引擎(storage engine)层面实现的,而不是在server层面.不是所有的存储引擎支持有的索引类型. 1.B-TREE 最常见的索引类型,他的思想是所有的 ...
- MySQL索引类型,优化,使用数据结构
工欲善其事必先利其器 半藏说道:“若你在路途中遇到上帝,上帝也会被割伤.” 一.mysql 索引分类(默认使用B树结构)在数据库表中,对字段建立索引可以大大提高查询速度.通过善用这些索引,可以令 My ...
- 什么是索引?Mysql目前主要的几种索引类型
一.索引 MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度. 打个比方,如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的My ...
- MySQL(五) MySQL中的索引详讲
序言 之前写到MySQL对表的增删改查(查询最为重要)后,就感觉MySQL就差不多学完了,没有想继续学下去的心态了,原因可能是由于别人的影响,觉得对于MySQL来说,知道了一些复杂的查询,就够了,但是 ...
- MySQL中的索引详讲
一.什么是索引?为什么要建立索引? 索引用于快速找出在某个列中有一特定值的行,不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,表越大,查询数据所花费的时间就越多,如果表中查询的 ...
- (转)MySQL中的索引详讲
序言 之前写到MySQL对表的增删改查(查询最为重要)后,就感觉MySQL就差不多学完了,没有想继续学下去的心态了,原因可能是由于别人的影响,觉得对于MySQL来说,知道了一些复杂的查询,就够了,但是 ...
随机推荐
- sql性能优化浅谈
sql性能优化总结: 最近随着数据越来越多,数据库性能问题暴露的越来越严重.几百万,上千万,甚至过亿的数据处理速度会非常的慢. 下面对工作中遇到的问题做下总结,希望以后能对日后的工作有所帮助. 不同的 ...
- flutter 入门(Mac)
背景 近一年时间都在用 React Native 开发公司的 APP,水平基本上可以说是登堂入室了.前一段时间兴起一阵 Flutter 热,后端的同事都有推荐,今年 Google 大会又推出 flut ...
- Leetcode 24题 两两交换链表中的节点(Swap Nodes in Pairs))Java语言求解
题目描述: 给定一个链表,两两交换其中相邻的节点,并返回交换后的链表. 你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换. 示例: 给定 1->2->3->4,你应该返回 ...
- 6——PHP顺序结构&&字符串连接符
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- 成长日记(2) Java面向对象
本篇主要是记录自己在学习路上的笔记,如果有哪里记错了请大家直接指出 面向对象的概念 *人为抽象的一种编程模型 *面向过程 代码集中 难以维护 *类:对事物 算法 逻辑 概念等的抽象 理解成 模板 图纸 ...
- git上传命令步骤
1.登陆github后,进入Github首页,点击New repository新建一个项目 2. 填写相应信息后点击create repository即可 Repository name: 仓库名称( ...
- 前端进阶系列(三):HTML5新特性
HTML5 是对 HTML 标准的第五次修订.其主要的目标是将互联网语义化,以便更好地被人类和机器阅读,并同时提供更好地支持各种媒体的嵌入.HTML5 的语法是向后兼容的.现在国内普遍说的 H5 是包 ...
- 一块小饼干(Cookie)的故事-下篇
上篇介绍了注册的基本流程,下篇简单的讲讲登录的流程以及Cookie的出现 实现登录的小功能 当你在浏览器的输入框里输入localhost:8080/sign_in的时候,会发起GET请求,去访问sig ...
- Java Opencv 实现锐化
§ Laplacian() void cv::Laplacian ( InputArray src, O ...
- sentinel 规则持久化到nacos
问题描述 Sentinel Dashboard中添加的规则是存储在内存中的,只要项目一重启规则就丢失了 此处将规则持久化到nacos中,在nacos中添加规则,然后同步到dashboard中: 后面研 ...