nodejs(三)Buffer module & Byte Order
一。目录
➤ Understanding why you need buffers in Node
➤ Creating a buffer from a string
➤ Converting a buffer to a string
➤ Manipulating the bytes in a buffer
➤ Slicing and copying a buffer
二。Understanding why you need buffers in Node
JavaScript is good at handling strings, but because it was initially designed to manipulate HTML documents, it is not very good at
handling binary data. JavaScript doesn’t have a byte type — it just has numbers — or structured types, or even byte arrays: It just
has strings.
Because Node is based on JavaScript, Node can handle text protocols like HTTP, but you can also use it to talk to databases,
manipulate images, and handle fi le uploads. As you can imagine, doing this using only strings is very difficult. In the early days,
Node handled binary data by encoding each byte inside a text character, but that proved to be wasteful, slow,unreliable, and hard
to manipulate.
To make these types of binary-handling tasks easier, Node includes a binary buffer implementation, which is exposed as a JavaScript
API under the Buffer pseudo-class. A buffer length is specified in bytes, and you can randomly set and get bytes from a buffer.
Another thing that is special about this buffer class is that the memory where the data sits is allocated outside of the JavaScript VM
memory heap. This means that these objects will not be moved around by the garbage-collection algorithm: It will sit in this permanent
memory address without changing, which saves CPU cycles that would be wasted making memory copies of the buffer contents.
三。GETTING AND SETTING BYTES IN A BUFFER
After you create or receive a buffer, you might want to inspect and change its contents. You can access the byte value on any
position of a buffer by using the [] operator like this:
var buf = new Buffer('my buffer content');
// accessing the 10th position of buf
console.log(buf[10]); // -> 99
//You can also manipulate the content of any position:
buf[20] = 125; // set the 21th byte to 125
四。注意
NOTE When you create an initialized buffer, keep in mind that it will contain random bytes, not zeros.
var buf = new Buffer(1024);
console.log(buf[100]); // -> 5 (some random number)
NOTE In certain cases, some buffer operations will not yield an error. For instance:
➤ If you set any position of the buffer to a number greater than 255, that position will be assigned the 256 modulo value.
➤ If you assign the number 256 to a buffer position, you will actually be assigning the value 0.
➤ If you assign a fractional number like 100.7 to a buffer position, the buffer position will store the integer part — 100 in this case.
➤ If you try to assign a position that is out of bounds, the assignment will fail and the buffer will remain unaltered.
五。字节序
又称端序,尾序(英语:ByteOrder, or Endianness)。现代的计算机系统一般采用字节( 8 bit Byte)作为逻辑寻址单位。当物理单位的长度大于
1个字节时,就要区分字节顺序。典型的情况是整数在内存中的存放方式和网络传输的传输顺序。目前在各种体系的计算机中通常采用的字节存储机制主要
有两种:big-edian和little-endian。
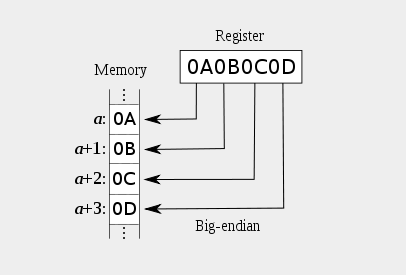
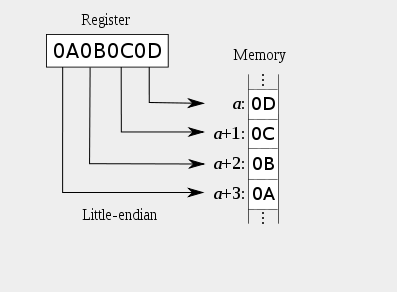
六。字节序示例
var b = new Buffer('123456789');
console.log(b.length); //9
console.log(b); //<Buffer 31 32 33 34 35 36 37 38 39>
var b2 = new Buffer(4);
b2.writeInt32LE(123456789,0);
console.log(b2.length); //4
console.log(b2); //<Buffer b5 e5 39 07>
nodejs(三)Buffer module & Byte Order的更多相关文章
- 字节顺序标记——BOM,Byte Order Mark
定义 BOM(Byte Order Mark),字节顺序标记,出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码. 介绍 UTF-8 不需要 BOM,尽管 Unico ...
- LITTLE-ENDIAN(小字节序、低字节序) BOM——Byte Order Mark 字节序标记 数据在内存中的存放顺序
总结: 1. endian 字节存放次序 字节序,顾名思义字节的顺序,再多说两句就是大于一个字节类型的数据在内存中的存放顺序(一个字节的数据当然就无需谈顺序的问题了). 2. LITTLE-ENDIA ...
- UTF-8文件的Unicode签名BOM(Byte Order Mark)问题记录(EF BB BF)
背景 楼主测试的批量发送信息功能上线之后,后台发现存在少量的ERROR日志,日志内容为手机号码格式不正确. 此前测试过程中没有出现过此类问题,从运营人员拿到的发送列表的TXT,号码是符合规则的,且格式 ...
- StreamWriter结合UTF-8编码使用不当,会造成BOM(Byte Order Mark )问题生成乱码(转载)
问: I was using HttpWebRequest to try a rest api in ASP.NET Core MVC.Here is my HttpWebRequest client ...
- nodejs里的module.exports和exports的关系
关于node里面的module.exports和exports的异同,网上已经有很多的资料,很多的文章,很多的博客,看了很多,好像懂了,又好像不懂,过几天又不懂了...大致总结是这样的: //下面这种 ...
- nodejs: 理解Buffer
学习nodejs中buffer这一章,有一段写到buffer的拼接,其中一段源码非常优美,特拿来与大家共享. var chunks = []; var size = 0; res.on('data', ...
- 字节序(byte order)和位序(bit order)
字节序(byte order)和位序(bit order) 在网络编程中经常会提到网络字节序和主机序,也就是说当一个对象由多个字节组成的时候需要注意对象的多个字节在内存中的顺序. 以前我也基本只了 ...
- 编程-Byte order & Bit order
https://mp.weixin.qq.com/s/B9rKps4YsLiDTBkRks8rmQ 看到比特序和字节序放在一起被提及,想必就已经填补了概念拼图里面缺失的那一块了,这一块正是比特序. 一 ...
- 大熊君大话NodeJS之------Buffer模块
一,开篇分析 所谓缓冲区Buffer,就是 "临时存贮区" 的意思,是暂时存放输入输出数据的一段内存. JS语言自身只有字符串数据类型,没有二进制数据类型,因此NodeJS提供了一 ...
随机推荐
- Kafka Java API操作topic
Kafka官方提供了两个脚本来管理topic,包括topic的增删改查.其中kafka-topics.sh负责topic的创建与删除:kafka-configs.sh脚本负责topic的修改和查询,但 ...
- python3.4连接和读取oracle数据表
想用python连接Oracle并查询数据表,就写了个Demo.参考了以下网址. Python学习之 cx_Oracle学习记录 一 http://my.oschina.net/bxxfighting ...
- ldap命令
ldapadd -x 进行简单认证 -D 用来绑定服务器的DN -h 目录服务的地址 -w 绑定DN的密码 -f 使用ldif文件进行条目添加的文件 -W 交互式输入DN的密码 ...
- JS 运行、复制、另存为 代码。
//运行代码 function runEx(cod1) { cod = document.getElementById(cod1) var code = cod.value; if (code != ...
- Android英文文档翻译系列(6)——LocalBroadcastManager
public class LocalBroadcastManager extends Object java.lang.Object ↳ android.support.v4.content.L ...
- OpenGL ES 系列教程
http://www.linuxgraphics.cn/graphics/opengles_tutorial_index.html 本文收集了一套 OpenGL ES 系列教程. www.play3d ...
- Nginx写IO占用高故障处理
文章来源:<https://www.centos.bz/2015/04/handle-nginx-write-io-problem/> 故障现象 突然收到一台服务器负载过高告警,紧接着网站 ...
- 【BZOJ4445】[Scoi2015]小凸想跑步 半平面交
[BZOJ4445][Scoi2015]小凸想跑步 Description 小凸晚上喜欢到操场跑步,今天他跑完两圈之后,他玩起了这样一个游戏. 操场是个凸n边形,N个顶点按照逆时针从0-n-l编号.现 ...
- [Log]ASP.NET之HttpModule 事件执行顺序
ASP.Net下的HttpModule是基于事件的处理模型,这使得我们在选择事件监听和处理的时候有更多选择.下面是对HttpModule有关事件被触发的监测: 有关代码如下 using System; ...
- spark脚本日志输出级别设置
import org.apache.log4j.{ Level, Logger } Logger.getLogger("org").setLevel(Level.WARN) Log ...