Spark学习笔记5:Spark集群架构
Spark的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展计算能力。Spark可以在各种各样的集群管理器(Hadoop YARN , Apache Mesos , 还有Spark自带的独立集群管理器)上运行,所以Spark应用既能够适应专用集群,又能用于共享的云计算环境。
- Spark运行时架构
Spark在分布式环境中的架构如下图:
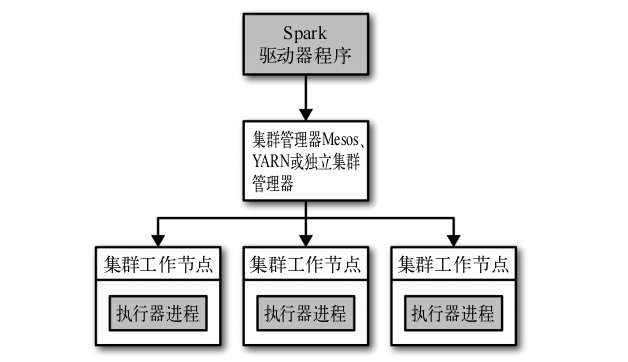
在分布式环境下,Spark集群采用的是主/从结构。在Spark集群,驱动器节点负责中央协调,调度各个分布式工作节点。执行器节点是工作节点,作为独立的Java进行运行,可以和大量的执行器节点进行通信,作为独立的Java进程运行。驱动器节点和所有的执行器节点一起被称为一个Spark应用。
Spark应用通过一个叫做集群管理器的外部服务在集群上的机器上启动。Spark自动的集群管理器称为独立集群管理器。Spark也能运行在Hadoop YARN和Apache Mesos两大开源集群管理器上。
详细说明驱动器节点和执行器节点的作用:
1、驱动器节点
Spark驱动器是执行程序中main()方法的进程。它执行用户编写的用来创建SparkContext ,创建RDD,以及进行RDD转化操作和行动操作的代码。
驱动器进程在Spark应用中有以下两个职责:
- 把用户程序转为任务
Spark驱动器程序负责把用户程序转为多个物理执行的单元,这些单元称为任务。任务是Spark中最小的工作单元,用户程序通常要启动成百上千的独立任务。
- 为执行器节点调度任务
Spark驱动器在各执行器进程间协调任务的调度,驱动器进程对应用中所有的执行器节点有完整的记录。每个执行器节点代表一个能够处理任务和存储RDD数据的进程。
2、执行器节点
Spark执行器节点是一种工作进程,负责在Spark作业中运行任务,任务间相互独立。执行器节点在Spark应用启动时启动,伴随着整个Spark应用的生命周期而存在。
执行器节点负责运行组成Spark应用的任务,并将结果返回给驱动器进程。
执行器节点通过自身的块管理器为用户程序中要求缓存的RDD提供内存式存储。
- spark-submit部署应用
使用Spark提供的统一脚本spark-submit将应用提交到集群管理器上。
spark-submit提供了各种选项可以控制应用每次运行的各项细节。这些选项分为两类:第一类是调度信息,比如你希望为作业申请的资源量。第二类是应用的运行时依赖,比如需要部署到所有工作节点的库和文件。
spark-submit的一般格式:
bin/spark-submit [options] <app jar | python file> [app options]
[options]是要传给spark-submit的标记列表,运行spark-submit --help 可以列出所有可以接收的标记。
<app jar | python file>表示包含应用入口的JAR包或Python脚本。
[app options]是传给应用的选项。
spark-submit一些常用的标记如下:

- 使用Maven依赖
<properties>
<scala.version>2.10.4</scala.version>
<spark.version>1.6.3</spark.version>
<hadoop.version>2.6.0</hadoop.version>
</properties> <dependencies>
<!-- scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>${scala.version}</version>
</dependency> <!-- spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>${spark.version}</version>
</dependency> <!-- hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>${spark.version}</version>
</dependency> <!-- hadoop -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency> <!-- JDBC -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.35</version>
</dependency>
</dependencies>
- Spark应用内与应用间调度
在调度多用户集群时,Spark主要依赖集群管理器来在Saprk应用间共享资源。Spark内部的公平调度器会让长期运行的应用定义调度任务的优先级队列。
Spark学习笔记5:Spark集群架构的更多相关文章
- Redis学习笔记八:集群模式
作者:Grey 原文地址:Redis学习笔记八:集群模式 前面提到的Redis学习笔记七:主从复制和哨兵只能解决Redis的单点压力大和单点故障问题,接下来要讲的Redis Cluster模式,主要是 ...
- ZooKeeper学习笔记一:集群搭建
作者:Grey 原文地址:ZooKeeper学习笔记一:集群搭建 说明 单机版的zk安装和运行参考:https://zookeeper.apache.org/doc/r3.6.3/zookeeperS ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- rabbitmq系统学习(三)集群架构
RabbitMQ集群架构模式 主备模式 实现RabbitMQ的高可用集群,一般在并发和数据量不高的情况下,这种模型非常的好用且简单.主备模式也称为Warren模式 HaProxy配置 listen r ...
- spark学习1(hadoop集群搭建)
把原先搭建的集群环境给删除了,自己重新搭建了一次,将笔记整理在这里,方便自己以后查看 第一步:安装主节点spark1 第一个节点:centos虚拟机安装,全名spark1,用户名hadoop,密码12 ...
- spark学习5(hbase集群搭建)
第一步:Hbase安装 hadoop,zookeeper前面都安装好了 将hbase-1.1.3-bin.tar.gz上传到/usr/HBase目录下 [root@spark1 HBase]# chm ...
- redis 学习笔记(6)-cluster集群搭建
上次写redis的学习笔记还是2014年,一转眼已经快2年过去了,在段时间里,redis最大的变化之一就是cluster功能的正式发布,以前要搞redis集群,得借助一致性hash来自己搞shardi ...
- Hadoop学习笔记—13.分布式集群中节点的动态添加与下架
开篇:在本笔记系列的第一篇中,我们介绍了如何搭建伪分布与分布模式的Hadoop集群.现在,我们来了解一下在一个Hadoop分布式集群中,如何动态(不关机且正在运行的情况下)地添加一个Hadoop节点与 ...
- Spark学习笔记-使用Spark History Server
在运行Spark应用程序的时候,driver会提供一个webUI给出应用程序的运行信息,但是该webUI随着应用程序的完成而关闭端口,也就是 说,Spark应用程序运行完后,将无法查看应用程序的历史记 ...
- 开源流媒体服务器SRS学习笔记(4) - Cluster集群方案
单台服务器做直播,总归有单点风险,利用SRS的Forward机制 + Edge Server设计,可以很容易搭建一个大规模的高可用集群,示意图如下 源站服务器集群:origin server clus ...
随机推荐
- uDig配图与GeoServer添加Style
软件介绍: uDig是一个开源的桌面GIS软件,可以进行shp与栅格数据地图文件的编辑和查看,对OpenGIS标准,关于互联网GIS.网络地图服务器和网络功能服务器有特别的加强.通常和GeoServe ...
- 第32课 初探C++标准库
有趣的重载: 实验: 将1左移到cout对象中. 将Test改名为Console,此时我们的本意是想让这个cout代表当前的命令行: cout代表命令行的一个实例,本意是想将1打印到命令行上. 我们在 ...
- WinRAR备份技巧 - imsoft.cnblogs
RAR控制台日常备份策略 run.batrar a -ep1 -agYYYY{年}MM{月}DD{日} 备份 @list.txt-ep1是忽略原文件路径,rar包里是一堆文件,没有目录结构-ag附加命 ...
- Dubbo 版 Helloworld
使用工具:MAVEN.IDEA.Spring.Dubbo.Zookeeper 直接上代码 项目结构: 步骤如下: 搭建MAVEN项目,添加相关依赖 pom.xml <!--Zookeeper-- ...
- HDU 2546:饭卡(01背包)
饭卡 Time Limit: 5000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submiss ...
- python pandas Timestamp 转为 datetime 类型
In [11]: ts = pd.Timestamp('2014-01-23 00:00:00', tz=None) In [12]: ts.to_pydatetime() Out[12]: date ...
- 转 Apache Kafka:下一代分布式消息系统
简介 Apache Kafka是分布式发布-订阅消息系统.它最初由LinkedIn公司开发,之后成为Apache项目的一部分.Kafka是一种快速.可扩展的.设计内在就是分布式的,分区的和可复制的提交 ...
- 用newLISP通过SMTPserver发送邮件
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/sheismylife/article/details/26633073 直接使用标准模块smtpx. ...
- Python函数 dict()
dict() 作用:dict() 函数用于创建一个字典.返回一个字典. 语法: class dict(**kwarg) class dict(mapping, **kwarg) class dict( ...
- VSCODE includePath 中使用系统中的变量
使用 ${env.ENVNAME} 这样只需要在 系统中加一个系统变量就可以. https://github.com/Microsoft/vscode-cpptools/issues/697