使用glusterfs 作为 kubernetes PersistentVolume PersistentVolumeClaim 持久化仓库,高可用Rabbitmq,高可用mysql,高可用redis
glusterfs 怎么集群,网上一搜铺天盖地的
可利用这个特点做单节点高可用,因为K8S 哪怕节点宕机了 master 会在随意一台节点把挂掉的复活
当然我是在自己的环境下跑,经过网络的glusterfs,数据传输,有笔记大的性能损耗,对网络要求也特别高
小文件存储性能也不高等问题.最下面有mariadb 使用glusterfs 插入10W行数据,与本地硬盘的性能对比
这里记录一下rabbitmq 单机高可用情景,mysql,mongodb, redis 等,万变不离其宗
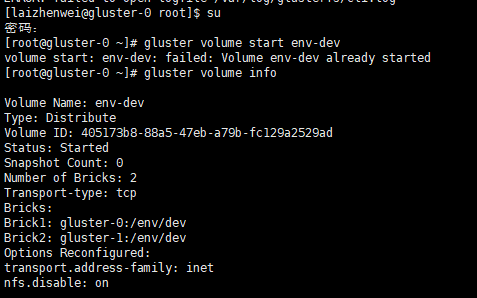
事先创建好了 volume,卷名为 env-dev
随便找个客户机挂载
mount -t glusterfs 192.168.91.135:/env-dev /mnt/env/dev
预先创建需要的文件夹
mkdir -p /mnt/env/dev/rabbitmq/mnesia
编写 glusterfs endpoint
[root@k8s-master- dev]# cat pv-ep.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: glusterfs
namespace: env-dev
subsets:
- addresses:
- ip: 192.168.91.135
- ip: 192.168.91.136
ports:
- port:
protocol: TCP ---
apiVersion: v1
kind: Service
metadata:
name: glusterfs
namespace: env-dev
spec:
ports:
- port:
protocol: TCP
targetPort:
sessionAffinity: None
type: ClusterIP
编写 pv,注意这里path 是 volume名称 + 具体路径
[root@k8s-master- dev]# cat rabbitmq-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rabbitmq-pv
labels:
type: glusterfs
spec:
storageClassName: rabbitmq-dir
capacity:
storage: 3Gi
accessModes:
- ReadWriteMany
glusterfs:
endpoints: glusterfs
path: "env-dev/rabbitmq/mnesia"
readOnly: false
编写pvc
[root@k8s-master-0 dev]# cat rabbitmq-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rabbitmq-pvc
namespace: env-dev
spec:
storageClassName: rabbitmq-dir
accessModes:
- ReadWriteMany
resources:
requests:
storage: 3Gi
创建endpoint pv pcv
kubectl apply -f pv-ep.yaml
kubectl apply -f rabbitmq-pv.yaml kubectl apply -f rabbitmq-pvc.yaml



使用方式,红字部分
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: ha-rabbitmq
namespace: env-dev
spec:
replicas: 1
selector:
matchLabels:
app: ha-rabbitmq
template:
metadata:
labels:
app: ha-rabbitmq
spec:
#hostNetwork: true
hostname: ha-rabbitmq
terminationGracePeriodSeconds: 60
containers:
- name: ha-rabbitmq
image: 192.168.91.137:5000/rabbitmq:3.7.7-management-alpine
securityContext:
privileged: true
env:
- name: "RABBITMQ_DEFAULT_USER"
value: "rabbit"
- name: "RABBITMQ_DEFAULT_PASS"
value: "rabbit"
ports:
- name: tcp
containerPort: 5672
hostPort: 5672
- name: http
containerPort: 15672
hostPort: 15672
livenessProbe:
failureThreshold: 3
httpGet:
path: /
port: 15672
scheme: HTTP
initialDelaySeconds: 20
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
readinessProbe:
failureThreshold: 3
httpGet:
path: /
port: 15672
scheme: HTTP
initialDelaySeconds: 20
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
volumeMounts:
- name: date
mountPath: /etc/localtime
- name: workdir
mountPath: "/var/lib/rabbitmq/mnesia"
volumes:
- name: date
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
- name: workdir
persistentVolumeClaim:
claimName: rabbitmq-pvc --- apiVersion: v1
kind: Service
metadata:
name: ha-rabbitmq
namespace: env-dev
labels:
app: ha-rabbitmq
spec:
ports:
- name: tcp
port: 5672
targetPort: 5672
- name: http
port: 15672
targetPort: 15672
创建rabbitmq pod以及service.
kubectl create -f ha-rabbitmq.yaml

分配到了第一个节点,看看数据文件

在管理页面创建一个创建一个 virtual host

环境东西太多,这里就不暴力关机了,直接删除再创建

这次分配到节点0
看看刚才创建的virtual host
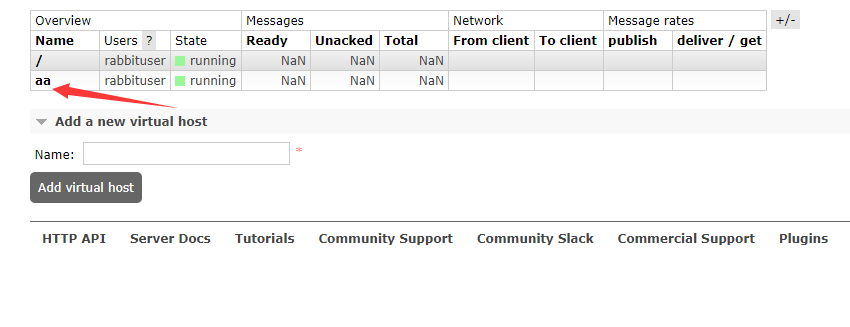
还健在
haproxy 代理
[root@localhost conf]# cat haproxy.cfg
global
chroot /usr/local
daemon
nbproc 1
group nobody
user nobody
pidfile /haproxy.pid
#ulimit-n 65536
#spread-checks 5m
#stats timeout 5m
#stats maxconn 100 ########默认配置############
defaults
mode tcp
retries 3 #两次连接失败就认为是服务器不可用,也可以通过后面设置
option redispatch #当serverId对应的服务器挂掉后,强制定向到其他健康的服务器
option abortonclose #当服务器负载很高的时候,自动结束掉当前队列处理比较久的链接
maxconn 32000 #默认的最大连接数
timeout connect 10s #连接超时
timeout client 8h #客户端超时
timeout server 8h #服务器超时
timeout check 10s #心跳检测超时
log 127.0.0.1 local0 err #[err warning info debug] ########MariaDB配置#################
listen mariadb
bind 0.0.0.0:3306
mode tcp
balance leastconn
server mariadb1 192.168.91.141:3306 check port 3306 inter 2s rise 1 fall 2 maxconn 1000
server mariadb2 192.168.91.142:3306 check port 3306 inter 2s rise 1 fall 2 maxconn 1000
server mariadb3 192.168.91.143:3306 check port 3306 inter 2s rise 1 fall 2 maxconn 1000 #######RabbitMq配置#################
listen rabbitmq
bind 0.0.0.0:5672
mode tcp
balance leastconn
server rabbitmq1 192.168.91.141:5672 check port 5672 inter 2s rise 1 fall 2 maxconn 1000
server rabbitmq2 192.168.91.142:5672 check port 5672 inter 2s rise 1 fall 2 maxconn 1000
server rabbitmq3 192.168.91.143:5672 check port 5672 inter 2s rise 1 fall 2 maxconn 1000 #######Redis配置#################
listen redis
bind 0.0.0.0:6379
mode tcp
balance leastconn
server redis1 192.168.91.141:6379 check port 6379 inter 2s rise 1 fall 2 maxconn 1000
server redis2 192.168.91.142:6379 check port 6379 inter 2s rise 1 fall 2 maxconn 1000
server redis3 192.168.91.143:6379 check port 6379 inter 2s rise 1 fall 2 maxconn 1000
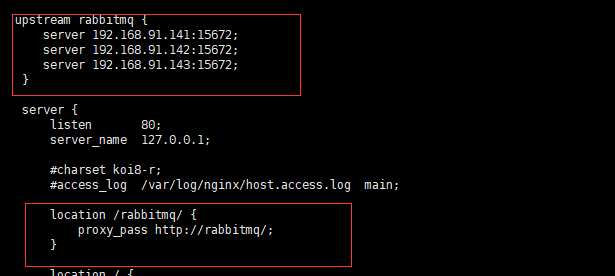
nginx 代理管理页面
Mariadb 使用 glusterfs 与 本地硬盘 性能测试
#使用glusterfs 两个副本的 mariadb 插入10W行数据 2 queries executed, 2 success, 0 errors, 0 warnings 查询:CREATE PROCEDURE test_insert() BEGIN DECLARE Y bigint DEFAULT 1; WHILE Y<100000 DO INSERT INTO t_insert VALUES(NULL,'11111111111... 共 0 行受到影响 执行耗时 : 0.018 sec
传送时间 : 1.366 sec
总耗时 : 1.385 sec
----------------------------------------------------------- 查询:CALL test_insert(); 共 99999 行受到影响 执行耗时 : 6 min 1 sec
传送时间 : 0 sec
总耗时 : 6 min 1 sec #使用本地硬盘 mariadb 插入10W行数据 2 queries executed, 2 success, 0 errors, 0 warnings 查询:CREATE PROCEDURE test_insert() BEGIN DECLARE Y BIGINT DEFAULT 1; WHILE Y<100000 DO INSERT INTO t_insert VALUES(NULL,'11111111111... 共 0 行受到影响 执行耗时 : 0.004 sec
传送时间 : 1.372 sec
总耗时 : 1.376 sec
----------------------------------------------------------- 查询:CALL test_insert(); 共 99999 行受到影响 执行耗时 : 1 min 13 sec
传送时间 : 0.006 sec
总耗时 : 1 min 13 sec
使用glusterfs 作为 kubernetes PersistentVolume PersistentVolumeClaim 持久化仓库,高可用Rabbitmq,高可用mysql,高可用redis的更多相关文章
- 使用Ceph集群作为Kubernetes的动态分配持久化存储(转)
使用Docker快速部署Ceph集群 , 然后使用这个Ceph集群作为Kubernetes的动态分配持久化存储. Kubernetes集群要使用Ceph集群需要在每个Kubernetes节点上安装ce ...
- k8s kubernetes 核心笔记 镜像仓库 项目k8s改造(含最新k8s v1.16.2版本)
k8s kubernetes 核心笔记 镜像仓库 项目k8s改造 2019/10/24 Chenxin 一 基本资料 一 参考: https://kubernetes.io/ 官网 https://k ...
- velero 备份、迁移 kubernetes 应用以及持久化数据卷
velero 是heptio 团队开源的kubernetes 应用以及持久化数据卷备份以及迁移的解决方案,以前的名字为ark 包含以下特性: 备份集群以及恢复 copy 当前集群的资源到其他集群 复制 ...
- Docker数据持久化及实战(Nginx+Spring Boot项目+MySQL)
Docker数据持久化: Volume: (1)创建mysql数据库的container docker run -d --name mysql01 -e MYSQL_ROOT_PASSWORD= my ...
- kubernetes学习 做持久化存储
本节演示如何为 MySQL 数据库提供持久化存储,步骤: 1.创建 PV 和 PVC 2.部署 MySQL 3.向 MySQL 添加数据 4.模拟节点宕机故障,Kubernetes 将 MySQL 自 ...
- [置顶]
kubernetes资源类型--持久化存储Persistent Volume和Persistent Volume Claim
概念 存储管理跟计算管理是两个不同的问题.理解每个存储系统是一件复杂的事情,特别是对于普通用户来说,有时并不需要关心各种存储实现,只希望能够安全可靠地存储数据. 为了简化对存储调度,K8S对存储的供应 ...
- Kubernetes从私有镜像仓库中拉取镜像
当我们尝试从私有仓库中拉取镜像时,可能会收到这样提示:requested access to the resource is denied Error response from daemon: pu ...
- Kubernetes 配置私有镜像仓库时,没有权限访问的问题
使用 K8S 部署服务时,如果指定的镜像地址是内部镜像仓库,那么在下载镜像的时候可能会报权限错误.这是由于在 K8S 中部署服务时,K8S 需要到 Harbor 中进行一次验证,这个验证与节点中使用 ...
- aws eks ebs StorageClass PersistentVolume PersistentVolumeClaim
aws EBS 提供存储资源 Amazon EBS CSI 驱动程序的安装,请参考https://docs.aws.amazon.com/zh_cn/eks/latest/userguide/ebs- ...
随机推荐
- Maven实战(八)——常用Maven插件介绍(下)
我们都知道Maven本质上是一个插件框架,它的核心并不执行任何具体的构建任务,所有这些任务都交给插件来完成,例如编译源代码是由maven- compiler-plugin完成的.进一步说,每个任务对应 ...
- 【二分】Base Station Sites @ICPC2017HongKong/upcexam5559
时间限制: 1 Sec 内存限制: 128 MB 5G is the proposed next telecommunications standards beyond the current 4G ...
- Android定制:修改开机启动画面
转自:https://blog.csdn.net/godiors_163/article/details/72529210 引言 Android系统在按下开机键之后就会进入启动流程,这个过程本身需要一 ...
- NLP 第10章 基于深度学习的NLP 算法
- java servlet 生命周期
Life Cycle in Detail:-1-When a server loads a servlet, it runs the servlet's init method. Even thoug ...
- iOS获取当前城市
1.倒入头文件 #import <CoreLocation/CoreLocation.h> 2.实现定位协议CLLocationManagerDelegate 3.定义定位属性 @prop ...
- window.print控制打印样式
我们可能会去使用window.print()方法来打印页面,但是当我们遇到需要改变打印时候的字体大小等css样式的时候你可能会懵逼. 所以搜索成了我们的必经之路,我相信在网上搜索出来的最好的答案就是使 ...
- app优化之流量节省
前言:“客户端上传时间戳”的玩法,你玩过么?一起聊聊时间戳的奇技淫巧!,其实这个类似于数据版本号的东西. 缘起:无线时代,流量敏感.APP在登录后,往往要向服务器同步非常多的数据,很费流量,技术上有没 ...
- nrm 安装与npm镜像切换
家里宽带用的移动的...访问海外镜像是相当慢,npm和maven一个道理,maven可以切换到淘宝镜像或者其他的,那么npm也可以使用国内镜像,这个时候就需要用到nrm来做镜像管理了 首先这是目前本地 ...
- [HDFS Manual] CH8 HDFS Snapshots
HDFS Snapshots HDFS Snapshots 1. 概述 1.1 Snapshottable目录 1.2 快照路径 2. 带快照的更新 3. 快照操作 3.1 管理操作 3.2 用户操作 ...