【ZooKeeper】ZooKeeper安装及简单操作
ZooKeeper介绍
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper包含一个简单的原语集, [1] 提供Java和C的接口。
官网:https://zookeeper.apache.org
ZooKeeper安装
安装环境:
1、系统:CentOS 7.4
2、Java环境:JDK8
zookeeper有单机、伪集群、集群三种部署方式,本例使用的zookeeper版本是:zookeeper-3.4.12
单机模式
1、下载ZooKeeper,地址:http://mirrors.hust.edu.cn/apache/zookeeper/
注意版本,启动报错可能找不到主类,可以下载源码版
2、解压,命令:tar -zxvf zookeeper-3.4.12.tar.gz -C /data/soft/
解压后目录如下:

3、进入conf目录,创建一个zookeeper的配置文件zoo.cfg,可复制conf/zoo_sample.cfg作为配置文件
命令:cd conf
命令:cp zoo_sample.cfg zoo.cfg

配置文件说明:
# The number of milliseconds of each tick
# tickTime:CS通信心跳数
# Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。
tickTime=2000 # The number of ticks that the initial
# synchronization phase can take
# initLimit:LF初始通信时限
# 集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
initLimit=5 # The number of ticks that can pass between
# sending a request and getting an acknowledgement
# syncLimit:LF同步通信时限
# 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
syncLimit=2 # the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# dataDir:数据文件目录
# Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。
dataDir=/data/soft/zookeeper-3.4.12/data # dataLogDir:日志文件目录
# Zookeeper保存日志文件的目录。
dataLogDir=/data/soft/zookeeper-3.4.12/logs # the port at which the clients will connect
# clientPort:客户端连接端口
# 客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
clientPort=2181 # the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1 # 服务器名称与地址:集群信息(服务器编号,服务器地址,LF通信端口,选举端口)
# 这个配置项的书写格式比较特殊,规则如下: # server.N=YYY:A:B # 其中N表示服务器编号,YYY表示服务器的IP地址,A为LF通信端口,表示该服务器与集群中的leader交换的信息的端口。B为选举端口,表示选举新leader时服务器间相互通信的端口(当leader挂掉时,其余服务器会相互通信,选择出新的leader)。一般来说,集群中每个服务器的A端口都是一样,每个服务器的B端口也是一样。但是当所采用的为伪集群时,IP地址都一样,只能时A端口和B端口不一样。
4、可以不修改zoo.cfg,默认配置就行,进去zookeeper安装目录,启动ZooKeeper
启动命令:./bin/zkServer.sh start
停止命令:./bin/zkServer.sh stop
重启命令:./bin/zkServer.sh restart
状态查看命令:./bin/zkServer.sh status
伪集群模式
伪集群模式就是在同一主机启动多个zookeeper并组成集群
1、在同一台主机上,通过复制得到三个zookeeper实例

2、对三个zookeeper节点进行配置
zookeeper1配置文件conf/zoo.cfg修改如下:
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/data/soft/zookeeper-cluster/zookeeper-3.4.12-12181/data
dataLogDir=/data/soft/zookeeper-cluster/zookeeper-3.4.12-12181/logs
clientPort=12181 server.1=127.0.0.1:12888:13888
server.2=127.0.0.1:14888:15888
server.3=127.0.0.1:16888:17888
注:server.1中的数字1为服务器的ID,需要与myid文件中的id一致,下一步将配置myid
zookeeper1的data/myid配置,使用如下命令(即新建一个文件data/myid,在其中添加内容为:1):
echo '1' > data/myid
zookeeper2配置文件conf/zoo.cfg修改如下:
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/data/soft/zookeeper-cluster/zookeeper-3.4.12-12182/data
dataLogDir=/data/soft/zookeeper-cluster/zookeeper-3.4.12-12182/logs
clientPort=12182 server.1=127.0.0.1:12888:13888
server.2=127.0.0.1:14888:15888
server.3=127.0.0.1:16888:17888
zookeeper2的data/myid配置,使用如下命令:
echo '2' > data/myid
zookeeper3配置文件conf/zoo.cfg修改如下:
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/data/soft/zookeeper-cluster/zookeeper-3.4.12-12183/data
dataLogDir=/data/soft/zookeeper-cluster/zookeeper-3.4.12-12183/logs
clientPort=12183 server.1=127.0.0.1:12888:13888
server.2=127.0.0.1:14888:15888
server.3=127.0.0.1:16888:17888
zookeeper3的data/myid配置,使用如下命令:
echo '3' > data/myid
3、分别启动三个zookeeper节点
4、查看节点状态
命令:./zookeeper-3.4.12-12181/bin/zkServer.sh status
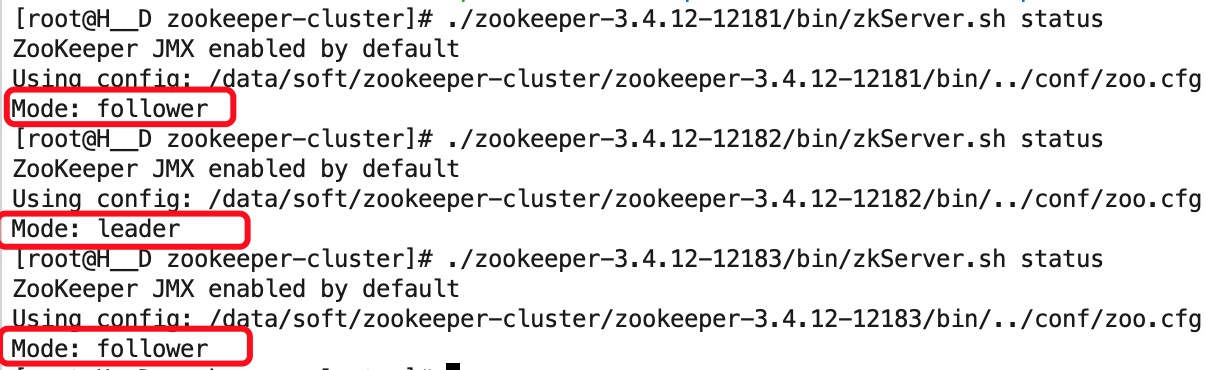
集群模式
集群模式就是在不同主机上安装zookeeper然后组成集群的模式,可以参考伪集群模式安装
1、在三台机器上分别部署1个ZooKeeper实例
2、zookeeper配置文件conf/zoo.cfg,如下:
tickTime=2000
initLimit=5
syncLimit=2
dataDir=/data/soft/zookeeper-3.4.12/data
dataLogDir=/data/soft/zookeeper-3.4.12/logs
clientPort=2181 server.1=127.0.0.1:2888:3888
server.2=127.0.0.2:2888:3888
server.3=127.0.0.3:2888:3888
3、zookeeper的data/myid配置,使用如下命令:
echo '1' > data/myid
当然zookeeper1 对应的是 1,zookeeper2 对应的是 2,zookeeper3 对应的是 3
4、分别启动三个zookeeper节点,即完成对ZooKeeper集群的安装
ZooKeeper简单操作
下面操作在zookeeper单机模式下完成的
a、使用客户端连接ZooKeeper服务
命令:./bin/zkCli.sh -server 127.0.0.1:2181
./bin/zkCli.sh默认连接到本地127.0.0.1:2181
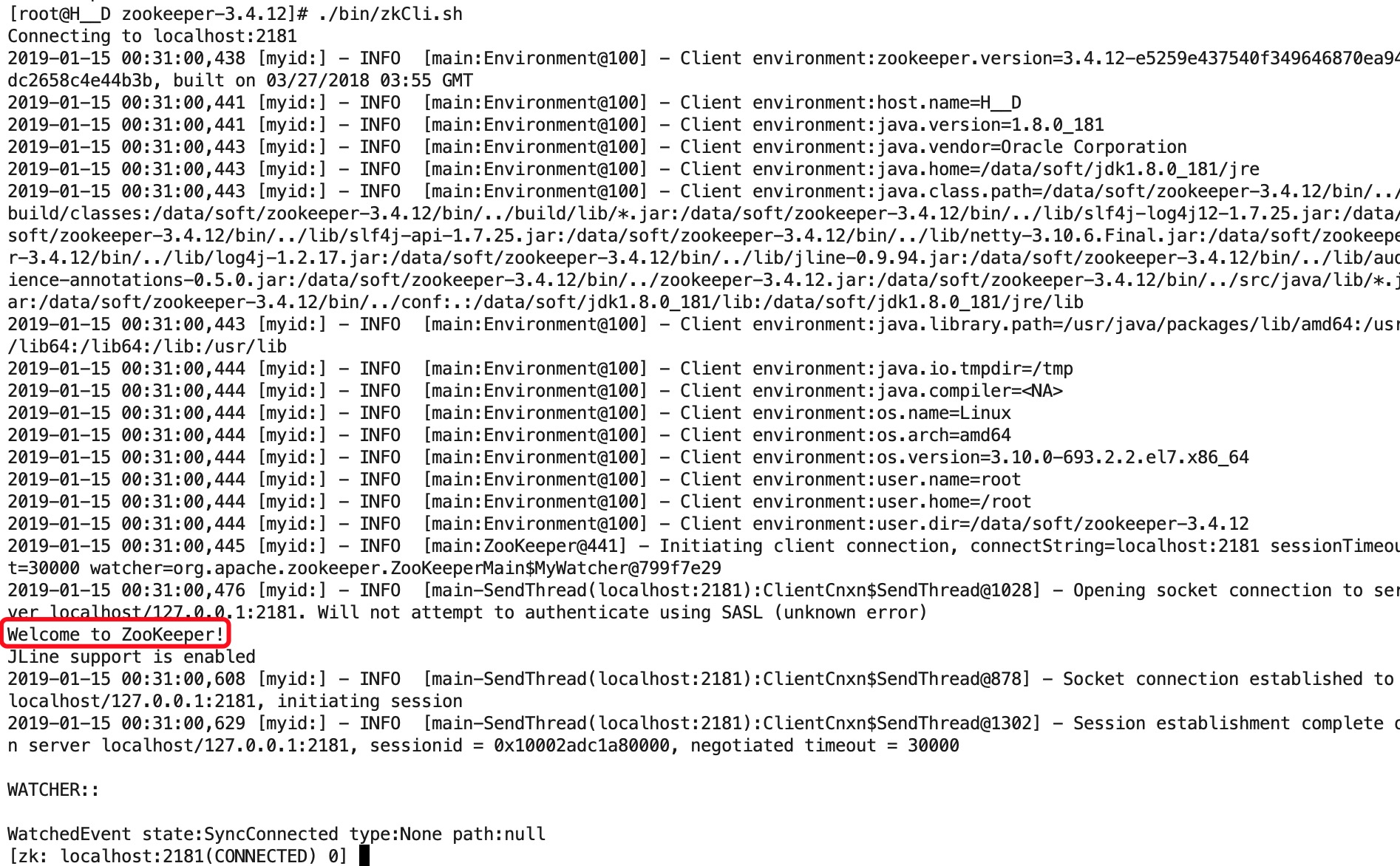
b、使用 ls 命令来查看当前 ZooKeeper 中所包含的内容:
命令:ls /

c、创建了一个新的 znode 节点“ zk ”以及与它关联的字符串
命令:create /zk myData

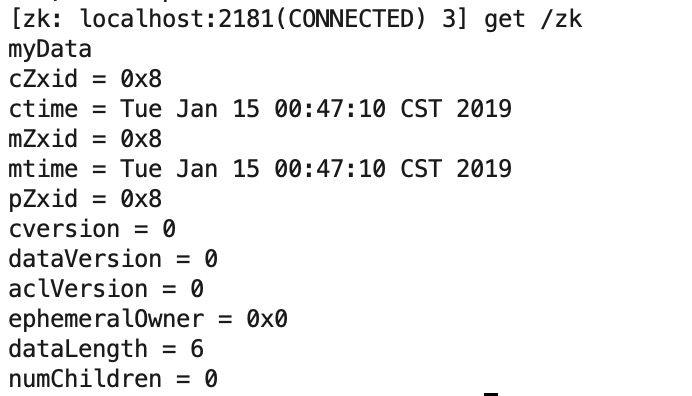
d、获取znode节点“ zk ”
命令:get /zk
e、删除znode节点“ zk ”
命令:delete /zk

f、推出客户端
命令:quit
【ZooKeeper】ZooKeeper安装及简单操作的更多相关文章
- storm安装以及简单操作
storm的安装比较简单,下面以storm的单节点为例说明storm的安装步骤. 1.storm的下载 进入storm的官方网站http://storm.apache.org/,点击download按 ...
- MySQL安装和简单操作
MySQL数据库安装与配置详解 MySQL的安装请参考下面这篇博客,讲述的非常详细,各种截图也很清晰.http://www.cnblogs.com/sshoub/p/4321640.html MySQ ...
- RabbitMQ安装以及简单操作应用(针对Windows和C#)
1.RabbitMQ安装 1.1下载并安装Erlang https://www.erlang.org/downloads 一直点next就安装好了.我直接使用了默认的安装目录.否则的话,应该需要配置一 ...
- Hadoop3集群搭建之——hbase安装及简单操作
折腾了这么久,hbase终于装好了 ------------------------- 上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hado ...
- python学习笔记(mysqldb下载安装及简单操作)
python支持对mysql的操作 已经安装配置成功python.mysql 之后根据各自电脑配置选择对应系统的MySQL-python 文件是EXE格式.打开下一步即可 下载地址博主分享下: htt ...
- mysql安装及简单操作
sudo grep mysql_root_passwd /root/env.txt (现在很多人开始使用云主机,登录云主机之后可以根据该命令查看阿里云数据库密码) mysql 安装:rpm+retha ...
- postgresql数据库安装及简单操作
自从MySQL被Oracle收购以后,PostgreSQL逐渐成为开源关系型数据库的首选. 本文介绍PostgreSQL的安装和基本用法,供初次使用者上手.以下内容基于Debian操作系统,其他操作系 ...
- mongodb的安装与简单操作
MongoDB中文社区:http://www.mongoing.com 数据库的使用场景 SQL(关系型数据库):MySQL.SQLServer --->磁盘操作 1.高度事务性的场景 ...
- mysql 首次安装后 简单操作与语句 新手入门
首先cd到安装目录中bin路径:这是我的安装路径以管理员身份打开cmd(防止权限不足)cd E:\>cd E:\mysql\mysql-5.5.40-winx64\bin 首次安装需要输入 my ...
随机推荐
- ftok()函数深度解析
[转载] 原文链接:https://blog.csdn.net/u013485792/article/details/50764224 关于ftok函数,先不去了解它的作用来先说说为什么要用它,共享内 ...
- JDBC 中preparedStatement和Statement区别
一.概念 PreparedStatement是用来执行SQL查询语句的API之一,Java提供了 Statement.PreparedStatement 和 CallableStatement三种方式 ...
- docker 批量删除
杀死所有正在运行的容器docker kill $(docker ps -a -q) 删除所有已经停止的容器docker rm $(docker ps -a -q) 删除所有未打 dangling 标签 ...
- HDFS知识点总结
学习完Hadoop权威指南有一段时间了,现在再回顾和总结一下HDFS的知识点. 1.HDFS的设计 HDFS是什么:HDFS即Hadoop分布式文件系统(Hadoop Distributed File ...
- mybatis的简单使用调用mapper接口
mybatis 是apache下的一个面向sql编程的半自动化的ORM持久层的框架.特点:面向sql编程,达到高性能的使用目的. 下面是简单使用 现导入jar包,只有mybatis和数据库驱动包(这里 ...
- mysql 5.7 修改字符编码
在my.ini文件中添加 [mysqld]character-set-server = utf8 [client]default-character-set = utf8
- Sublime Text 3激活
Sublime Text 3激活方式: 一.修改hosts文件: 1:windows系统: 找到 C:\Windows\System32\drivers\etc\hosts 这个文件, 用 ...
- python中class的序列化和反序列化
对于类的序列化:将类的成员变量名和数据作为一对键值对存储在物理内存中,例如 class A(object): def __init__(self): self.a = o self.b = 1 sel ...
- dubbo面试题,会这些说明你真正看懂了dubbo源码
整理了一些dubbo可能会被面试的面试题,感觉非常不错.如果你基本能回答说明你看懂了dubbo源码,对dubbo了解的足够全面.你可以尝试看能不能回答下.我们一起看下有哪些问题吧? 1.dubbo中& ...
- Java -- XStreamAlias 处理节点中的属性和值
XStreamAlias 可以把objec和xml相互转换,但是有时候节点带有属性和值就需要特殊处理下: <?xml version="1.0" encoding=" ...