Kaggle项目实战一:Titanic: Machine Learning from Disaster
项目地址
https://www.kaggle.com/c/titanic
项目介绍:
除了乘客的编号以外,还包括下表中10个字段,构成了数据的所有特征
|
Variable |
Definition |
Key |
|
survival |
是否存活 |
0 = No, 1 = Yes |
|
pclass |
票的等级 |
1 = 1st, 2 = 2nd, 3 = 3rd |
|
sex |
性别 |
|
|
Age |
年龄 |
|
|
sibsp |
同乘配偶或兄弟姐妹 |
|
|
parch |
同乘孩子或父母 |
|
|
ticket |
票号 |
|
|
fare |
乘客票价 |
|
|
cabin |
客舱号码 |
|
|
embarked |
登船港口 |
C = Cherbourg, Q = Queenstown, S = Southampton |
一、导入数据
train_df = pd.read_csv("..\train.csv")
test_df = pd.read_csv("..\test.csv")
查看数据整体缺失情况
结果如下:存在null值得字段有Age、Fare和Cabin,其中Cabin缺失最为严重,缺失率77.1%
train_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
连续型变量分布情况
train_df.describe()
PassengerId Survived Pclass Age SibSp \
count 891.000000 891.000000 891.000000 714.000000 891.000000
mean 446.000000 0.383838 2.308642 29.699118 0.523008
std 257.353842 0.486592 0.836071 14.526497 1.102743
min 1.000000 0.000000 1.000000 0.420000 0.000000
25% 223.500000 0.000000 2.000000 20.125000 0.000000
50% 446.000000 0.000000 3.000000 28.000000 0.000000
75% 668.500000 1.000000 3.000000 38.000000 1.000000
max 891.000000 1.000000 3.000000 80.000000 8.000000
Parch Fare
count 891.000000 891.000000
mean 0.381594 32.204208
std 0.806057 49.693429
min 0.000000 0.000000
25% 0.000000 7.910400
50% 0.000000 14.454200
75% 0.000000 31.000000
max 6.000000 512.329200
离散变量情况( 包括客舱号码,登船港口,票的等级,性别)
train_df.describe(include=['O'])
Name Sex Ticket Cabin Embarked
count 891 891 891 204 889
unique 891 2 681 147 3
top Greenberg, Mr. Samuel male 347082 B96 B98 S
freq 1 577 7 4 644
- Total samples are 891 or 40% of the actual number of passengers on board the Titanic (2,224).
- Survived is a categorical feature with 0 or 1 values.
- Around 38% samples survived representative of the actual survival rate at 32%.
- Most passengers (> 75%) did not travel with parents or children.
- Nearly 30% of the passengers had siblings and/or spouse aboard.
- Fares varied significantly with few passengers (<1%) paying as high as $512.
- Few elderly passengers (<1%) within age range 65-80.
讨论特征增加和删除:
delete:用户id,用户名称可能需要删掉
create:Age range feature,fare range feature
discuss:年龄小的,性别为女的获救的几率应该比较大
train_df[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False)
Pclass Survived
0 1 0.629630
1 2 0.472826
2 3 0.242363
train_df[['Sex', 'Survived']].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived', ascending=False)
Sex Survived
0 female 0.742038
1 male 0.188908
二、可视化
Survival by Age, Class and Gender
g = sns.FacetGrid(train_df, col='Survived')
g.map(plt.hist, 'Age', bins=20)
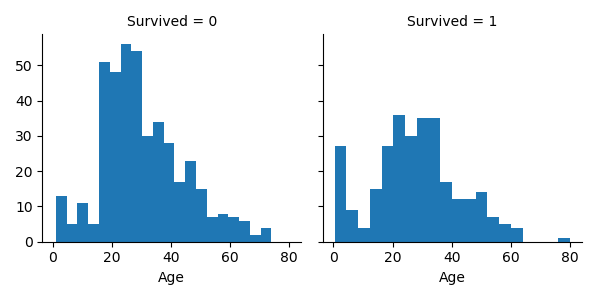
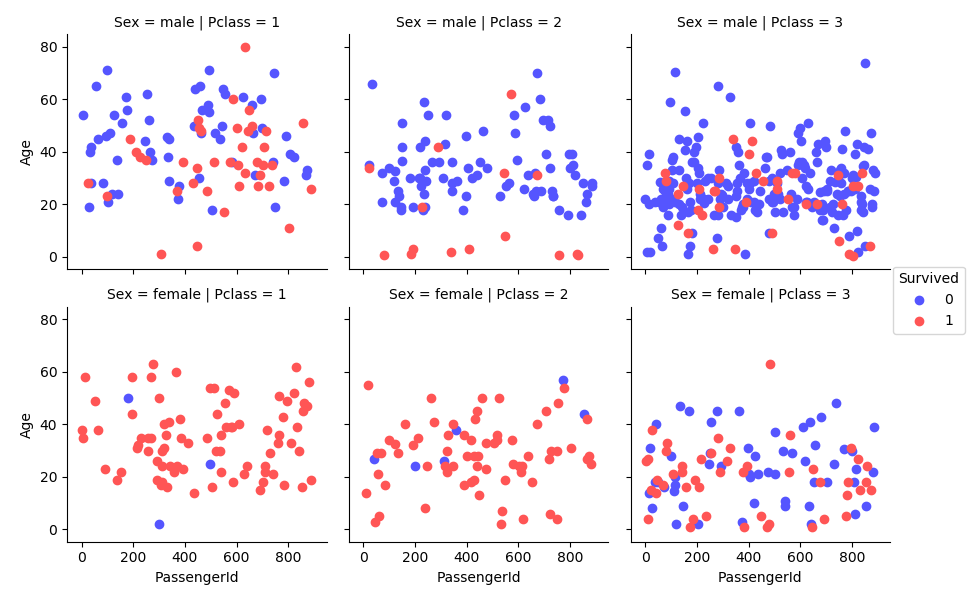
Survival by Age, Class and Gender
grid = sns.FacetGrid(train_df, col = "Pclass", row = "Sex", hue = "Survived", palette = 'seismic')
grid = grid.map(plt.scatter, "PassengerId", "Age")
grid.add_legend()

三、处理数据
3.1 去掉没得用的特征
删除数据中对预测没有实际效果的特征,提高模型速度,减少分析流程。
需要删除的特征有:客舱号码Cabin、票号Tickets
train_df = train_df.drop(['Ticket','Cabin'],axis=1)
test_df = test_df.drop(['Ticket','Cabin'],axis=1)
3.2 建立新的特征
对人名进行分析发现,带有master的一般都活下来了,于是对人名进行拆分,提取,和.之间的数据
combine = [train_df, test_df]
for dataset in combine:
dataset['Title'] = dataset.Name.str.extract('([A-Za-z]+)\.',expand=False)
Kaggle项目实战一:Titanic: Machine Learning from Disaster的更多相关文章
- 机器学习案例学习【每周一例】之 Titanic: Machine Learning from Disaster
下面一文章就总结几点关键: 1.要学会观察,尤其是输入数据的特征提取时,看各输入数据和输出的关系,用绘图看! 2.训练后,看测试数据和训练数据误差,确定是否过拟合还是欠拟合: 3.欠拟合的话,说明模 ...
- Kaggle:Titanic: Machine Learning from Disaster
一直想着抓取股票的变化,偶然的机会在看股票数据抓取的博客看到了kaggle,然后看了看里面的题,感觉挺新颖的,就试了试. 题目如图:给了一个train.csv,现在预测test.csv里面的Passa ...
- Kaggle比赛(一)Titanic: Machine Learning from Disaster
泰坦尼克号幸存预测是本小白接触的第一个Kaggle入门比赛,主要参考了以下两篇教程: https://www.cnblogs.com/star-zhao/p/9801196.html https:// ...
- miniFTP项目实战一
项目简介: 在Linux环境下用C语言开发的Vsftpd的简化版本,拥有部分Vsftpd功能和相同的FTP协议,系统的主要架构采用多进程模型,每当有一个新的客户连接到达,主进程就会派生出一个ftp服务 ...
- 电子商务网站SQL注入项目实战一例
故事A段:发现整站SQL对外输出: 有个朋友的网站,由于是外包项目,深圳某公司开发的,某天我帮他检测了一下网站相关情况. 我查看了页面源代码,发现了个惊人的事情,竟然整站打印SQL到Html里,着实吓 ...
- python3.6+selenium3.13 自动化测试项目实战一
自己亲自写的第一个小项目,学了几天写出来的一个小模块,可能还不是很完美,但是还算可以了,初学者看看还是很有用的,代码注释不是很多,有问题可以加我QQ 281754043 一.项目介绍 目的: 测试某官 ...
- kaggle _Titanic: Machine Learning from Disaster
A Data Science Framework: To Achieve 99% Accuracy https://www.kaggle.com/ldfreeman3/a-data-science-f ...
- docker自动化部署前端项目实战一
docker自动化部署前端项目实战一 本文适用于个人项目,如博客.静态文档,不涉及后台数据交互,以部署文档为例. 思路 利用服务器node脚本,监听github仓库webhook push事件触发po ...
- Tensorflow项目实战一:MNIST手写数字识别
此模型中,输入是28*28*1的图片,经过两个卷积层(卷积+池化)层之后,尺寸变为7*7*64,将最后一个卷积层展成一个以为向量,然后接两个全连接层,第一个全连接层加一个dropout,最后一个全连接 ...
随机推荐
- mysql学习笔记--列属性
一.是否为空----null || not null 二.默认值----default 三.自动增长----auto_increment 四.主键----primary key 1. 主键:唯一标识表 ...
- Oracle导出csv时数字不变成科学计数法
导出成CSV后,用excel打开,点击excel的[数据]→[自文本],选择导出的csv文件,下一步,分隔符选择[逗号],下一步,选择所有列“按住shift+鼠标左键选取”后,列数据格式选文本,[完成 ...
- linux文本格式转换
问题:在linux环境下面执行SH的可执行文件. -bash: ./start.sh: /bin/sh^M: bad interpreter: No such file or directory 解决 ...
- 186. Reverse Words in a String II 翻转有空格的单词串 里面不变
[抄题]: Given an input string , reverse the string word by word. Example: Input: ["t"," ...
- 149. Max Points on a Line同一条线上的最多点数
[抄题]: Given n points on a 2D plane, find the maximum number of points that lie on the same straight ...
- journalctl 清理journal日志
在CentOS 7开始使用的systemd使用了journal日志,这个日志的管理方式和以往使用syslog的方式不同,可以通过管理工具维护. 使用df -h检查磁盘文件,可以看到/run目录下有日志 ...
- docker 镜像存放路径的修改
可以通过在启动时使用--graph参数来指定存储路径. 或者使用systemd来管理服务, 就在/lib/systemd/system/docker.service中修改这一行: 1.ExecStar ...
- sublime text 换行与不换行设置
# 修改添加如下图右侧红框内容即可- 打开文件不换行
- REdis AOF文件结构分析
REdis-4.0之前的AOF文件没有文件头,而从REdis-4.0开始AOF文件带有一个文件头,文件头格式和RDB文件头相同. REdis-4.0版本,如果开启aof-use-rdb-preambl ...
- PHP查看内存使用
第一想法:memory_get_usage() 用microtime函数就可以分析程序执行时间memory_get_usage可以分析内存占用空间 SQL的效率可以使用打开慢查询查看日志分析SQL 找 ...