【转载】MapReduce编程 Intellij Idea配置MapReduce编程环境
介绍如何在Intellij Idea中通过创建maven工程配置MapReduce的编程环境。
一、软件环境
我使用的软件版本如下:
- Intellij Idea 2017.1
- Maven 3.3.9
- Hadoop伪分布式环境( 安装教程可参考这里)
二、创建maven工程
打开Idea,file->new->Project,左侧面板选择maven工程。(如果只跑MapReduce创建Java工程即可,不用勾选Creat from archetype,如果想创建web工程或者使用骨架可以勾选) 
设置GroupId和ArtifactId,下一步。 
设置工程存储路径,下一步。 
Finish之后,空白工程的路径如下图所示。

完整的工程路径如下图所示:

三、添加maven依赖
在pom.xml添加依赖,对于Hadoop 2.7.3版本的hadoop,需要的jar包有以下几个:
- hadoop-common
- hadoop-hdfs
- hadoop-mapreduce-client-core
- hadoop-mapreduce-client-jobclient
log4j( 打印日志)
pom.xml中的依赖如下:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>四、配置log4j
在src/main/resources目录下新增log4j的配置文件log4j.properties,内容如下:
log4j.rootLogger = debug,stdout
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
五、启动Hadoop
启动Hadoop,运行命令:
cd hadoop-2.7.3/
./sbin/start-all.sh访问http://localhost:50070/查看hadoop是否正常启动。
六、运行WordCount(从本地读取文件)
在工程根目录下新建input文件夹,input文件夹下新增dream.txt,随便写入一些单词:
I have a dream
a dream在src/main/java目录下新建包,新增FileUtil.java,创建一个删除output文件的函数,以后就不用手动删除了。内容如下:
package com.mrtest.hadoop;
import java.io.File;
/**
* Created by bee on 3/25/17.
*/
public class FileUtil {
public static boolean deleteDir(String path) {
File dir = new File(path);
if (dir.exists()) {
for (File f : dir.listFiles()) {
if (f.isDirectory()) {
deleteDir(f.getName());
} else {
f.delete();
}
}
dir.delete();
return true;
} else {
System.out.println("文件(夹)不存在!");
return false;
}
}
}编写WordCount的MapReduce程序WordCount.java,内容如下:
package com.mrtest.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
/**
* Created by bee on 3/25/17.
*/
public class WordCount {
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
public static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
public static class IntSumReduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for (Iterator i = values.iterator(); i.hasNext(); sum += val.get()) {
val = (IntWritable) i.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static void main(String[] args)
throws IOException, ClassNotFoundException, InterruptedException {
FileUtil.deleteDir("output");
Configuration conf = new Configuration();
String[] otherArgs = new String[]{"input/dream.txt","output"};
if (otherArgs.length != 2) {
System.err.println("Usage:Merge and duplicate removal <in> <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "WordCount");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setReducerClass(WordCount.IntSumReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
运行完毕以后,会在工程根目录下增加一个output文件夹,打开output/part-r-00000,内容如下:
I 1
a 2
dream 2
have 1这里在main函数中新增了一个String类型的数组,如果想用main函数的args数组接受参数,在运行时指定输入和输出路径也是可以的。运行WordCount之前,配置Configuration并指定Program arguments即可。

七、运行WordCount(从HDFS读取文件)
在HDFS上新建文件夹:
hadoop fs -mkdir /worddir如果出现Namenode安全模式导致的不能创建文件夹提示:
mkdir: Cannot create directory /worddir. Name node is in safe mode.运行以下命令关闭safe mode:
hadoop dfsadmin -safemode leave上传本地文件:
hadoop fs -put dream.txt /worddir修改otherArgs参数,指定输入为文件在HDFS上的路径:
String[] otherArgs = new String[]{"hdfs://localhost:9000/wo
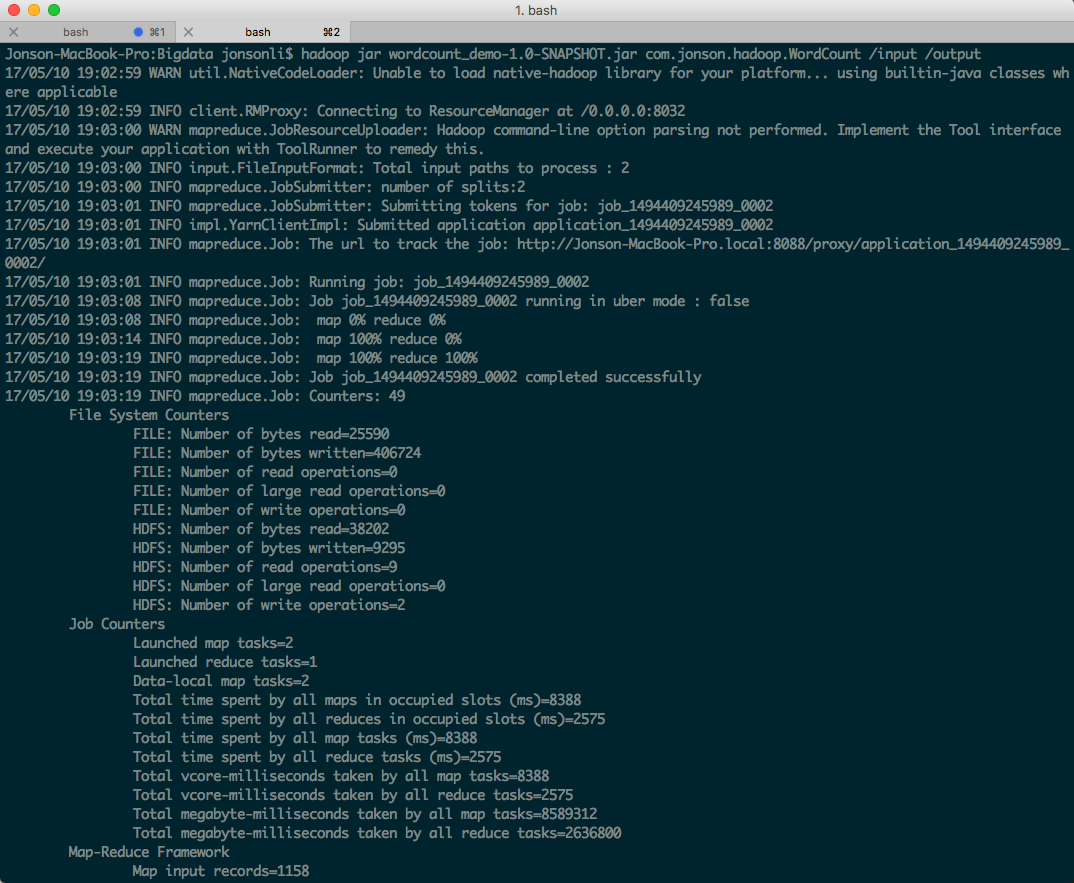
验证过程:
【转载】MapReduce编程 Intellij Idea配置MapReduce编程环境的更多相关文章
- Intellij idea配置scala开发环境
1.Intellij idea配置scala开发环境 解决Plugin Scala was not installed: No route to host Plugin Scala was not i ...
- MapReduce编程(一) Intellij Idea配置MapReduce编程环境
介绍怎样在Intellij Idea中通过创建mavenproject配置MapReduce的编程环境. 一.软件环境 我使用的软件版本号例如以下: Intellij Idea 2017.1 Mave ...
- 使用IntelliJ IDEA配置Erlang开发环境
这篇文章比较详细,感谢作者,拷贝过来做个记录 ————————————————————————————————————————————————————————————————————————————— ...
- Intellij Idea配置MapReduce编程环境
原文参考地址:http://www点w2bc点com/article/229178 增加内容:question1: Hadoop2以上版本时,在Hadoop2的bin目录下没有winutils.exe ...
- 【转载】使用IntelliJ IDEA 配置Maven(入门)
1. 下载Maven 官方地址:http://maven.apache.org/download.cgi 解压并新建一个本地仓库文件夹 2.配置本地仓库路径 3.配置maven环境变量 ...
- Intellij IDEA配置PHP开发环境
Intellij IDEA是一款非常强大的编译器,能很好地支持JavaHTML CSS等.当然,加入PHP语言也是小菜一碟~ 环境: Windows 7.Intellij IDEA 2016.2.5. ...
- MapReduce On Yarn的配置详解和日常维护
MapReduce On Yarn的配置详解和日常维护 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce运维概述 MapReduce on YARN的运维主要是 ...
- WCF分布式开发步步为赢(4):WCF服务可靠性传输配置与编程开发
今天继续WCF分布式开发步步为赢系列的第4节:WCF服务可靠性传输配置与编程开发.这个章节,我们要介绍什么是WCF服务的可靠性传输,随便介绍网络协议的概念,Web Service为什么不支持可靠性传出 ...
- WCF分布式开发步步为赢(3)WCF服务元数据交换、配置及编程开发
今天我们继续WCF分布式开发步步为赢(3)WCF服务元数据交换.配置及编程开发的学习.经过前面两节的学习,我们了解WCF分布式开发的相关的基本的概念和自定义宿主托管服务的完整的开发和配置过程.今天我们 ...
随机推荐
- 前后端通过API交互
前两篇已经写好了后端接口,和前段项目环境也搭建好了 现在要通过接口把数据展示在页面上 先占位置写架子 创建一个头部组件和底部组件占位置 <template> <h1>这是头部组 ...
- python基础一 ------顺序结构队列的python实现
队列:先进先出的线性表(FIFO),只允许在一段插入并在另一端取出 以下是python实现 #-*-coding:utf-8-*- #顺序存储队列的python实现 class Queue(objec ...
- Python2048小游戏demo
# -*- coding:UTF-8 -*- #! /usr/bin/python3 import random v = [[0, 0, 0, 0], [0, 0, 0, 0], [0, 0, 0, ...
- 基于asp.net的excel导入导出
新建aspx文件.代码大概如下: <!--导入Excel文件--> <table width="99%" border="0" align=& ...
- 使用requests进行模拟登陆
import re import requests header = { 'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWe ...
- SpringMVC的请求处理流程
- python 有参装饰器与迭代器
1.有参装饰器 模板: def auth(x): def deco(func): def timmer(*args,**kwargs ): res = func(*args,**kwargs ) re ...
- .net 4.0 中的特性总结(四):Tuple类型
Tuple是具有指定数量和顺序的值的一种数据结构.针对这种数据结构,.Net4.0中提供了一组Tuple类型,具体如下: Tuple Tuple<T> Tuple<T1, T ...
- Redis 数据变化通知服务实践
从Redis 2.8.0版本起,Redis加入了“Keyspace notifications”(即“键空间通知”)的功能.键空间通知,允许Redis客户端从“发布/订阅”通道中建立订阅关系,以便客户 ...
- 1. cs231n k近邻和线性分类器 Image Classification
第一节课大部分都是废话.第二节课的前面也都是废话. First classifier: Nearest Neighbor Classifier 在一定时间,我记住了输入的所有的图片.在再次输入一个图片 ...