【NLP】MT中BLEU评分机制
参考博客:https://blog.csdn.net/guolindonggld/article/details/56966200
原著论文:http://www.aclweb.org/anthology/P02-1040.pdf
BLEU是2002年IBM研究人员提出的一种自动评价MT翻译质量的方法。其本质是比对MT给出的结果(称为候选翻译,candidate)和事前知道的比较好的若干个翻译样本(称为参考翻译,reference,通常是人工翻译给出的数据),比较两者之间的相似度。
在计算这个相似度的时候,最基本的策略是从candidate中逐步取出一些内容,考察这些内容,去检查各个参考翻译中是否存在相同的内容。如果相同的内容出现频率越高,说明candidate的翻译越准确。将这个频率量化为某个指标P (这个指标是针对某个内容子集而言的)。当我们把candidate中所有信息都考察完毕,没有漏掉的东西之后,加和所有的指标P,所得到的分数越高,自然翻译就是越准确的。
那么具体取出的是什么内容? 很自然想到的是单个单个的词。不过单个词的抽出内容(所谓的1-gram词模型)的一个问题是常用词陷阱。比如candidate中含有大量的the,in这类常用词但是翻译质量并不高时,由于是常用词,必然也在所有的reference中也都有出现,反而会导致分数比较高。为了解决这个问题,我们可以做两点改进:
1. 将1-gram升高为N-gram,加强匹配的严格性。不过直接将此模型提升到N-gram,可能会导致太严格,所以可以折中,以一定的权重将1-gram,2-gram... N-gram各个模型得到的值做一个平均作为最终的分数。这个平均一般是加权几何平均。
2. 另一个想法,则是对量化指标这个过程做些调整。之前没有具体说明量化指标的过程是怎么做的,不过可以感到,需要一个机制来统合而不是那么傻乎乎地去计算频率。比如某个词或词组在candidate中出现了好几次该怎么算,不同reference中出现次数又不相同又该怎么办
综合上述考虑,BLEU给出的PN值的计算公式是min( candidate.count(w), max(reference1.count(w), reference2.count(w)... referenceN.count(w) ) ) / candidate.count(w) 。也就是说,针对某个从candidate中选出的词或词组w,首先求出各个reference中其出现次数的最大值,然后取这个值与candidate中w出现次数两者中较小的值。然后将这个值除以candidate中w出现次数。首先可以确定,这个值肯定是小于等于1的。
其次,上面这个公式是针对一个要素w的情况,实际上翻译结果中有w1,w2...wn那么多,那么这些结果的所有分子加起来除以所有分母加起来,得到的就是PN了。
当然不要忘了,之前我们说可以将1,2...N-gram的结果都要拿来用。另外对加权几何平均进行一个对数化处理,于是我们就得到了
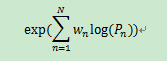 这样一个公式了。
这样一个公式了。
由于最外面套了一个exp,而exp里面的玩意儿必然小于0,所以最终产出肯定是一个小于1的正值。
这样看似不错了。不过还有BLEU的第二个陷阱需要解决,即短句陷阱。比如中文中有一句“猫XXXX”的句子,那么英语翻译时几乎必然会出现the cat这个词组。如果MT的翻译结果就是“the cat”,此时candidate长度就只有2,因此也就只能做到1-gram和2-gram的评估。然而不合理的地方在于,即便是漏译了很多内容,在评估模型看来,P1和P2还是有可能会比较高的。因为所有reference中都几乎必然出现the cat这个词组。
换言之,目前模型对于短翻译句的评估还不是很合理,原因是当candidate长度过短时,我们只能做到有限的N-gram模型就不得不作罢。
为了修正这个错误,BLEU提出的解决方案是引入BP(Brevity Penalty)即过短惩罚。相比于上面复杂的计算,BP的计算就要简单很多了,首先从reference中找出长度与candidate最为相近的一条。如果此条长度大于candidate长度,那么定义BP为exp(1 - r/c)。反之,如果candidate长度大于最接近的reference长度,那么直接定义BP为1。
将BP乘以上面算式算出的指标,便可得到一个大于0小于1的BLEU分数了。
总的公式: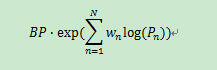
一般MT研究中,BLEU作为标杆,有比较重要的意义。各种MT模型的目标都是为了让BLEU上升。
【NLP】MT中BLEU评分机制的更多相关文章
- lucene 的评分机制
lucene 的评分机制 elasticsearch是基于lucene的,所以他的评分机制也是基于lucene的.评分就是我们搜索的短语和索引中每篇文档的相关度打分. 如果没有干预评分算法的时候,每次 ...
- Solr In Action 笔记(2) 之 评分机制(相似性计算)
Solr In Action 笔记(2) 之评分机制(相似性计算) 1 简述 我们对搜索引擎进行查询时候,很少会有人进行翻页操作.这就要求我们对索引的内容提取具有高度的匹配性,这就搜索引擎文档的相似性 ...
- Wifi 评分机制分析
从android N开始,引入了wifi评分机制,选择wifi的时候会通过评分来选择. android O源码 frameworks\opt\net\wifi\service\java\com\and ...
- Elasticseach的评分机制
lucene 的评分机制 elasticsearch是基于lucene的,所以他的评分机制也是基于lucene的.评分就是我们搜索的短语和索引中每篇文档的相关度打分. 如果没有干预评分算法的时候,每次 ...
- Lucene Scoring 评分机制
原文出处:http://blog.chenlb.com/2009/08/lucene-scoring-architecture.html Lucene 评分体系/机制(lucene scoring)是 ...
- Deep Learning基础--理解LSTM/RNN中的Attention机制
导读 目前采用编码器-解码器 (Encode-Decode) 结构的模型非常热门,是因为它在许多领域较其他的传统模型方法都取得了更好的结果.这种结构的模型通常将输入序列编码成一个固定长度的向量表示,对 ...
- Lucene 的 Scoring 评分机制
转自: http://www.oschina.net/question/5189_7707 Lucene 评分体系/机制(lucene scoring)是 Lucene 出名的一核心部分.它对用户来 ...
- 理解LSTM/RNN中的Attention机制
转自:http://www.jeyzhang.com/understand-attention-in-rnn.html,感谢分享! 导读 目前采用编码器-解码器 (Encode-Decode) 结构的 ...
- 从NLP任务中文本向量的降维问题,引出LSH(Locality Sensitive Hash 局部敏感哈希)算法及其思想的讨论
1. 引言 - 近似近邻搜索被提出所在的时代背景和挑战 0x1:从NN(Neighbor Search)说起 ANN的前身技术是NN(Neighbor Search),简单地说,最近邻检索就是根据数据 ...
随机推荐
- Java -- 内部类(二)
在上一篇博客Java --内部类(一)中已经提过了,java中的内部类主要有四种:成员内部类.局部内部类.匿名内部类.静态内部类. 该文主要介绍这几种内部类. 成员内部类 成员内部类也是最普通的内部类 ...
- SpringMVC处理器映射器和方法名称解析器
所谓配置式开发是指,“处理器类是程序员手工定义的,实现了特定接口的类,然后再在SpringMVC配置文件中对该类进行显式的,明确的注册”的开发方式” 1.处理器映射器HandlerMapping Ha ...
- 关于 win10启动错误 Error:16
那个软件报这个错误,就打开属性 -- 兼容性 -- 打勾以管理员身份运行
- BZOJ1423 : Optimus Prime
设$f[x]$表示为了保证自己可以取到质数$x$,第一步在$[0,n]$中可以选的数是多少. 这个数是唯一的,因为如果存在两个$f[x]=a,b(a<b)$,那么如果先手取了$a$,后手就能取$ ...
- 编程菜鸟的日记-初学尝试编程-C++ Primer Plus 第5章编程练习2
#include <iostream>using namespace std;const int MAXSIZE=100;int main(){ int a[MAXSIZE]; int s ...
- learning to generate question headlines 讲座
渣排版预警! 出发点 新闻用户为什么会点: 主观:用户兴趣/热点事件 客观:新闻标题(新闻入口)/新闻内容(更简单,更有趣) 标题分类: surprise,好奇,负例,数字,你,客观的描述,问题的形式 ...
- 常用的sort打乱数组方法真的有用?
JavaScript 开发中有时会遇到要将一个数组随机排序(shuffle)的需求,一个常见的写法是这样: function shuffle(arr) { arr.sort(function () { ...
- CSS_盒子模型
2016-10-22 <css入门经典>第6章 1.每个HTML元素对应于一个显示盒子,但不是所有的元素都显示在屏幕上. 2.HTML元素显示为CSS显示盒子的真正方法称为“可视格式化方式 ...
- 用css实现自定义虚线边框
开发产品功能的时候ui往往会给出虚线边框的效果图,于是乎,我们往往第一时间想到的是用css里的border,可是border里一般就提供两种效果,dashed或者dotted,ui这时就不满意了,说虚 ...
- 前端工程化系列[04]-Grunt构建工具的使用进阶
在前端工程化系列[02]-Grunt构建工具的基本使用和前端工程化系列[03]-Grunt构建工具的运转机制这两篇文章中,我们对Grunt以及Grunt插件的使用已经有了初步的认识,并探讨了Grunt ...