MySQL Cluster 数据分布(分区、分组)
数据分布
1、MySQL Cluster自动分区数据表(也可能使用用户自定义分区),将数据分布到分区中;
2、一个数据表被划分到多个Data Node分区中,数据在分区中被”striped”;
3、主键的 hashing 决定哪个分区拥有数据(自动分布);
4、对主键的一部分进行hashing也是可能的(适合sharding和数据局部性);
分区和数据分布
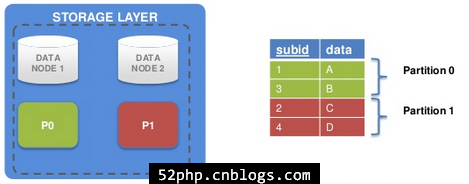
1、如果有两个数据节点(DATA NODE 1和DATA NODE 2),每个数据表都被分到两个分区中。
2、subid是主键,对主键subid进行的hashing决定分区。当然对主键的一分部分(part of PK)进行hashing也是可能的。
- -奇数主键(绿色部分)
- -偶数主键(红色部分)
副本(Replicas)
1、为了提供冗余和快速故障转移,分区之间是同步复制的;
2、最常用的是用两个副本(两份数据):
- - 使用1个,2个,3个,4个副本也都是可能的
- - NoOfReplicas=2


3、分区间的同步复制是从主分区(PRIMARY)到辅助分区(SECONDARY)
- - 当有一个变更(下图实体圆心表示变更)发生在P0的时候,它将同步复制到S0
- - 这个变更在事务commit的时候被持久化
- - P0或S0将被更新,或什么都不做

数据分布 – 磁盘日志记录(disk logging)
1、数据在commit之后会在主内存中(main memory)
(1).但是改变(changes)是REDO日志记录的(REDO LOGGED),而REDO日志是每N毫秒(推荐1000ms)刷新到磁盘
由TimeBetweenGlobalCheckpoints参数控制
类似innodb-flush-log-at-trx_commit=2
(2).数据同时被checkpoint到磁盘
2、磁盘日志记录使得恢复一个完全失败的cluster成为可能
节点组(Node groups)
1、共享同样数据的节点属于同一个节点组
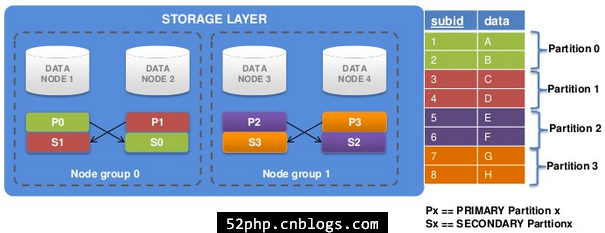
2、一个节点组包含节点数等于副本数。(下图使用NoOfReplicas=2)

3、两个副本-四个数据节点
(1).四个数据节点-四个分区-两个副本
(2).四个节点和两个副本–>两个节点组
- 节点组数目 = 总节点数 / 副本数
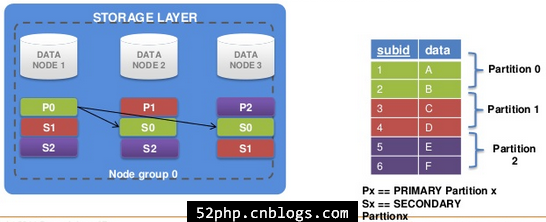
4、三个副本-三个数据节点
(1).三个数据节点-三个分区
- 更多的副本,“写”更慢
(2).三个节点和三个副本–>一个节点组(这种方式不常用)
- 两个副本是惯例
5、副本使用建议
(1).推荐使用两个副本- 性能和可用性是最好的折衷
(2).三个或四个副本写比较慢,使用这种方式部署相对更少
(3).“写”成本
- 1个副本(没冗余): cost X
- 2个副本: cost 2X
- 三个副本: cost 3X
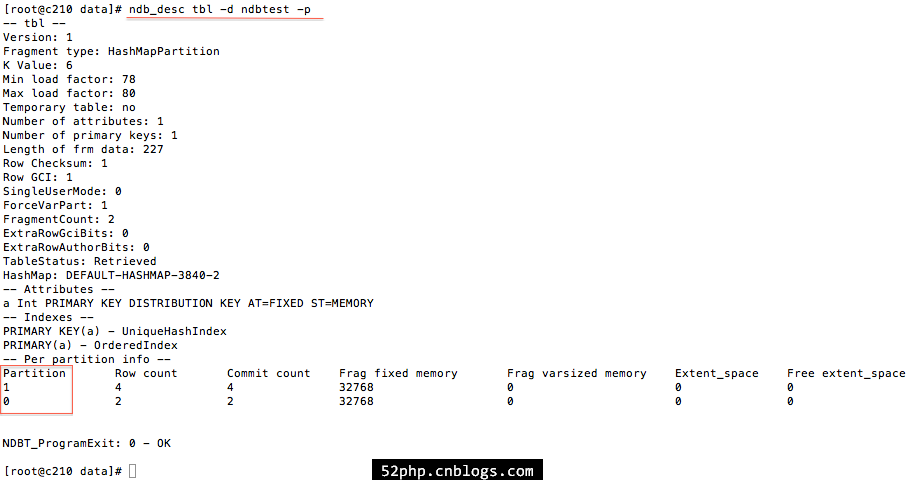
验证数据分布
用法:
ndb_desc -c connect_string tbl_name -d db_name [-p]
mysql> select * from ndbtest.tbl;
+---+
| a |
+---+
| 3 |
| 6 |
| 5 |
| 1 |
| 2 |
| 4 |
+---+
6 rows in set (0.01 sec) mysql>
参考:
MySQL Cluster 数据分布(分区、分组)的更多相关文章
- MySQL Cluster配置概述
一. MySQL Cluster概述 MySQL Cluster 是一种技术,该技术允许在无共享的系统中部署“内存中”数据库的 Cluster .通过无共享体系结构,系统能够使用廉价的硬件,而 ...
- MySQL的表分区详解
这篇文章主要介绍了MySQL的表分区,例如什么是表分区.为什么要对表进行分区.表分区的4种类型详解等,需要的朋友可以参考下 一.什么是表分区通俗地讲表分区是将一大表,根据条件分割成若干个小表.mysq ...
- MySQL的表分区(转载)
MySQL的表分区(转载) 一.什么是表分区 通俗地讲表分区是将一大表,根据条件分割成若干个小表.mysql5.1开始支持数据表分区了. 如:某用户表的记录超过了600万条,那么就可以根据入库日期将表 ...
- mysql数据库表分区详解(数量过大的数据库表通过分区提高查询速度)
这篇文章主要介绍了MySQL的表分区,例如什么是表分区.为什么要对表进行分区.表分区的4种类型详解等,需要的朋友可以参考下 一.什么是表分区通俗地讲表分区是将一大表,根据条件分割成若干个小表.mysq ...
- mysql中的分区
第18章:分区 目录 18.1. MySQL中的分区概述 18.2. 分区类型 18.2.1. RANGE分区 18.2.2. LIST分区 18.2.3. HASH分区 18.2.4. KEY分区 ...
- MySQL Cluster 与 MongoDB 复制群集分片设计及原理
分布式数据库计算涉及到分布式事务.数据分布.数据收敛计算等等要求 分布式数据库能实现高安全.高性能.高可用等特征,当然也带来了高成本(固定成本及运营成本),我们通过MongoDB及MySQL Clus ...
- mysql集群 MySQL Cluster
<?php /* 郑重说明2015年6月11日16:28:14,目前为止MySQL Cluster 社区版不支持INNODB,商业版支持,但是授权价格20W左右,so看此文档之前,考虑下钱 My ...
- [置顶] MySQL Cluster初步学习资料整理--安装部署新特性性能测试等
1.1 mysql-cluster简介 简单的说,MySQLCluster实际上是在无共享存储设备的情况下实现的一种完全分布式数据库系统,其主要通过NDBCluster(简称NDB)存储引擎来实现. ...
- MySQL Cluster
MySQL Cluster MySQL集群一个非共享(shared nothing).分布式.分区系统,使用同步复制机制提供高可用和高性能. MySQL集群使用的是NDB引擎.NDB存储引擎会在节点间 ...
随机推荐
- 洛谷P1782 旅行商的背包[多重背包]
题目描述 小S坚信任何问题都可以在多项式时间内解决,于是他准备亲自去当一回旅行商.在出发之前,他购进了一些物品.这些物品共有n种,第i种体积为Vi,价值为Wi,共有Di件.他的背包体积是C.怎样装才能 ...
- 二分法&三分法
ural History Exam 二分 #include <iostream> #include <cstdlib> using namespace std; //二分 ...
- python yield from用法
Reading data from a generator using yield from def reader(): """A generator that fake ...
- [No000084]C# 使用Log4Net(1)-快速建立一个demo
1.下载Log4Net: http://logging.apache.org/log4net/download_log4net.cgi 2.新建一个WinForm程序,取名Log4NetDemo 3. ...
- Python黑客编程ARP欺骗
Python灰帽编程 3.1 ARP欺骗 ARP欺骗是一种在局域网中常用的攻击手段,目的是让局域网中指定的(或全部)的目标机器的数据包都通过攻击者主机进行转发,是实现中间人攻击的常用手段,从而实现数据 ...
- CWMP开源代码研究4——认证流程
TR069 Http Digest 认证流程 一 流程及流程图 1.1盒端主动发起Http Digest认证流程 盒端CPE ...
- 【转】【C#】迭代器
迭代器模式是设计模式中行为模式(behavioral pattern)的一个例子,他是一种简化对象间通讯的模式,也是一种非常容易理解和使用的模式.简单来说,迭代器模式使得你能够获取到序列中的所有元素而 ...
- 【ASP.NET实战教程】ASP.NET实战教程大集合,各种项目实战集合
[ASP.NET实战教程]ASP.NET实战教程大集合,各种项目实战集合,希望大家可以好好学习教程中,有的比较老了,但是一直很经典!!!!论坛中很多小伙伴说.net没有实战教程学习,所以小编连夜搜集整 ...
- Win10升级后回退后无法检测新版本的修复办法
笔记本原来装的是Win10 10240版本,升级到14393版本后进行了回退.回退后,Win10系统再也检测不到新版本更新了. 解决办法如下: 1.打开注册表:HKEY_LOCAL_MACHINE ...
- 使用StackExchange.Redis客户端进行Redis访问出现的Timeout异常排查
问题产生 这两天业务系统在redis的使用过程中,当并行客户端数量达到200+之后,产生了大量timeout异常,典型的异常信息如下: Timeout performing HVALS Parser2 ...