Spark对接Kafka、HBase
本项目是为网站日志流量分析做的基础:网站日志流量分析系统,Kafka、HBase集群的搭建可参考:使用Docker搭建Spark集群(用于实现网站流量实时分析模块),里面有关于该搭建过程
本次对接Kafka及HBase是基于使用Docker搭建Spark集群(用于实现网站流量实时分析模块)搭建的6个Docker容器来实现的对接。
代码地址:https://github.com/Simple-Coder/sparkstreaming-demo
一、SparkStreaming整合Kafka
1、maven代码

2、启动测试
2.1启动3个kafka并测试
生产端消息如下:

接收到的消息如下:
2.2spark提交jar任务,SparkStreaming消费Kafka消息
console-producer生产消息,spartkStreaming主动拉取消息,console-consumer也能收到消息,结果如下: 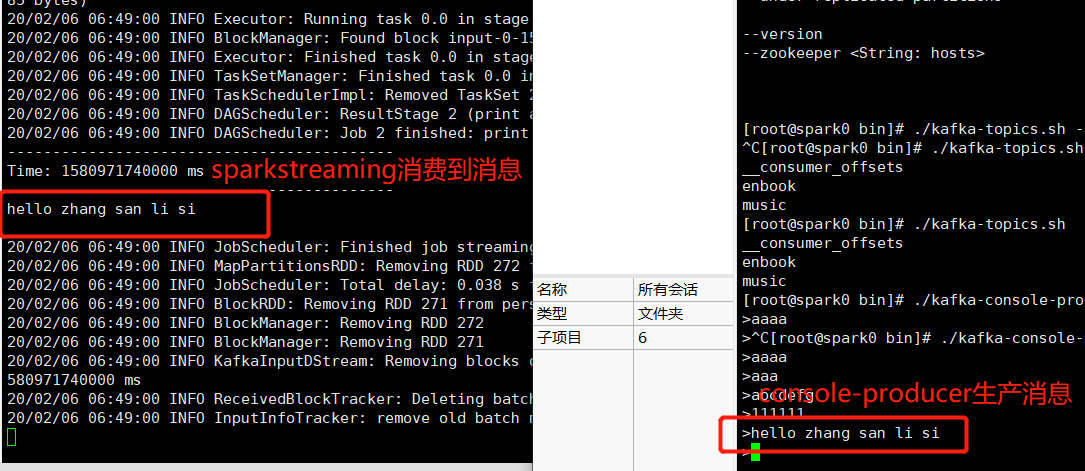
console-consumer接收到的消息如下:

至此、Spark对接Kafka完成
3、问题总结
KafkaUtils的选择,由于maven中央库只有1.6.3版本的spark-streaming-kafka,其他版本的spark-streaming-kafka-***的api调用个人不习惯,还是停留在之前的api,所以这可能是导致以下问题的所在,不过还好问题解决
①ClassNotFoundException: org.apache.kafka.common.utils.Utils:上传kafka-clients-0.8.2.0.jar至spark的jars目录
②java.lang.NoClassDefFoundError:org/apache/spark/streaming/kafka/KafkaUtils :上传kafka_2.11-0.8.2.1.jar、spark-streaming-kafka_2.11-1.6.3.jar至Spark的jars目录
③java.lang.NoClassDefFoundError:org/apache/spark/logging:开头maven结构图中,将工程jar上传至spark的jars目录
④NoClassDefFoundError: org/I0Itec/zkclient/serialize/ZkSerializer:上传zkclient-0.11.jar至spark的jars目录
二、SparkStreaming整合HBase
1、读取HBase表
1.1 scala代码

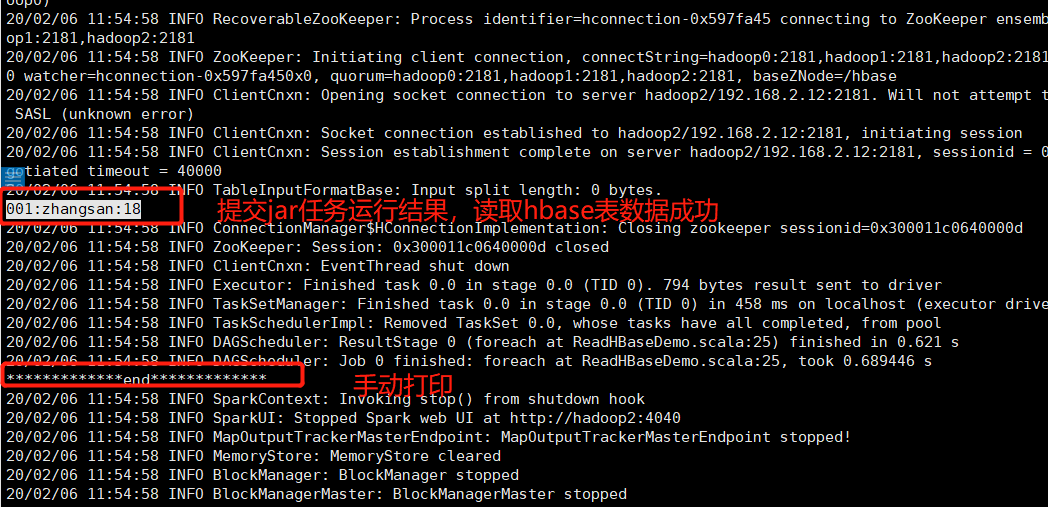
1.2 提交jar任务测试
由于是docker容器搭建的集群,本地不容易测试,只好提交jar至docker容器
提交任务截图如下:
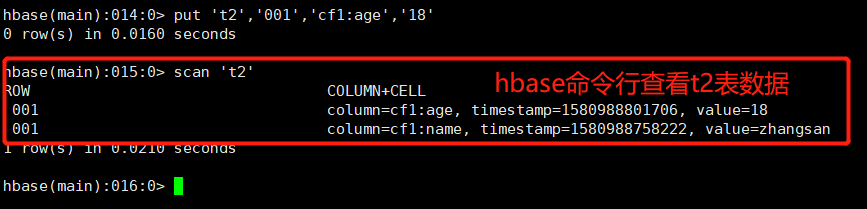
HBase表t2数据如下:
至此scala读取HBase数据成功,期间还是同样的问题,缺少关于HBase的jar,将maven依赖的HBase全部上传至Spark的jars目录下即可。
2、写入HBase表
2.1 scala代码
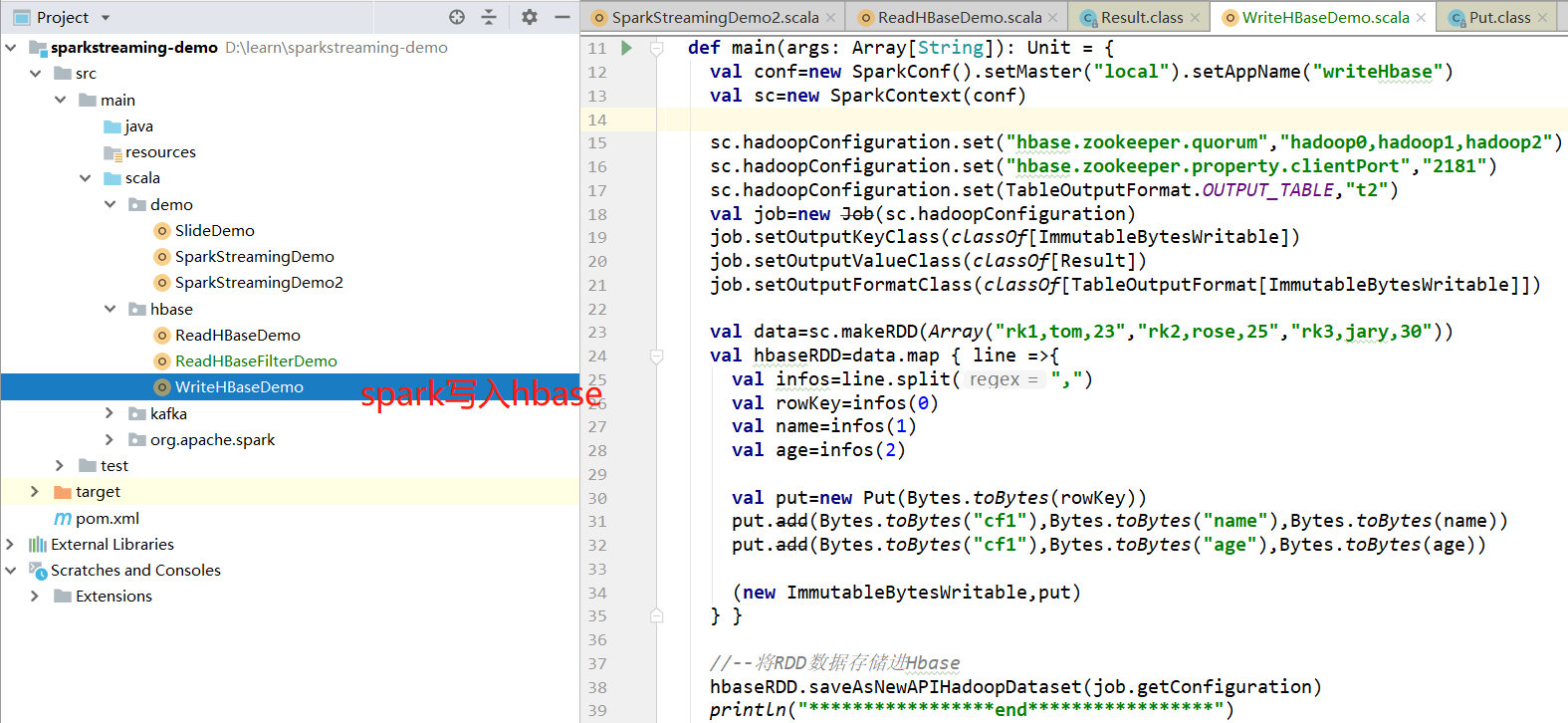
2.2 提交jar任务至spark测试
提交jar任务如下:
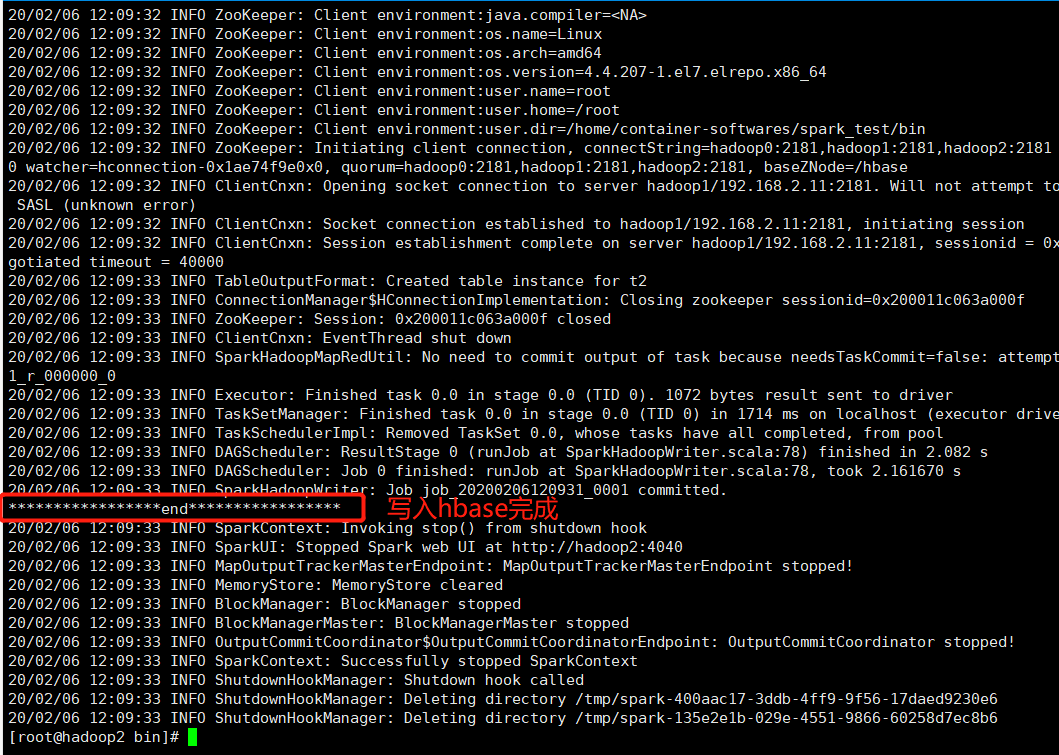
HBase命令行查看如下:
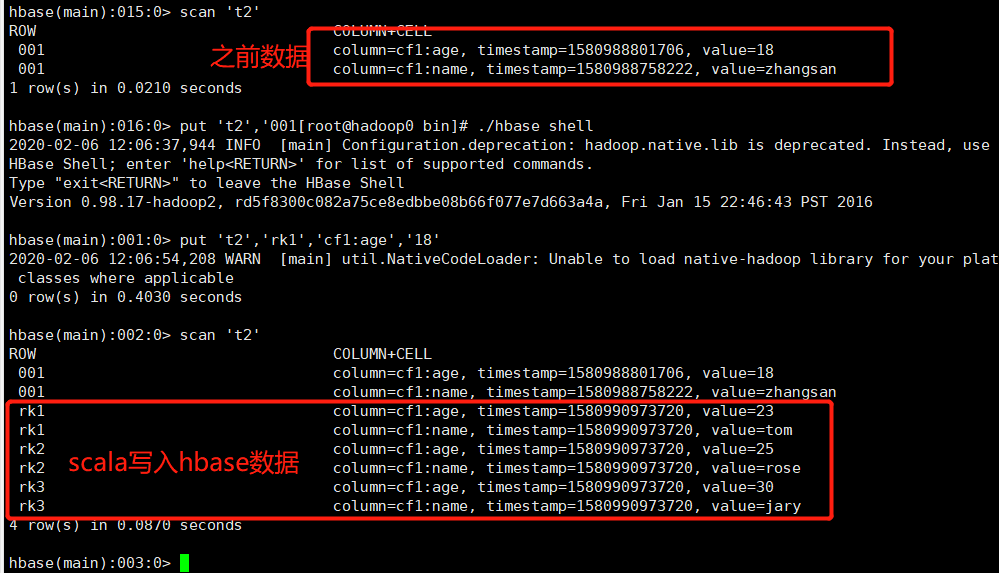
至此、spark写入hbase成功。
3、过滤器
随即的返回row的数据,chance取值为0到1.0,如果<0则为空,如果>1则包含所有的行。
3.1 scala代码
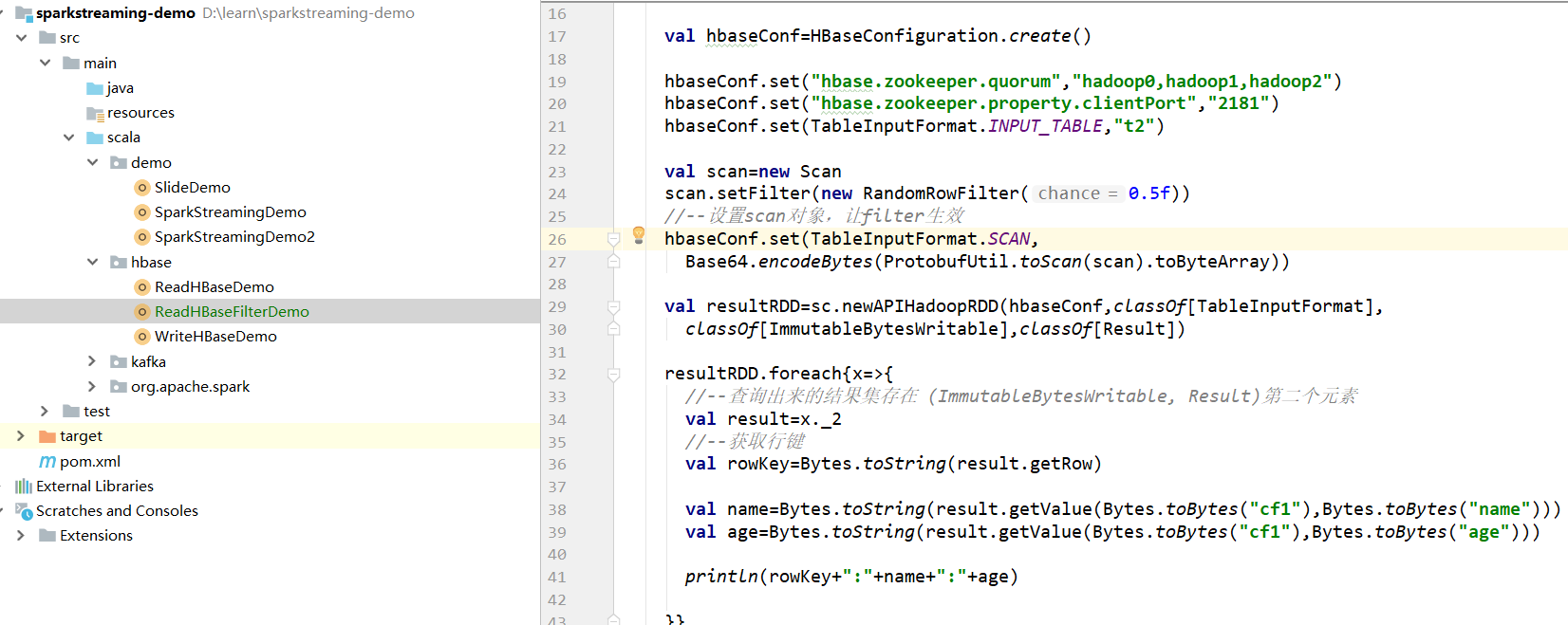
3.2 提交jar至spark测试
第一次如下:
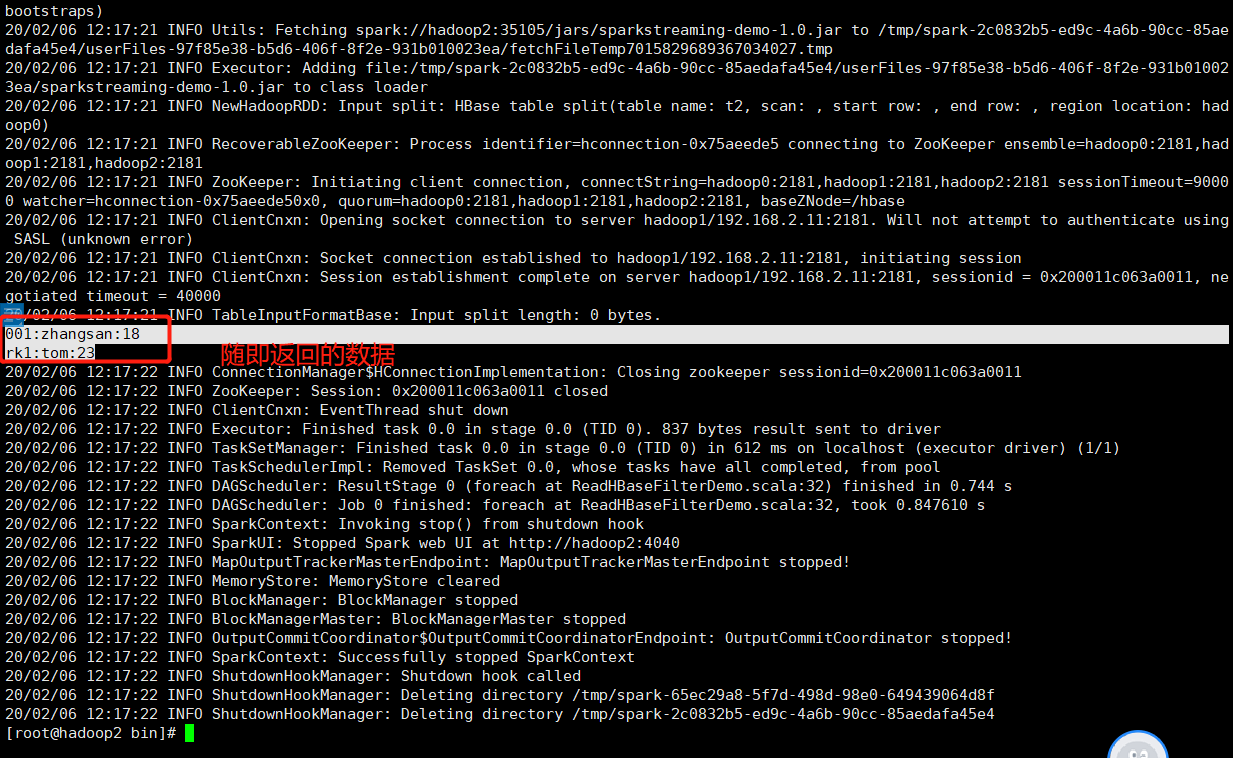
第二次如下:
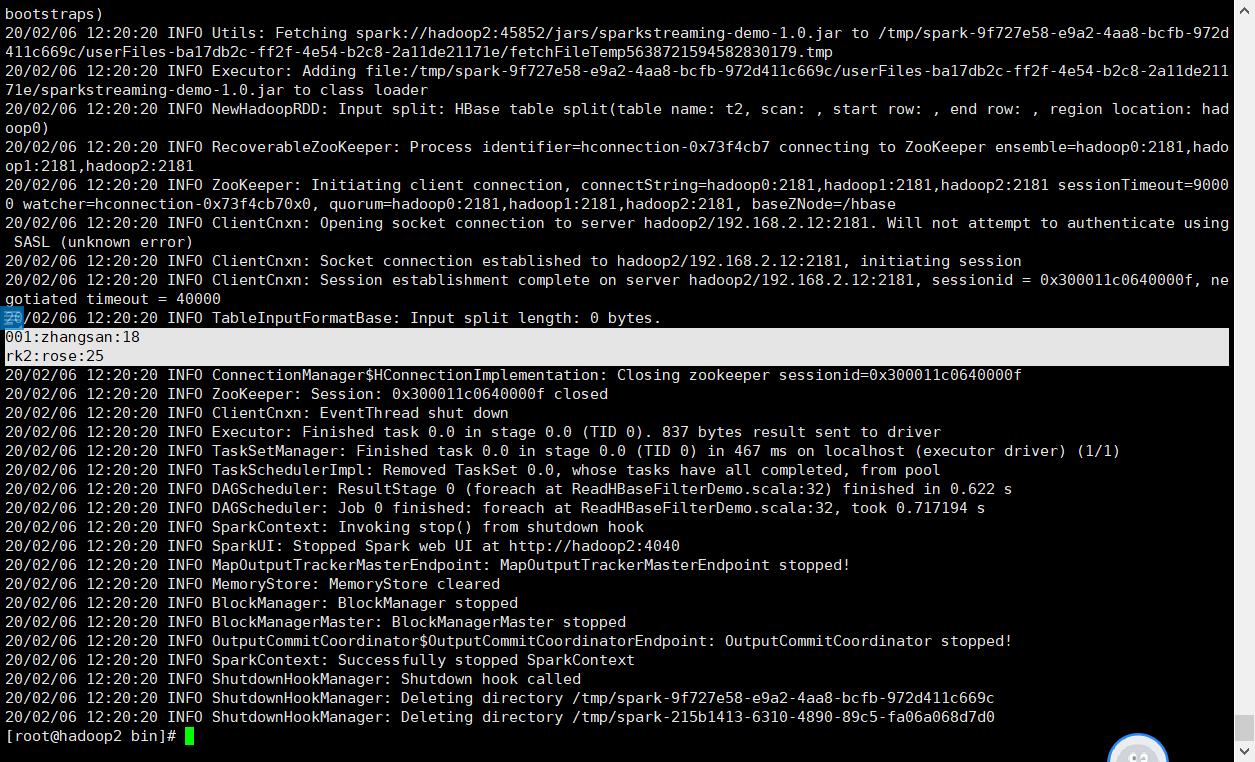
至此、spark对接kafka及HBase完成,欢迎各位读者指正、交流~
Spark对接Kafka、HBase的更多相关文章
- 大牛博客!Spark / Hadoop / Kafka / HBase / Storm
在这里,非常感谢下面的著名大牛们,一路的帮助和学习,给予了我很大的动力! 有了Hadoop,再次有了Spark,一次又一次,一晚又一晚的努力相伴! HBase简介(很好的梳理资料) 1. 博客主页:h ...
- spark streaming 对接kafka记录
spark streaming 对接kafka 有两种方式: 参考: http://group.jobbole.com/15559/ http://blog.csdn.net/kwu_ganymede ...
- kerberos环境下spark消费kafka写入到Hbase
一.准备环境: 创建Kafka Topic和HBase表 1. 在kerberos环境下创建Kafka Topic 1.1 因为kafka默认使用的协议为PLAINTEXT,在kerberos环境下需 ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
- spark与kafka集成进行实时 nginx代理 这种sdk埋点 原生日志实时解析 处理
日志格式202.108.16.254^A1546795482.600^A/cntv.gif?appId=3&areaId=8213&srcContId=2535575&area ...
- Spark踩坑记:Spark Streaming+kafka应用及调优
前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark streaming从k ...
- 4、spark streaming+kafka
一.Receiver模式 1. receiver模式原理图 在SparkStreaming程序运行起来后,Executor中会有receiver tasks接收kafka推送过来的数据.数据会被持久化 ...
- spark streaming kafka example
// scalastyle:off println package org.apache.spark.examples.streaming import kafka.serializer.String ...
随机推荐
- Wannafly Winter Camp 2020 Day 5J Xor on Figures - 线性基,bitset
有一个\(2^k\cdot 2^k\) 的全零矩阵 \(M\),给出 \(2^k\cdot 2^k\) 的 \(01\) 矩阵 \(F\),现在可以将 \(F\) 的左上角置于 \(M\) 的任一位置 ...
- 如何使用Mbp模块构建应用.
上一篇文章https://www.cnblogs.com/mbpframework/p/12073102.html,介绍了一下Mbp的框架.其实这个框架写出来主要是为了学习,当然也可以经过优化运用到实 ...
- c# 调用c++类库控制usb继电器
网上找不到调用此类库的文章,简单写一下,以备后用. 下面是封装后的调用c++类库的类 public class UsbRelayDeviceHelper { /// <summary> / ...
- 消息队列和Kafka
------20191211闪
- 《深入理解java虚拟机》读书笔记九——第十章
第十章 早期(编译期)优化 1.Javac的源码与调试 编译期的分类: 前端编译期:把*.java文件转换为*.class文件的过程.例如sun的javac.eclipseJDT中的增量编译器. JI ...
- 【C语言】求s(n)=a+aa+aaa+...+aa...a的值
原理:比如a=2,s(1)=2,s(2)=2+2*10+2,s(3)=2+2*10+2+(2*10+2)*10+2 ..... 规律: item=item*10+a sum=sum+item 代码 ...
- windows环境下安装JDK
一.环境准备 Windows10 jdk-9.0.1 二.下载并安装JDK 到Java的官网下载JDK安装包,地址:http://www.oracle.com/technetwork/java/jav ...
- 三行代码实现垂直居中和cube
三行代码实现上下居中 position: relative;top: 50%;transform: translateY(-50%); 效果如下: 代码: <!DOCTYPE html> ...
- (转)git fetch + merge 和 git pull 的区别
转自:http://blog.csdn.net/a19881029/article/details/42245955 Git fetch和git pull都可以用来更新本地库,它们之间有什么区别呢? ...
- 一起学Vue之列表渲染
在Vue开发中,列表数据绑定非常简单易用,本文主要通过一些简单的小例子,讲述v-for的使用方法,仅供学习分享使用,如有不足之处,还请指正. 用 v-for 把一个数组对应为一组元素 我们可以用 v- ...