HBase学习笔记(一)——基础入门
1、what:什么是HBase
HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。【非大勿用】
HBase是Google Bigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
上面的话太官方,挨个看都认识,连起来不理解。简单粗暴的总结:就是一款NoSQL数据库,面向列存储,用于存储处理海量数据。
核心在于它是一个存数据的地方,可是在此之前学习过了HDFS和Mysql,那HBase为什么还会出现呢?后边细说~
2、why:为什么会有HBase?
先说一下Mysql,我们都知道Mysql是一个关系型数据库,平时开发使用的非常频繁。一个网站或者系统最核心的表就是用户表,而当用户表的数据达到几千万甚至几亿级别的时候,对单条数据的检索将会耗费数秒甚至分钟级别。实际的清空可能更加复杂不堪。
看下边一张表:
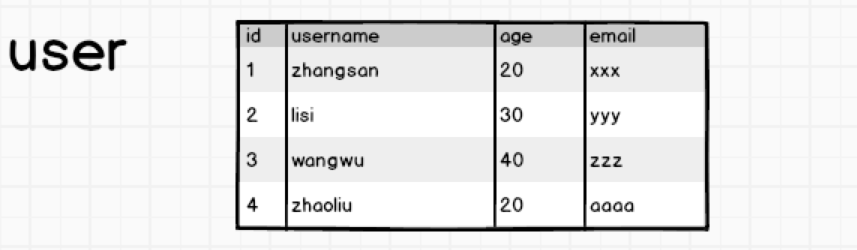
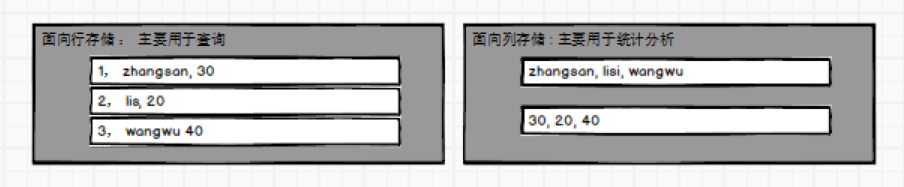
有这么一张用户表,假如我要根据id=1查询出来这条数据对应的用户姓名,很简单,会给我们返回zhangsan。但是,当我们查的时候,想一下,查名字的时候age和email会不会被查出来?答案是肯定的,Mysql的数据存储是以行为单位的,面向行存储。那问题就出现了,我只需要找出zhangsan的名字,却需要查询一整行的数据,如果列非常多,那么查询效率可想而知了。
查询的操作速度会受到以下两个因素的制约:
- 表被并发的插入、编辑以及删除操作。
- 查询语句通常不是简单的对一个表进行操作,有可能是多个表关联后的复杂查询,甚至有可能是group by或者order by操作,此时,性能下降很明显。
如果一张表的列过多,会影响查询效率,我们称这样表为宽表。怎么优化呢,拆开来,竖直拆分:
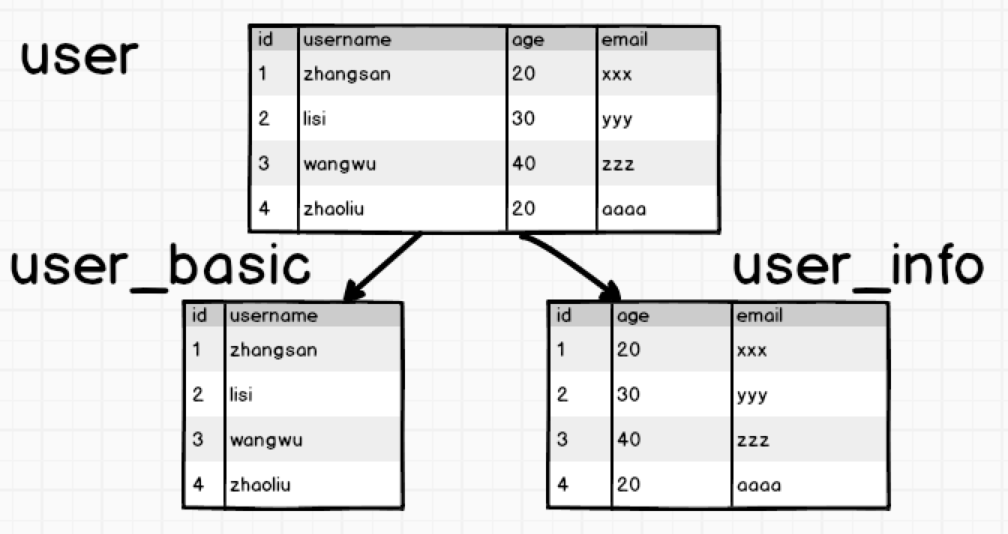
这样的情况下,我们要查找username的时候只需要查找user_basic表,没有多余的字段,查询效率就会很快。
如果一张表的行过多,会影响查询效率,我们将这样的表称之为高表,可以采用水平拆表的方式提高效率:
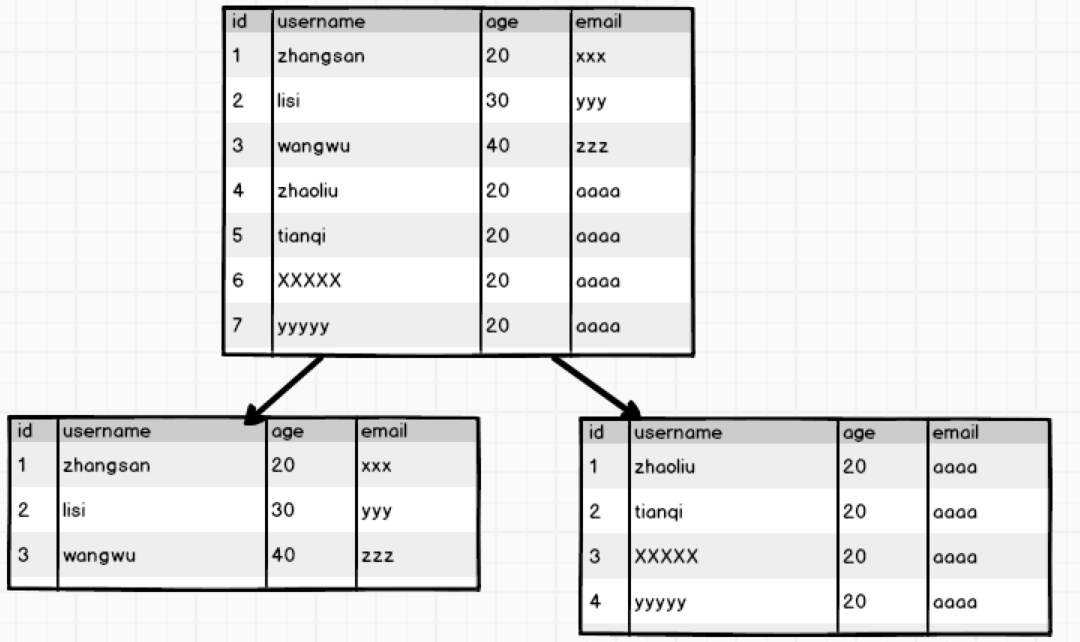
这种水平拆分应用比较多的 场景就是日志表,日志信息每天产生很多,可以按月进行水平拆分,这样就实现了高表变矮。
ok,这种拆分方式貌似可以解决宽表和高表的问题,但是如果有一天公司的业务变了,比如原来没有微信,现在有了微信,需要加入用户的微信字段。这时候需要改变表的结构信息,该怎么办?最简单的想法是多加一列,像这样:
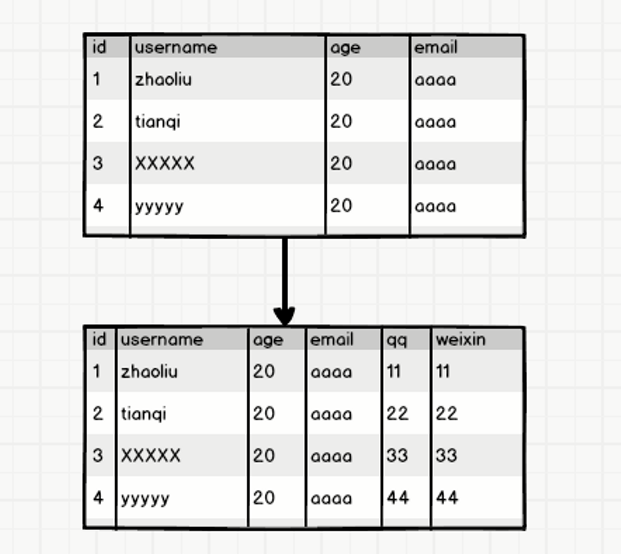
多考虑一下就知道这样做很不妥帖,比如说有些早期用户没有微信,这一列是设置默认值还是采取其他的做法就得权衡一下。如果需要扩展很多的列出来,而且不是所有的用户都有这些属性,那么拓展起来就更加复杂了。
这时候,想到了JSON格式的字符串,这是一种以字符串的形式表示的对象,而且属性字段可以动态拓展,于是有了下边这种做法,两种做法加以对比:
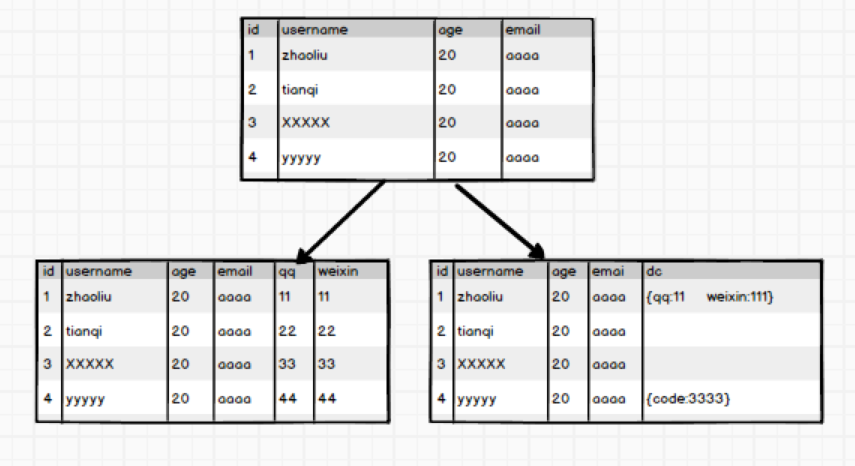
ok,这样存储数据它不挺好的嘛,HBase出来干嘛??Mysql有一点,数据达到一定的阈值,无论怎么优化,它都无法达到高性能的发挥。而大数据领域的数据,动辄PB级,这种存储应用明显是不能很好的满足需求的。针对上边的问题,HBase都有很好的解决方案~~
3、How:HBase怎么实现的?
先不说为什么用,接着上边说到的几个问题:高表宽表,数据列动态扩展,把提到的几个解决办法:水平垂直切分,列扩展方法,杂糅在一起。
有这么一张表,怕它又宽又高,又会动态扩展列,那么在设计之初,就把这个表给他拆开,为了列的动态拓展,直接存储JSON格式:
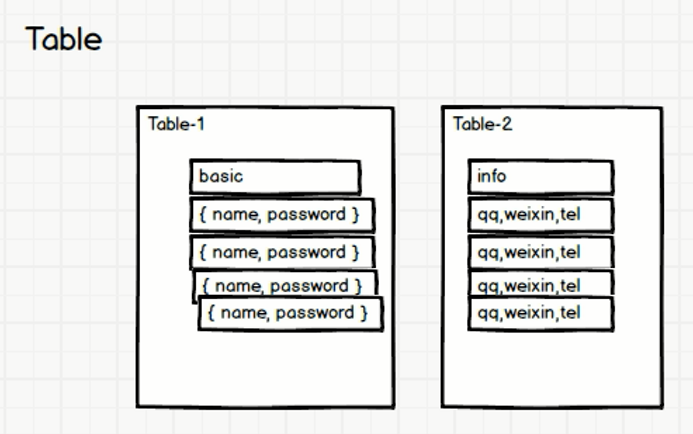
这样就解决了宽表问题,高表怎么办呢?
一个表的两部分,各存一部分行:

解决了高表,宽表,动态扩展列的问题~~完美plus~
如果还要进一步提高性能怎么办?Mysql->Redis !!! 缓存啊!
查询出来的数据放入到缓存中,下一次查询直接从缓存中拿数据。插入数据怎么办呢?也可以这样理解,我把要插入的数据放进缓存中,再也不用管了,直接由数据库从缓存拿数据插入到数据库。此时程序不需要等待数据插入成功,提高了并行工作的效率。
可是这样做有了很大的风险,服务器宕机的话,缓存中的数据没来得及插入到数据库中,那不就丢数据了嘛。参考Redis的持久化策略,可以给插入数据这个操作添加一个操作日志,用于持久化插入操作,宕机重启后从日志恢复。
这样设计架构就变成了这个样子:
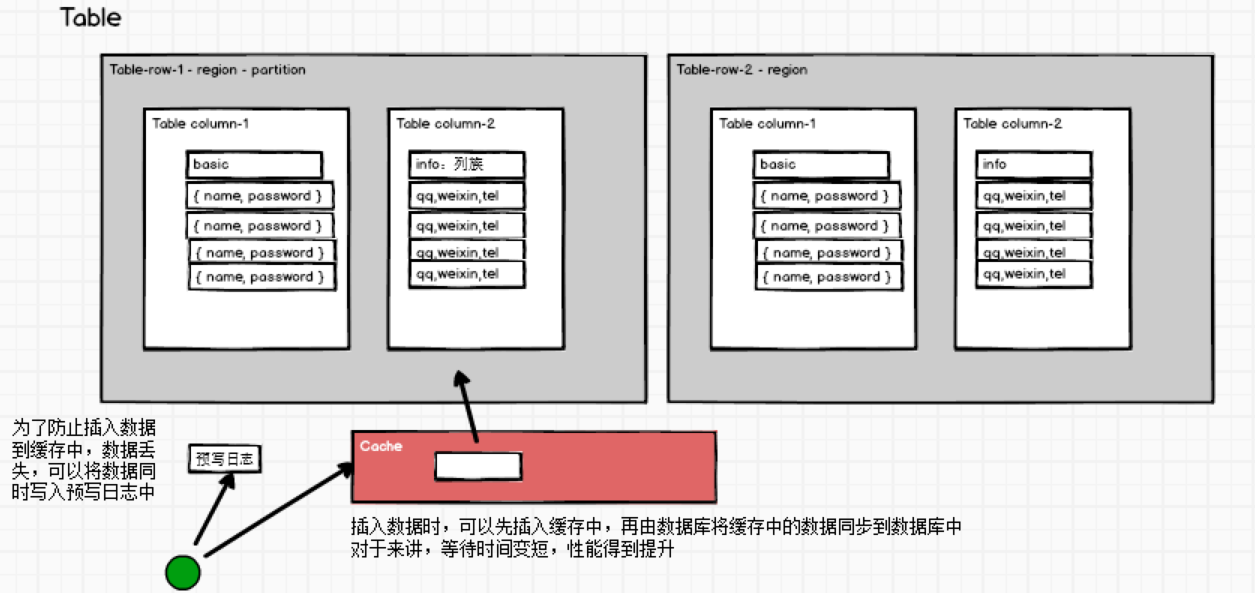
上边这种解决方式,实际上就是HBase实现的大致思路,详细的内容会在后边慢慢说。
简单粗暴总结:HBase就是一个面向列存储的非关系型数据库。两者的区别主要是:
HBase是的存储时基于HDFS的,HDFS有着高容错性的特点,被设计用来部署在低廉的硬件上,而且它提供高吞吐量以访问应用程序的数据,时候那些有着超大数据集的应用程序。基于Hadoop意味着HBase与生俱来的超强的扩展性和吞吐量。
HBase采用的时key/value的存储方式,这意味着,及时随着数据量的增大,也几乎不会导致查询性能的下降。HBase又是一个面向列存储的数据库,当表的字段很多时,可以把其中几个字段独立出来放在一部分机器上,而另外几个字段放到另一部分机器上,充分分散了负载的压力。如此复杂的存储结构和分布式的存储方式,带来的代价就是:即便是存储很少的数据,也不会很快。
HBase并不是足够快,而是数据量很大的时候它慢的不明显。
什么时候使用HBase呢,主要是以下两种情况:
- 单表数据量超过千万,而且并发量很大;
- 数据分析需求较弱,或者不需要那么实时灵活。
参考资料:
[1] 李海波. 大数据技术之HBase
[2] 杨曦. HBase不睡觉书
HBase学习笔记(一)——基础入门的更多相关文章
- 《马哥出品高薪linux运维教程》wingkeung学习笔记-linux基础入门课程
计算机原理概念: 1.CPU和内存中的存储单元通信线路称为总线(BUS),总线是被指令和数据复用的,所以也称为前端总线. 2.计算机中计算频率的时间标准即晶体振荡器原理,精确计算时间长度,根据相同的时 ...
- Vue学习笔记-Vue基础入门
此篇文章是本人在学习Vue是做的部分笔记的一个整理,内容不是很全面,希望能对阅读文章的同学有点帮助. 什么是Vue? Vue.js (读音 /vjuː/,类似于 view) 是一套构建用户界面的渐进式 ...
- 006 SpringCloud 学习笔记2-----SpringCloud基础入门
1.SpringCloud概述 微服务是一种架构方式,最终肯定需要技术架构去实施. 微服务的实现方式很多,但是最火的莫过于Spring Cloud了.SpringCloud优点: - 后台硬:作为Sp ...
- java 从零开始,学习笔记之基础入门<Oracle_基础>(三十三)
Oracle 数据库基本知识 [训练1] 显示DEPT表的指定字段的查询. 输入并执行查询: SELECTdeptno,dname FROM ...
- java 从零开始,学习笔记之基础入门<集合>(十六)
集合 集合:将多个元素放入到一个集合对象中去,对应的集合对象就可以用来存储多元素. Collection接口的子接口:Set接口和List接口. Map不是Collection接口的子接口. Coll ...
- 学习《零基础入门学习Python》电子书PDF+笔记+课后题及答案
初学python入门建议学习<零基础入门学习Python>.适合新手入门,很简单很易懂.前一半将语法,后一半讲了实际的应用. Python3入门必备,小甲鱼手把手教授Python,包含电子 ...
- tensorflow学习笔记二:入门基础 好教程 可用
http://www.cnblogs.com/denny402/p/5852083.html tensorflow学习笔记二:入门基础 TensorFlow用张量这种数据结构来表示所有的数据.用一 ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- mybatis学习笔记之基础复习(3)
mybatis学习笔记之基础复习(3) mybatis是什么? mybatis是一个持久层框架,mybatis是一个不完全的ORM框架.sql语句需要程序员自己编写, 但是mybatis也是有映射(输 ...
- mybatis学习笔记之基础框架(2)
mybatis学习笔记之基础框架(2) mybatis是一个持久层的框架,是apache下的顶级项目. mybatis让程序将主要精力放在sql上,通过mybatis提供的映射方式,自由灵活生成满足s ...
随机推荐
- iptables 删除规则
iptables -nL --line-number显示每条规则链的编号 iptables -D FORWARD 2删除FORWARD链的第2条规则,编号由上一条得知.如果删除的是nat表中的链,记得 ...
- Helm V3 新版本发布
Helm v3.0.0 Alpha 1 is coming! Helm 作为 Kubernetes 体系的包管理工具,已经逐渐成为了事实上的应用分发标准.根据 2018 年 CNCF 的一项云原生用户 ...
- 如何编程实现快速获取一个整型数中的bit流中1的个数
int one_in_unsigned(unsigned n) { n =(n & ) & 0x55555555); n =(n & ) & 0x33333333); ...
- kuangbin专题-连通图A - Network of Schools
这道题的意思是就是 问题 1:初始至少需要向多少个学校发放软件,使得网络内所有的学校最终都能得到软件. 2:至少需要添加几条传输线路(边),使任意向一个学校发放软件后,经过若干次传送,网络内所有的学校 ...
- js实现圆形的碰撞检测
文章地址:https://www.cnblogs.com/sandraryan/ 碰撞检测这个东西写小游戏挺有用der~~~ 注释写的还挺全,所以就不多说了,看注释 这是页面结构.wrap存放生成的小 ...
- ACM学习网站、
转载:http://www.cnblogs.com/zhourongqing/archive/2012/05/24/2516180.html http://61.187.179.132/JudgeOn ...
- 洛谷P5022 旅行 题解 去环/搜索
题目链接:https://www.luogu.org/problem/P5022 这道题目一开始看的时候没有思路,但是看到数据范围里面有一个: \(m = n-1\) 或 \(m = n\) ,一下子 ...
- iptables单个规则实例
iptables -F? # -F 是清除的意思,作用就是把 FILTRE TABLE 的所有链的规则都清空 iptables -A INPUT -s 172.20.20.1/32 -m state ...
- codeforces 1214
D 比赛的时候居然看漏了条件... 若在(x, y)格子,那么只能移动到(x+1, y)或(x, y+1) 这样的话就好做了,直接dp,然后统计每一种路径长度经过的点数. #include<cs ...
- SELinux: Could not downgrade policy file
在配置nfs服务器,设定selinux时,碰到了SELinux: Could not downgrade policy file的错误提示,下文是其解决方案. 一.故障现象 [root@system1 ...