ACM北大暑期课培训第五天
今天讲的扫描线,树状数组,并查集还有前缀树。
扫描线
扫描线的思路:使用一条垂直于X轴的直线,从左到右来扫描这个图形,明显,只有在碰到矩形的左边界或者右边界的时候,这个线段所扫描到的情况才会改变,所以把所有矩形的入边,出边按X值排序。然后根据X值从小到大去处理,就可以用线段树来维护扫描到的情况。
如果碰到矩形的入边,就把这条边加入,如果碰到出边,就拿走。
用根结点记录被覆盖的总长度 更新
插入数据的顺序:
将矩形的纵边从左到右排序,然后依次将这些纵边插入线段树。要记住哪些纵边是一个 矩形的左边(开始边),哪些纵边是一个矩形 的右边(结束边),以便插入时,对Len(当前,本区间上有多长的 部分是落在那些矩形中的)和 Covers(本区间当前被多少个矩形 完全包含)做不同的修改。 插入一条边后,就根据根节点的Len 值增加总 覆盖面积的值。 增量是Len * 本边到下一条边的距离。 一开始,所有区间 Len = 0 Covers = 0
扫描线和线段树推荐一个博客:https://www.cnblogs.com/AC-King/p/7789013.html
例题:POJ 1151 Atlantis
#include <iostream>
#include <algorithm>
#include <math.h>
#include <set>
using namespace std;
double y[];
struct CNode
{
int L,R;
CNode * pLeft, * pRight;
double Len; //当前,本区间上有多长的部分是落在那些矩形中的
int Covers;//本区间当前被多少个矩形完全包含
};
CNode Tree[];
struct CLine
{
double x,y1,y2;
bool bLeft; //是否是矩形的左边
} lines[];
int nNodeCount = ;
bool operator< ( const CLine & l1,const CLine & l2)
{
return l1.x < l2.x;
}
template <class F,class T>
F bin_search(F s, F e, T val)
{
//在区间[s,e)中查找 val,找不到就返回 e
F L = s;
F R = e-;
while(L <= R )
{
F mid = L + (R-L)/;
if( !( * mid < val || val < * mid ))
return mid;
else if(val < * mid)
R = mid - ;
else
L = mid + ;
}
return e;
}
int Mid(CNode * pRoot)
{
return (pRoot->L + pRoot->R ) >>;
}
void Insert(CNode * pRoot,int L, int R)
//在区间pRoot 插入矩形左边的一部分或全部,该左边的一部分或全部覆盖了区间[L,R]
{
if( pRoot->L == L && pRoot->R == R)
{
pRoot->Len = y[R+] - y[L];
pRoot->Covers ++;
return;
}
if( R <= Mid(pRoot))
Insert(pRoot->pLeft,L,R);
else if( L >= Mid(pRoot)+)
Insert(pRoot->pRight,L,R);
else
{
Insert(pRoot->pLeft,L,Mid(pRoot));
Insert(pRoot->pRight,Mid(pRoot)+,R);
}
if( pRoot->Covers == ) //如果不为0,则说明本区间当前仍然被某个矩形完全包含,则不能更新 Len
pRoot->Len = pRoot->pLeft ->Len + pRoot->pRight ->Len;
}
void Delete(CNode * pRoot,int L, int R)
{
//在区间pRoot 删除矩形右边的一部分或全部,该矩形右边的一部分或全部覆盖了区间[L,R]
if( pRoot->L == L && pRoot->R == R)
{
pRoot->Covers --;
if( pRoot->Covers == )
if( pRoot->L == pRoot->R )
pRoot->Len = ;
else
pRoot->Len = pRoot->pLeft ->Len + pRoot->pRight ->Len;
return ;
}
if( R <= Mid(pRoot))
Delete(pRoot->pLeft,L,R);
else if( L >= Mid(pRoot)+)
Delete(pRoot->pRight,L,R);
else
{
Delete(pRoot->pLeft,L,Mid(pRoot));
Delete(pRoot->pRight,Mid(pRoot)+,R);
}
if( pRoot->Covers == ) //如果不为0,则说明本区间当前仍然被某个矩形完全包含,则不能更新 Len
pRoot->Len = pRoot->pLeft ->Len + pRoot->pRight ->Len;
}
void BuildTree( CNode * pRoot, int L,int R)
{
pRoot->L = L;
pRoot->R = R;
pRoot->Covers = ;
pRoot->Len = ;
if( L == R)
return;
nNodeCount ++;
pRoot->pLeft = Tree + nNodeCount;
nNodeCount ++;
pRoot->pRight = Tree + nNodeCount;
BuildTree( pRoot->pLeft,L,(L+R)/);
BuildTree( pRoot->pRight,(L+R)/+,R);
}
int main()
{
int n;
int i,j,k;
double x1,y1,x2,y2;
int yc,lc;
int nCount = ;
int t = ;
while(true)
{
scanf("%d",&n);
if( n == ) break;
t ++;
yc = lc = ;
for( i = ; i < n; i ++ )
{
scanf("%lf%lf%lf%lf", &x1, &y1,&x2,&y2);
y[yc++] = y1;
y[yc++] = y2;
lines[lc].x = x1;
lines[lc].y1 = y1;
lines[lc].y2 = y2;
lines[lc].bLeft = true;
lc ++;
lines[lc].x = x2;
lines[lc].y1 = y1;
lines[lc].y2 = y2;
lines[lc].bLeft = false;
lc ++;
}
sort(y,y + yc);
yc = unique(y,y+yc) - y;
nNodeCount = ;
//yc 是横线的条数,yc- 1是纵向区间的个数,这些区间从0
//开始编号,那么最后一个区间
//编号就是yc - 1 -1
BuildTree(Tree, , yc - - );
sort(lines,lines + lc);
double Area = ;
for( i = ; i < lc - ; i ++ )
{
int L = bin_search( y,y+yc,lines[i].y1) - y;
int R = bin_search( y,y+yc,lines[i].y2) - y;
if( lines[i].bLeft )
Insert(Tree,L,R-);
else
Delete(Tree,L,R-);
Area += Tree[].Len * (lines[i+].x - lines[i].x);
}
printf("Test case #%d\n",t);
printf("Total explored area: %.2lf\n",Area);
printf("\n",Area);
}
return ;
}
老师上课讲的代码
树状数组
只能解决单点更新、区间求和问题。
可以快速求出任意区间和。
能力比线段树弱。 它能解决的问题线段树都能解决,是线段树能解决的问题的子集。
它的好处: 1.写起来简单 2.效率高(常数小) ps:线段树常数大 两者区间查询的时间复杂度都是O(logn)
三个重要的函数 :
int lowerbit(int x)
{
return x&-x;
} void Update(int i,int v) // 初始化与单点修改
{
while(i <= n)
{
c[i] += v ;
i += lowbit(i) ;
}
} int Sum(int i) // 区间求和
{
int res = ;
while(i)
{
res += c[i] ;
i -= lowbit(i) ;
}
return res ;
}
lowbit(x): 只保留x的二进制最右边的1,其余位都变为0后的值
对于序列a,我们设一个数组C C[i] = a[i – 2 k + 1] + … + a[i] C即为a的树状数组
k为i在二进制下末尾0的个数 2k就是i 保留最右边的1,其余位全变0
i从1开始算!
C[i] = a[i-lowbit(i)+1] + …+ a[i] C包含哪些项看上去没有规律
C1=A1
C2=A1+A2
C3=A3
C4=A1+A2+A3+A4
C5=A5
C6=A5+A6
C7=A7
C8=A1+A2+A3+A4+A5+A6+A7+A8
…………
C16=A1+A2+A3+A4+A5+A6+A7+A8+A9+A10+ A11+A12+A13+A14+A15+A16
树状数组图示
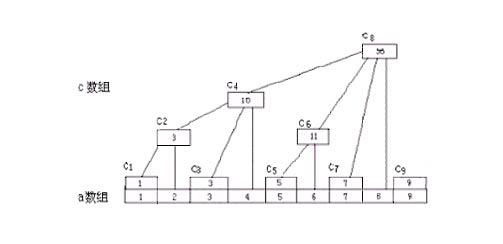
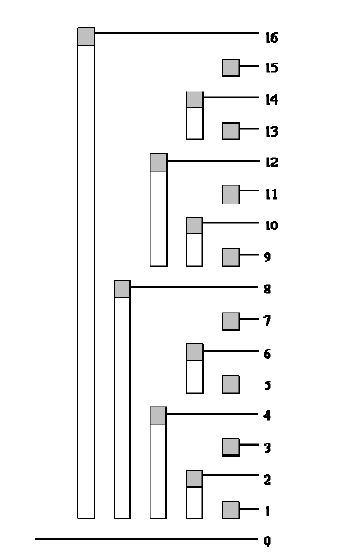
将C[]数组的结点序号转化为二进制
时间复杂度:建数组: O(n) 更新: O(logn) 局部求和:O(logn)
树状数组推荐博客:https://www.cnblogs.com/ECJTUACM-873284962/p/6380245.html
POJ题目推荐: 2182, 2352, 1177, 3667,3067
并查集
3个操作:
1.合并两个集合
2.查询一个元素在哪个集合
3.查询两个元素是否属于同一集合
核心:查一个元素的树根(时间复杂度为常数)
实际应用代码:
int par[];
int GET_ROOT(int a)//查询一个元素在哪个集合 路径压缩
{
if (par[a]!=a)
par[a] = GET_ROOT(par[a]);
return par[a];
}
int query(int a,int b)//查询两个元素是否属于同一集合
{
return GET_ROOT(a)==GET_ROOT(b);
}
void merge(int a,int b)//合并两个集合
{
par[GET_ROOT(a)] = GET_ROOT(b);
}
有时候需要添加数组记录,例如添加sum数组记录每个集合有多少元素。
在合并时进行维护
做题时主要理清怎样算同一集合。
例题:1.POJ 1611 The Suspects
2.POJ 1988 Cube Stacking
3.POJ 1182 食物链
DFA(一部分)
多模式匹配
trie图是一种DFA,可以由trie树为基础构造出来, 对于插入的每个模式串,其插入过程中使用的最后一 个节点都作为DFA的一个终止节点。 如果要求一个母串包含哪些模式串,以用母串作为 DFA的输入,在DFA 上行走,走到终止节点,就意 味着匹配了相应的模式串(没能走到终止节点,并不 意味着一定不包含模式串)。
避免母串指针回溯 --> 记住哪些模式串的哪个前缀已经被匹配 -->前缀指针
前缀指针:仿照KMP算法的Next数组, 我们也对树上的每一个节点 建立一个前缀指针。这个前 缀指针的定义和KMP算法中 的next数组相类似,从根节 点沿边到节点p我们可以得 到一个字符串S,节点p的前 缀指针定义为:指向树中出 现过的S的最长的后缀(不能等于S)。
ACM北大暑期课培训第五天的更多相关文章
- ACM北大暑期课培训第一天
今天是ACM北大暑期课开课的第一天,很幸运能参加这次暑期课,接下来的几天我将会每天写博客来总结我每天所学的内容.好吧下面开始进入正题: 今天第一节课,郭炜老师给我们讲了二分分治贪心和动态规划. 1.二 ...
- ACM北大暑期课培训第七天
昨天没时间写,今天补下. 昨天学的强连通分支,桥和割点,基本的网络流算法以及Dinic算法: 强连通分支 定义:在有向图G中,如果任意两个不同的顶点 相互可达,则称该有向图是强连通的. 有向图G的极大 ...
- ACM北大暑期课培训第六天
今天讲了DFA,最小生成树以及最短路 DFA(接着昨天讲) 如何高效的构造前缀指针: 步骤为:根据深度一一求出每一个节点的前缀指针.对于当前节点,设他的父节点与他的边上的字符为Ch,如果他的父节点的前 ...
- ACM北大暑期课培训第二天
今天继续讲的动态规划 ... 补充几个要点: 1. 善于利用滚动数组(可减少内存,用法与计算方向有关) 2.升维 3.可利用一些数据结构等方法使代码更优 (比如优先队列) 4.一般看到数值小的 (十 ...
- ACM北大暑期课培训第八天
今天学了有流量下界的网络最大流,最小费用最大流,计算几何. 有流量下界的网络最大流 如果流网络中每条边e对应两个数字B(e)和C(e), 分别表示该边上的流量至少要是B(e),最多 C(e),那么,在 ...
- ACM北大暑期课培训第四天
今天讲了几个高级搜索算法:A* ,迭代加深,Alpha-Beta剪枝 以及线段树 A*算法 启发式搜索算法(A算法) : 在BFS算法中,若对每个状态n都设定估价函数 f(n)=g(n)+h(n) ...
- ACM北大暑期课培训第三天
今天讲的内容是深搜和广搜 深搜(DFS) 从起点出发,走过的点要做标记,发现有没走过的点,就随意挑一个往前走,走不 了就回退,此种路径搜索策略就称为“深度优先搜索”,简称“深搜”. bool Dfs( ...
- 牛客网暑期ACM多校训练营(第五场):F - take
链接:牛客网暑期ACM多校训练营(第五场):F - take 题意: Kanade有n个盒子,第i个盒子有p [i]概率有一个d [i]大小的钻石. 起初,Kanade有一颗0号钻石.她将从第1到第n ...
- 2019暑期北航培训—预培训作业-IDE的安装与初步使用(Visual Studio版)
这个作业属于那个课程 2019北航软件工程暑期师资培训 这个作业要求在哪里 预培训-IDE的安装与初步使用(Visual Studio版) 我在这个课程的目标是 提高自身实际项目实践能力,掌握帮助学生 ...
随机推荐
- U盘还原系统
相信现在不少的人已经开始使用U盘作为启动盘来安装系统,说起来这可比用光盘装系统可是方便多了.毕竟U盘可以随身携带,至于光盘嘛,就不多说了. 可是还有许多人对U盘安装系统还是有些陌生的感觉. ...
- Python--day72--Cookie和Session内容回顾
1. Cookie是什么 保存在浏览器端的键值对 为什么要有Cookie? 因为HTTP请求是无状态的 Cookie的原理? 服务端可以在返回响应的时候 做手脚 在浏览器上写入键值对(Cookie) ...
- JS中数组声明
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Linux 查看iptables状态-重启
iptables 所在目录 : /etc/sysconfig/iptables # service iptables status #查看iptables状态 # service iptables r ...
- H3C 多区域OSPF配置示例
- 如何查看 Python 全部内置变量和内置函数?
https://jingyan.baidu.com/article/7082dc1c071649e40a89bdb8.html Python 解释器内置了一些常量和函数,叫做内置常量(Built-in ...
- @ENABLEWEBSECURITY和@ENABLEWEBMVCSECURITY有什么区别?
@EnableWebSecurity和@EnableWebMvcSecurity有什么区别? @EnableWebSecurity JavaDoc文档: 将此注释添加到@Configuration类中 ...
- 【js】vue 2.5.1 源码学习 (九) 响应数组对象的变
大体思路(八) 本节内容: 1.Observe 如何响应数组的变化 代理原型 数组变异方法 shell cacheArrProto methods 新添加的数组需要加到显示系统里面,拦截 push等的 ...
- 2019-11-20-Github-给仓库上传-NuGet-库
title author date CreateTime categories Github 给仓库上传 NuGet 库 lindexi 2019-11-20 08:18:14 +0800 2019- ...
- linux测试 scullpipe 驱动
我们已经见到了 scullpipe 驱动如何实现阻塞 I/O. 如果你想试一试, 这个驱动的源码 可在剩下的本书例子中找到. 阻塞 I/O 的动作可通过打开 2 个窗口见到. 第一个可运行 一个命令诸 ...