第二十六篇 玩转数据结构——二分搜索树(Binary Search Tree)
- 跟链表一样,二叉树也是一种动态数据结构,即,不需要在创建时指定大小。
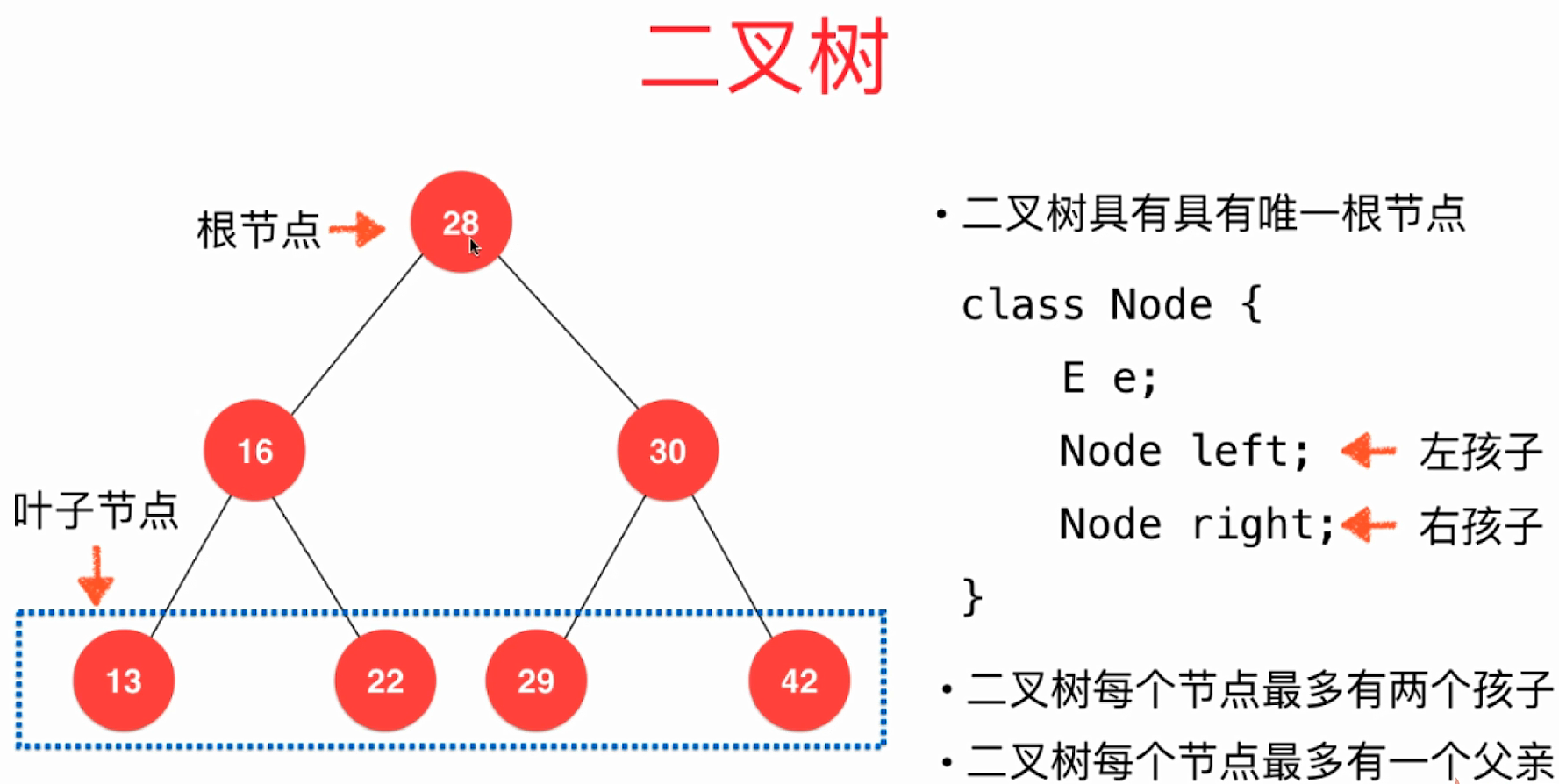
- 跟链表不同的是,二叉树中的每个节点,除了要存放元素e,它还有两个指向其它节点的引用,分别用Node left和Node right来表示。
- 类似的,如果每个节点中有3个指向其它节点的引用,就称其为"三叉树"...
- 二叉树具有唯一的根节点。
- 二叉树中每个节点最多指向其它的两个节点,我们称这两个节点为"左孩子"和"右孩子",即每个节点最多有两个孩子。
- 一个孩子都没有的节点,称之为"叶子节点"。
- 二叉树的每个节点,最多只能有一个父亲节点,没有父亲节点的节点就是"根节点"。
- 二叉树的形象化描述如下图:
- 二叉树具有天然的递归结构。
- 每个节点的"左子树"也是一棵二叉树,每个节点的"右子树"也是一棵二叉树。
- 二叉树不一定是"满的",即,某些节点可能只有一个子节点;更极端一点,整棵二叉树可以仅有一个节点;在极端一点,整棵二叉树可以一个节点都没有;

- 二分搜索树的构造函数、getSize方法、isEmpty方法及add方法的实现逻辑如下:
public class BST<E extends Comparable> { private class Node {
public E e;
public Node left, right; // 构造函数
public Node(E e) {
this.e = e;
left = null;
right = null;
}
} private Node root;
private int size; // 记录二分搜索树中存储的元素个数 public BST() {
root = null;
size = 0;
} // 实现size方法
public int size() {
return size;
} // 实现isEmpty方法
public boolean isEmpty() {
return size == 0;
} // 实现add方法
public void add(E e) {
root = add(root, e);
} // 向以node为根的二分搜索树中插入元素e,递归算法
// 返回插入新节点后二分搜索树的根
private Node add(Node node, E e) { if (node == null) {
size++;
return new Node(e);
} if (e.compareTo(node.e) < 0) {
node.left = add(node.left, e);
} else if (e.compareTo(node.e) > 0) {
node.right = add(node.right, e);
}
return node;
}
}- 二分搜索树的contains方法实现逻辑如下:
// 实现contains方法,判断二分搜索树中是否包含元素e
public boolean contains(E e) {
return contains(root, e);
} // 判断以node为根的二分搜索树中是否包含元素e
private boolean contains(Node node, E e) {
if (node == null) {
return false;
}
if (e.compareTo(node.e) == 0) {
return true;
} else if (e.compareTo(node.e) < 0) {
return contains(node.left, e);
} else {
return contains(node.right, e);
}
}
- 二分搜索树的遍历操作,遍历操作就是把所有节点都访问一遍
- 前序遍历的业务逻辑如下:
//二分搜索树的前序遍历
public void preOder() {
preOrder(root);
} private void preOrder(Node node) { if (node == null) {
return;
} System.out.print(node.e);
preOrder(node.left);
preOrder(node.right);
}- 中序遍历的业务逻辑如下:
// 二分搜索树的中序遍历
public void inOrder() {
inOrder(root);
} // 中序遍历以node为根的二分搜索树,递归算法
private void inOrder(Node node) { if (node == null) {
return;
} inOrder(node.left);
System.out.print(node.e);
inOrder(node.right); }- 后序遍历的业务逻辑如下:
// 二分搜索树的后序遍历
public void postOrder() {
postOrder(root);
} // 后序遍历以node为根的二分搜索树,递归算法
private void postOrder(Node node) { if (node == null) {
return;
}
postOrder(node.left);
postOrder(node.right);
System.out.print(node.e); }- 简单测试如下:
public class Main { public static void main(String[] args) {
BST<Integer> bst = new BST<>();
int[] nums = {5, 3, 6, 8, 4, 2};
for (int num : nums) {
// 测试add方法
bst.add(num);
}
// 测试前序遍历
bst.preOrder();
System.out.println();
// 测试中序遍历
bst.inOrder();
System.out.println();
// 测试后序遍历
bst.postOrder(); }
}- 输出结果:
532468
234568
243865- 前序遍历是最自然的遍历方式,也是最常用的遍历方式;中序遍历的结果是按从小到大的顺序的排列的;后序遍历可以用于为二分搜索树释放内存。
- 利用"栈"实现二分搜索树的非递归前序遍历
// 二分搜索树的非递归前序遍历
public void preOrderNR() {
Stack<Node> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
Node cur = stack.pop();
System.out.print(cur.e);
if (cur.right != null) {
stack.push(cur.right);
}
if (cur.left != null) {
stack.push(cur.left);
}
}
}
- 二分搜索树的非递归实现比递归实现更加复杂。
- 二分搜索树的前序、中序和后续遍历都属于"深度优先"算法。
- 二分搜索树的"层序遍历"属于"广度优先"算法。
- 利用"队列"实现二分搜索树的"层序遍历"
// 二分搜索树的层序遍历
public void levelOrder() {
Queue<Node> q = new LinkedList<>();
q.add(root);
while (!q.isEmpty()) {
Node cur = q.remove();
System.out.print(cur.e);
if (cur.left != null) {
q.add(cur.left);
}
if (cur.right != null) {
q.add(cur.right);
}
}
}- 获取二分搜索树中的最小元素和最大元素
// 寻找二分搜索树中的最小元素
public E minimum() { if (size == 0) {
throw new IllegalArgumentException("BST is empty.");
}
return minimum(root).e; } // 返回以node为根的二分搜索树的最小元素所在节点
private Node minimum(Node node) {
if (node.left == null) {
return node;
}
return minimum(node.left);
} // 寻找二分搜索树中的最大元素
public E maximum() { if (size == 0) {
throw new IllegalArgumentException("BST is empty.");
}
return maximum(root).e; } // 返回以node为根的二分搜索树的最大元素所在节点
private Node maximum(Node node) {
if (node.right == null) {
return node;
}
return maximum(node.right);
}- 删除二分搜索树中最小元素和最大元素所在节点
// 从二分搜索树中删除最小元素所在节点,返回最小元素
public E removeMin() {
E ret = minimum();
root = removeMin(root);
return ret;
} // 删除掉以node为根的二分搜索树中的最小元素所在节点
// 返回删除节点后新的二分搜索树的根
private Node removeMin(Node node) {
if (node.left == null) {
Node rightNode = node.right;
node.right = null;
size--;
return rightNode;
}
node.left = removeMin(node.left);
return node;
} // 从二分搜索树中删除最大元素所在节点,返回最小元素
public E removeMax() {
E ret = maximum();
root = removeMax(root);
return ret;
} // 删除掉以node为根的二分搜索树中的最小元素所在节点
// 返回删除节点后新的二分搜索树的根
private Node removeMax(Node node) {
if (node.right == null) {
Node leftNode = node.left;
node.left = null;
size--;
return leftNode;
}
node.right = removeMax(node.right);
return node;
}- 删除二分搜索树中指定元素所对应的节点
// 从二分搜索树中删除元素为e的节点
public void remove(E e) {
remove(root, e);
} // 删除以node为根节点的二分搜索树中元素为e的节点,递归算法
// 返回删除节点后新的二分搜索树的根
private Node remove(Node node, E e) {
if (node == null) {
return null;
} if (e.compareTo(node.e) < 0) {
node.left = remove(node.left, e);
return node;
} else if (e.compareTo(node.e) > 0) {
node.right = remove(node.right, e);
return node;
} else {
// 待删除节点左子树为空的情况
if (node.left == null) {
Node rightNode = node.right;
node.right = null;
size--;
return rightNode;
// 待删除节点右子树为空的情况
} else if (node.right == null) {
Node leftNode = node.left;
node.left = null;
size--;
return leftNode;
// 待删除节点左右子树均不为空
// 找到比待删除节点大的最小节点,即待删除节点右子树的最小节点
// 用这个节点顶替待删除节点
} else {
Node successor = minimum(node.right);
successor.right = removeMin(node.right); //这里进行了size--操作
successor.left = node.left;
node.left = null;
node.right = null;
return successor;
}
}
}
第二十六篇 玩转数据结构——二分搜索树(Binary Search Tree)的更多相关文章
- 第二十九篇 玩转数据结构——线段树(Segment Tree)
1.. 线段树引入 线段树也称为区间树 为什么要使用线段树:对于某些问题,我们只关心区间(线段) 经典的线段树问题:区间染色,有一面长度为n的墙,每次选择一段墙进行染色(染色允许覆盖),问 ...
- 第三十二篇 玩转数据结构——AVL树(AVL Tree)
1.. 平衡二叉树 平衡二叉树要求,对于任意一个节点,左子树和右子树的高度差不能超过1. 平衡二叉树的高度和节点数量之间的关系也是O(logn) 为二叉树标注节点高度并计算平衡因子 AVL ...
- 第二十八篇 玩转数据结构——堆(Heap)和有优先队列(Priority Queue)
1.. 优先队列(Priority Queue) 优先队列与普通队列的区别:普通队列遵循先进先出的原则:优先队列的出队顺序与入队顺序无关,与优先级相关. 优先队列可以使用队列的接口,只是在 ...
- 第二十五篇 玩转数据结构——链表(Linked List)
1.. 链表的重要性 我们之前实现的动态数组.栈.队列,底层都是依托静态数组,靠resize来解决固定容量的问题,而"链表"则是一种真正的动态数据结构,不需要处理固定容 ...
- 第二十四篇 玩转数据结构——队列(Queue)
1.. 队列基础 队列也是一种线性结构: 相比数组,队列所对应的操作数是队列的子集: 队列只允许从一端(队尾)添加元素,从另一端(队首)取出元素: 队列的形象化描述如下图: 队列是一种先进 ...
- 数据结构 《5》----二叉搜索树 ( Binary Search Tree )
二叉树的一个重要应用就是查找. 二叉搜索树 满足如下的性质: 左子树的关键字 < 节点的关键字 < 右子树的关键字 1. Find(x) 有了上述的性质后,我们就可以像二分查找那样查找给定 ...
- 数据结构 -- 二叉树(Binary Search Tree)
一.简介 在计算机科学中,二叉树是每个结点最多有两个子树的树结构.通常子树被称作“左子树”(left subtree)和“右子树”(right subtree).二叉树常被用于实现二叉查找树和二叉堆. ...
- 第二十六篇 jQuery 学习8 遍历-父亲兄弟子孙元素
jQuery 学习8 遍历-父亲兄弟子孙元素 jQuery遍历,可以理解为“移动”,使用“移动”还获取其他的元素. 什么意思呢?老师举一个例子: 班上30位同学,我是新来负责教这个班学生的老师 ...
- 第二十六篇:两个SOUI新控件 ---- SListView和SComboView(借用Andorid的设计)
SOUI原来实现的SListBoxEx的效率一直是我对SOUI不太满意的地方.包括后来网友实现的SListCtrlEx. 这类控件为每一个列表项创建一个SWindow来容纳数据,当数据量比较大(100 ...
随机推荐
- R语言函数化学习笔记3
R语言函数化学习笔记3 R语言常用的一些命令函数 1.getwd()查看当前R的工作目录 2.setwd()修改当前工作目录 3.str()可以输出指定对象的结构(类型,位置等),同理还有class( ...
- ZOJ1310-Robot (BFS)
The Robot Moving Institute is using a robot in their local store to transport different items. Of co ...
- 类的成员和属性_python
一.字段和方法分类 方法分类: 二.属性(将方法伪装成字段) 三种伪装方式:@property @perr.setter @perr.deleter 属性使用的场景:分页 三.公有成员和私有成员 私 ...
- [P3935] Calculating - 整除分块
容易发现题目要求的 \(f(x)\) 就是 \(x\) 的不同因子个数 现在考虑如何求 \(\sum_{i=1}^n f(i)\),可以考虑去算每个数作为因子出现了多少次,很容易发现是 \([n/i] ...
- MyBatis的手动映射与模糊查询
一.手动映射 当实体类属性与数据库字段名不同时,无法自动映射,导致查询出空值,这时候可以使用手动映射 在select节点添加resultMap属性与resultMap节点建立关系
- 条件锁Condition
"""设计场景:timo先说一句,亚索再说一句timo: timo队长正在待命yasuo: 面对疾风吧timo: timo整装待发yasuo: 哈杀gay "& ...
- vue学习指南:第十二篇(详细) - Vue的 路由 第二篇 ( 路由按需加载(懒加载))
各位朋友 因 最近工作繁忙,小编停更了一段时间,快过年了,小编祝愿 大家 事业有成 学业有成 快乐健康 2020开心过好每一天.从今天开始 我会抽时间把 Vue 的知识点补充完整,以及后期会带给大家更 ...
- Your wechat account may be LIMITED to log in WEB wechat, error info: <error><ret>1203</ret><message>为了你的帐号安全,此微信号不能登录网页微信。你可以使用Windows微信或Mac微信在电脑端登录。Windows微信下载地址:WeChat for PC
转载:https://zhuanlan.zhihu.com/p/76180564 微信网页版限制登录或禁止登录将影响一大批使用itchat等Web Api方案的微信机器人 网页版微信 API 被封了, ...
- DataPipeline王睿:业务异常实时自动化检测 — 基于人工智能的系统实战
大家好,先自我介绍一下,我是王睿.之前在Facebook/Instagram担任AI技术负责人,现在DataPipeline任Head of AI,负责研发企业级业务异常检测产品,旨在帮助企业一站式解 ...
- actiBPM插件的办法
1.下载actiBPM到本地 从IDEA官网下载actiBPM.jar包 IDEA官网:https://plugins.jetbrains.com/ 官网搜索actiBPM 2.从本地安装actiBP ...