kafka那些事儿
1 为什么用消息队列
1)解耦。服务之间没有强依赖,不需要关心调用服务时出现的各种异常,服务挂掉后接口超时等问题
2)异步。解决接口调用多服务时延时高的问题
3)高峰期服务间缓冲。解决工作节奏不一致问题,防止服务被打死
2 消息丢失了怎么办
消息丢失有3种情况:
1)consumer消费时如果在拉取到消息后没有处理完成或者发生异常,而且offset却自动提交了,会导致消息丢失;将kafka的offset提交改为手动同步方式是比较保险的,对于准确性较高的数据应该使用这中方式。
2)producer向leaderpartition发送消息的时候acks参数应设置为-1,这样leaderpartition存储完成后,等待followpartition也同步完成,才会给producer返回成功(吞吐量下降)。
3)kafka本身丢失数据的话,可以通过横向扩展broker,增加partition数量,增加partition副本数来保证某些节点宕机后集群中仍然有全量数据。
3 消息重复消费了怎么办
新增情况:
1)如果有新增消息重复消费的话,可以使用redis存储id值来忽略掉已经新增过的数据,在数据库端可以通过唯一主键保证不重复插入。
修改情况:
1)在消息在存入队列中的数据加入时间戳,如果发现消费到的数据在redis中已经存在并且时间戳相同,则直接忽略,认为是重复消费。
4 如何保证kafka消费的消息顺序
1)将带有相同key的数据路由到同一个partition中,在同一个partition中消息的顺序是一致的。
2)消费者端如果开启多个线程消费数据,需要路由到同一内存队列中保证顺序性,这样就不会出现消息不一致的问题了。
5 kafka controller选举算法(与partition leader选举算法类似)
leader算法是基于zk的节点注册监听机制实现的。一旦有人注册成功zk上的leader节点,那么这个partition就被选举为leader,如果这个leader机器挂掉那么就会zk上的节点就会被删除,那么其它的follow partition就会争抢向zk注册leader节点,一旦有注册成功就会被选择为leader,那么其它partition就会注册失败。
6 挂掉的broker重新上线以后。kafka的partition是怎样做rebalance的
新建topic的时候怎样划分partition到broker中?
为了能让partition和replica均匀的分布在broker上,防止一台机器负载较高。有如下分配算法:
将所有N Broker和待分配的i个Partition排序.
将第i个Partition分配到第(i mod n)个Broker上.
将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上
例如 5个broker 10分区 3副本
当所有topic的partition创建完成以后,在zk中每一个topic下的partition都会维护一个AR列表(assigned replicas所有副本)和ISR(In-Sync Replicas数据同步副本,在0.9以后的新版去掉了这个参数)列表;AR列表的第一个partition副本被称为preferred-replica。
当挂掉的partition节点重新上线以后,可以通过使用kafka-preferred-replica-election.sh工具来进行重新平衡partition,过程就是把AR列表的第一个partition重新指定为leader partition。
也可以通过配置auto.leader.rebalance.enable=true参数来进行设置。
PS:ISR解释为 “In-Sync Replicas”数据同步副本,在0.9以后的新版去掉了replica.lag.time.max.ms这个参数;所以如果在这个列表中只需满足,副本所在节点必须维持着与 zookeeper 的连接。
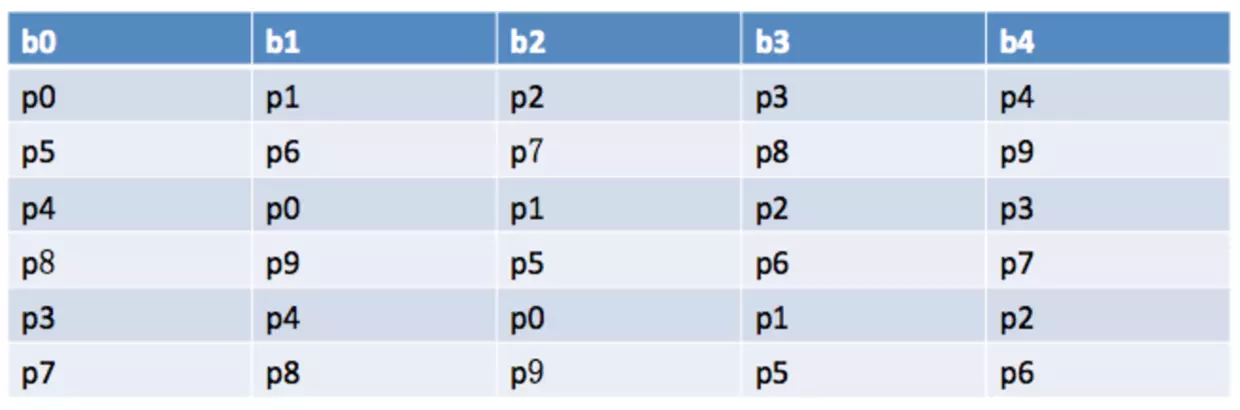
7 消息积压了怎么办?
几千万条数据在 MQ 里积压了七八个小时,从下午 4 点多,积压到了晚上 11 点多。这个是我们真实遇到过的一个场景,确实是线上故障了,这个时候要不然就是修复 consumer 的问题,让它恢复消费速度,然后傻傻的等待几个小时消费完毕。这个肯定不能在面试的时候说吧。
一个消费者一秒是 1000 条,一秒 3 个消费者是 3000 条,一分钟就是 18 万条。所以如果你积压了几百万到上千万的数据,即使消费者恢复了,也需要大概 1 小时的时间才能恢复过来。
一般这个时候,只能临时紧急扩容了,具体操作步骤和思路如下:
- 先修复 consumer 的问题,确保其恢复消费速度,然后将现有 consumer 都停掉。
- 新建一个 topic,partition 是原来的 10 倍,临时建立好原先 10 倍的 queue 数量。
- 然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue。
- 接着临时征用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。
- 等快速消费完积压数据之后,得恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。
8 kafka是怎样存储数据的
1,在kafka集群中,每个broker(一个kafka实例称为一个broker)中有多个topic,topic数量可以自己设定。在每个topic中又有多个partition,每个partition为一个分区。kafka的分区有自己的命名的规则,它的命名规则为topic的名称+有序序号,这个序号从0开始依次增加。
2,在每个partition中有可以分为多个segment file。当生产者往partition中存储数据时,内存中存不下了,就会往segment file里面存储。我们配置kafka每个segment file的大小是2G,在存储数据时,会先生成一个segment file,当这个segment file到2G之后,再生成第二个segment file 以此类推。每个segment file对应两个文件,分别是以.log结尾的数据文件和以.index结尾的索引文件。在服务器上,每个partition是一个文件夹,每个segment是一个文件。
9 kafka多久清理一次数据
log.retention.hours=168 默认情况下每周清理
10 消费者多于partition什么样子?少于partition呢。
消费者多于partition会导致,某些消费者没法获取数据;而消费者少于partition则某些消费者会获得多个partition中的数据,如果数据要求有顺序,请保证消费者数量和partition一致。
11 ISR怎样移除异常的replicPatition副本
如果partation配置参数为:,那么超过这个时间副本还没有同步数据就会认为副本异常,就会从isr中移除,顺便可以解释下hw和leo的概念。
PS1:kafka在实际发生读写磁盘文件之前,也使用了“页缓存技术”也就是操作系统缓存“os cahce”。
kafka那些事儿的更多相关文章
- Structured Streaming从Kafka 0.8中读取数据的问题
众所周知,Structured Streaming默认支持Kafka 0.10,没有提供针对Kafka 0.8的Connector,但这对高手来说不是事儿,于是有个Hortonworks的邵大牛(前段 ...
- 基于Kafka Connect框架DataPipeline可以更好地解决哪些企业数据集成难题?
DataPipeline已经完成了很多优化和提升工作,可以很好地解决当前企业数据集成面临的很多核心难题. 1. 任务的独立性与全局性. 从Kafka设计之初,就遵从从源端到目的的解耦性.下游可以有很多 ...
- Kafka、ActiveMQ、RabbitMQ、RocketMQ 区别以及高可用原理
为什么使用消息队列 其实就是问问你消息队列都有哪些使用场景,然后你项目里具体是什么场景,说说你在这个场景里用消息队列是什么? 面试官问你这个问题,期望的一个回答是说,你们公司有个什么业务场景,这个业务 ...
- 打造实时数据集成平台——DataPipeline基于Kafka Connect的应用实践
导读:传统ETL方案让企业难以承受数据集成之重,基于Kafka Connect构建的新型实时数据集成平台被寄予厚望. 在4月21日的Kafka Beijing Meetup第四场活动上,DataPip ...
- 跟我一起学kafka(一)
从昨天下午接到新任务,要采集一个法院网站得所有公告,大概是需要采集这个网站得所有公告列表里得所有txt内容,txt文件里边是一件件赤裸裸得案件,记录这案由,原告被告等相关属性(不知道该叫什么就称之为属 ...
- 如何保证MQ的顺序性?比如Kafka
三.如何保证消息的顺序性 1. rabbitmq 拆分多个queue,每个queue一个consumer,就是多一些queue而已,确实是麻烦点:或者就一个queue但是对应一个consumer,然后 ...
- kafka相关
一.消息队列优点(解耦.异步.削峰)二.用消息队列都有什么优点和缺点?三.kafka.activemq.rabbitmq.rocketmq都有什么区别四.如何保证消息队列的高可用啊?五.如何保证消息不 ...
- Kafka处理请求的全流程分析
大家好,我是 yes. 这是我的第三篇Kafka源码分析文章,前两篇讲了日志段的读写和二分算法在kafka索引上的应用 今天来讲讲 Kafka Broker端处理请求的全流程,剖析下底层的网络通信是如 ...
- 从面试角度学完 Kafka
Kafka 是一个优秀的分布式消息中间件,许多系统中都会使用到 Kafka 来做消息通信.对分布式消息系统的了解和使用几乎成为一个后台开发人员必备的技能.今天码哥字节就从常见的 Kafka 面试题入手 ...
随机推荐
- 基于腾讯云监控 API 的 Grafana App 插件开发
Tencent Cloud Monitor App Grafana 是一个开源的时序性统计和监控平台,支持例如 elasticsearch.graphite.influxdb 等众多的数据源,并以功能 ...
- Ubuntu16.04启动tomcat缓慢问题之解决方案
问题信息: -May- ::] org.apache.catalina.util.SessionIdGeneratorBase.createSecureRandom Creation of Secur ...
- TThread.Queue和TThread.Synchronize的区别
TThread.Queue和TThread.Synchronize的区别 效果上:二者的作用都是让业务代码在主线程中执行,差别: Synchronize是阻塞,Queue是非阻塞 代码上 两个方法最终 ...
- 【转】iPhone手机获取uuid 安装测试app
iPhone手机获取uuid 安装测试app UDID是一种iOS设备的特殊识别码.除序号之外,每台ios装置都另有一组独一无二的号码,我们就称之为识别码( Unique Device Identif ...
- NPAPI插件开发详细记录:用VS2010开发NPAPI插件步骤<转>
原帖地址:https://blog.csdn.net/z6482/article/details/7660748 ------------------------------------------- ...
- C# ffmpeg 视频处理格式转换和添加水印
通过C#调用ffmpeg 将flv格式转换为mp4格式,并添加水印 C#调用ffmpeg的方法封装如下: /// <summary>/// 视频处理器ffmpeg.exe的位置/// &l ...
- 码云 Gitee 云端软件平台学习--GitHub
码云 Gitee http://git.oschina.net/jackjiang/MobileIMSDK http://www.blogjava.net/jb2011/archive/2018/11 ...
- 目标检测标注工具labelImg安装及使用
目标检测中,原始图片的标注过程是非常重要的,它的作用是在原始图像中标注目标物体位置并对每张图片生成相应的xml文件表示目标标准框的位置.本文介绍一款使用方便且能够标注多类别并能直接生成xml文件的标注 ...
- ubuntu系统TCP连接参数优化-TIME_WAIT过多解决办法
状态:描述CLOSED:无连接是活动的或正在进行LISTEN:服务器在等待进入呼叫SYN_RECV:一个连接请求已经到达,等待确认SYN_SENT:应用已经开始,打开一个连接ESTABLISHED:正 ...
- 海思 Hi3516A Hi3518E V200 芯片介绍
海康是生产监控摄像头和硬盘录像机的,海思是提供机器里芯片的,海思属于华为的. http://www.hisilicon.com/en/Products/ProductList/Surveillance ...