Embedding Layer
在深度学习实验中经常会遇Eembedding层,然而网络上的介绍可谓是相当含糊。比如 Keras中文文档中对嵌入层 Embedding的介绍除了一句 “嵌入层将正整数(下标)转换为具有固定大小的向量”之外就不愿做过多的解释。那么我们为什么要使用嵌入层 Embedding呢? 主要有这两大原因:
1、使用One-hot 方法编码的向量会很高维也很稀疏。假设我们在做自然语言处理(NLP)中遇到了一个包含2000个词的字典,当时用One-hot编码时,每一个词会被一个包含2000个整数的向量来表示,其中1999个数字是0,要是我的字典再大一点的话这种方法的计算效率岂不是大打折扣?
2、训练神经网络的过程中,每个嵌入的向量都会得到更新。如果你看到了博客上面的图片你就会发现在多维空间中词与词之间有多少相似性,这使我们能可视化的了解词语之间的关系,不仅仅是词语,任何能通过嵌入层 Embedding 转换成向量的内容都可以这样做。
Eg 1:
对于句子“deep learning is very deep”:
使用嵌入层embedding 的第一步是通过索引对该句子进行编码,这里我们给每一个不同的句子分配一个索引,上面的句子就会变成这样:
"1 2 3 4 1"
接下来会创建嵌入矩阵,我们要决定每一个索引需要分配多少个‘潜在因子’,这大体上意味着我们想要多长的向量,通常使用的情况是长度分配为32和50。在这篇博客中,为了保持文章可读性这里为每个索引指定6个潜在因子。这样,我们就可以使用嵌入矩阵来而不是庞大的one-hot编码向量来保持每个向量更小。简而言之,嵌入层embedding在这里做的就是把单词“deep”用向量[.32, .02, .48, .21, .56, .15]来表达。然而并不是每一个单词都会被一个向量来代替,而是被替换为用于查找嵌入矩阵中向量的索引。
eg 2:
假如我们有一个100W X10W的矩阵,用它乘上一个10W X 20的矩阵,我们可以把它降到100W X 20,瞬间量级降了。。。10W/20=5000倍!!!
这就是嵌入层的一个作用——降维。
然后中间那个10W X 20的矩阵,可以理解为查询表,也可以理解为映射表,也可以理解为过度表;
参考链接:https://blog.csdn.net/weixin_42078618/article/details/82999906
https://blog.csdn.net/u010412858/article/details/77848878
PS: pixel wise metric learning
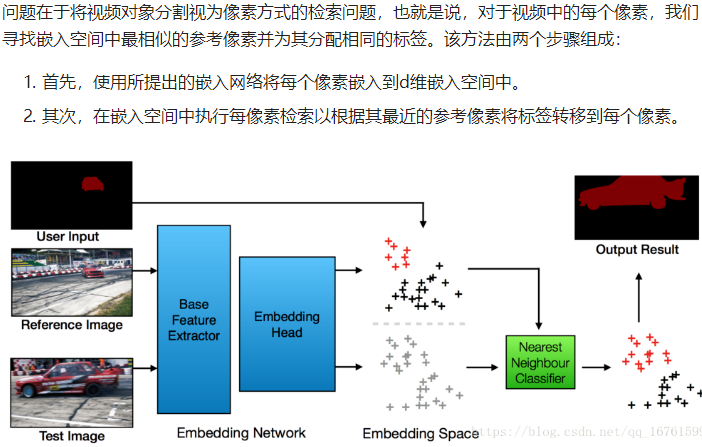
嵌入模型:在所提出的模型f中,其中每个像素x j,i被表示为d维嵌入向量ej,i = f(xj,i)。理想地,属于相同对象的像素在嵌入空间中彼此靠近,并且属于不同对象的像素彼此远离。
Embedding Layer的更多相关文章
- NLP 中的embedding layer
https://blog.csdn.net/chuchus/article/details/78386059 词汇是语料库的基本元素, 所以, 使用embedding layer来学习词嵌入, 将一个 ...
- Word Embedding/RNN/LSTM
Word Embedding Word Embedding是一种词的向量表示,比如,对于这样的"A B A C B F G"的一个序列,也许我们最后能得到:A对应的向量为[0.1 ...
- ConceptVector: Text Visual Analytics via Interactive Lexicon Building using Word Embedding
论文简介 本文是对词嵌入的一种应用,用户可以根据自己的需要创建concept,系统根据用户提供的seed word推荐其他词汇,以帮助用户更高的构建自己的concept.同时用户可以利用自己创建的 ...
- 神经网络中embedding层作用——本质就是word2vec,数据降维,同时可以很方便计算同义词(各个word之间的距离),底层实现是2-gram(词频)+神经网络
Embedding tflearn.layers.embedding_ops.embedding (incoming, input_dim, output_dim, validate_indices= ...
- (转) How to Train a GAN? Tips and tricks to make GANs work
How to Train a GAN? Tips and tricks to make GANs work 转自:https://github.com/soumith/ganhacks While r ...
- RNN 入门教程 Part 4 – 实现 RNN-LSTM 和 GRU 模型
转载 - Recurrent Neural Network Tutorial, Part 4 – Implementing a GRU/LSTM RNN with Python and Theano ...
- How much training data do you need?
How much training data do you need? //@樵夫上校: 0. 经验上,10X规则(训练数据是模型参数量的10倍)适用与大多数模型,包括shallow networ ...
- 【IOS笔记】Views
Views Because view objects are the main way your application interacts with the user, they have many ...
- (转) Written Memories: Understanding, Deriving and Extending the LSTM
R2RT Written Memories: Understanding, Deriving and Extending the LSTM Tue 26 July 2016 When I was ...
随机推荐
- [PKUSC2018]主斗地
暴搜 非常暴力的搜索,以至于我都不相信我能过. 方法是:暴力枚举所有牌型,然后暴力判断是否可行. 暴力枚举部分: 非常暴力: void dfs(int x,int l){ if(l==0){ flag ...
- Linux本地内核提权CVE-2019-13272
简介:当调用PTRACE_TRACEME时,ptrace_link函数将获得对父进程凭据的RCU引用,然后将该指针指向get_cred函数.但是,对象struct cred的生存周期规则不允许无条件地 ...
- 任晓蕊 2019-2020-1 20199302《Linux内核原理与分析》第四周作业
实验内容 在实验楼的环境中敲入命令 cd LinuxKernel/ qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img ...
- PHP流程控制之do...while循环的区别
do...while与while的语法结构基本一样,也是一个布尔型循环,功能也基本一样.大理石平台价格 基本语法规定如下: do { //代码块 } while (判断); do...while ...
- CDH 大数据平台搭建
一.概述 Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”),基于Web的用户界面,支持大多数Hadoop组件,包括 ...
- Qt文件读写操作
原文地址:https://www.cnblogs.com/flowingwind/p/8336159.html QFile Class 1.read读文件 加载文件对象 QFile file(&qu ...
- 洛谷 P2872 [USACO07DEC]道路建设Building Roads 题解
P2872 [USACO07DEC]道路建设Building Roads 题目描述 Farmer John had just acquired several new farms! He wants ...
- lixuxmint系统定制与配置(3)-字体
小书匠Linux 有些系统自带的字体实在太难看了,看起来不清晰,不明确,有一个好的字体,可以带来好心情,并提高工作与效率. 1.常用中文字体 文泉驿微黑,微软雅黑,思源黑体 2.字体安装 2.1检查已 ...
- Codeforces 1137F Matches Are Not a Child's Play [LCT]
Codeforces 很好,通过这题对LCT的理解又深了一层. 思路 (有人说这是套路题,然而我没有见过/kk) 首先发现,删点可以从根那里往下删,非常难受,所以把权值最大的点提为根. 然后考虑\(x ...
- avalon怎么让重叠的图片改变显示层级?
<span style="display: inline-block;width:20%;"> <span style="display: inline ...