Spark 系列(十二)—— Spark SQL JOIN 操作
一、 数据准备
本文主要介绍 Spark SQL 的多表连接,需要预先准备测试数据。分别创建员工和部门的 Datafame,并注册为临时视图,代码如下:
val spark = SparkSession.builder().appName("aggregations").master("local[2]").getOrCreate()
val empDF = spark.read.json("/usr/file/json/emp.json")
empDF.createOrReplaceTempView("emp")
val deptDF = spark.read.json("/usr/file/json/dept.json")
deptDF.createOrReplaceTempView("dept")两表的主要字段如下:
emp 员工表
|-- ENAME: 员工姓名
|-- DEPTNO: 部门编号
|-- EMPNO: 员工编号
|-- HIREDATE: 入职时间
|-- JOB: 职务
|-- MGR: 上级编号
|-- SAL: 薪资
|-- COMM: 奖金 dept 部门表
|-- DEPTNO: 部门编号
|-- DNAME: 部门名称
|-- LOC: 部门所在城市注:emp.json,dept.json 可以在本仓库的resources 目录进行下载。
二、连接类型
Spark 中支持多种连接类型:
- Inner Join : 内连接;
- Full Outer Join : 全外连接;
- Left Outer Join : 左外连接;
- Right Outer Join : 右外连接;
- Left Semi Join : 左半连接;
- Left Anti Join : 左反连接;
- Natural Join : 自然连接;
- Cross (or Cartesian) Join : 交叉 (或笛卡尔) 连接。
其中内,外连接,笛卡尔积均与普通关系型数据库中的相同,如下图所示:
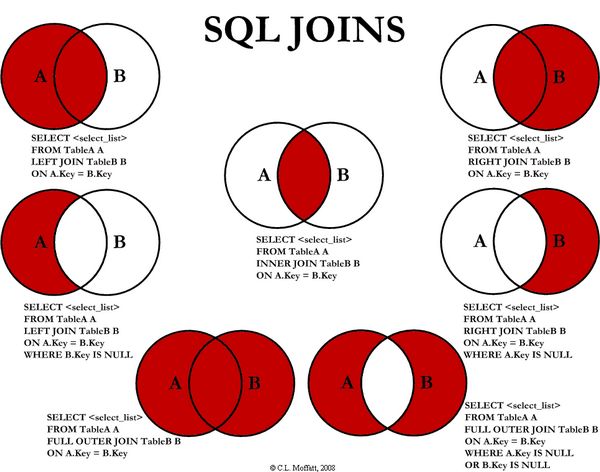
这里解释一下左半连接和左反连接,这两个连接等价于关系型数据库中的 IN 和 NOT IN 字句:
-- LEFT SEMI JOIN
SELECT * FROM emp LEFT SEMI JOIN dept ON emp.deptno = dept.deptno
-- 等价于如下的 IN 语句
SELECT * FROM emp WHERE deptno IN (SELECT deptno FROM dept)
-- LEFT ANTI JOIN
SELECT * FROM emp LEFT ANTI JOIN dept ON emp.deptno = dept.deptno
-- 等价于如下的 IN 语句
SELECT * FROM emp WHERE deptno NOT IN (SELECT deptno FROM dept)所有连接类型的示例代码如下:
2.1 INNER JOIN
// 1.定义连接表达式
val joinExpression = empDF.col("deptno") === deptDF.col("deptno")
// 2.连接查询
empDF.join(deptDF,joinExpression).select("ename","dname").show()
// 等价 SQL 如下:
spark.sql("SELECT ename,dname FROM emp JOIN dept ON emp.deptno = dept.deptno").show()2.2 FULL OUTER JOIN
empDF.join(deptDF, joinExpression, "outer").show()
spark.sql("SELECT * FROM emp FULL OUTER JOIN dept ON emp.deptno = dept.deptno").show()2.3 LEFT OUTER JOIN
empDF.join(deptDF, joinExpression, "left_outer").show()
spark.sql("SELECT * FROM emp LEFT OUTER JOIN dept ON emp.deptno = dept.deptno").show()2.4 RIGHT OUTER JOIN
empDF.join(deptDF, joinExpression, "right_outer").show()
spark.sql("SELECT * FROM emp RIGHT OUTER JOIN dept ON emp.deptno = dept.deptno").show()2.5 LEFT SEMI JOIN
empDF.join(deptDF, joinExpression, "left_semi").show()
spark.sql("SELECT * FROM emp LEFT SEMI JOIN dept ON emp.deptno = dept.deptno").show()2.6 LEFT ANTI JOIN
empDF.join(deptDF, joinExpression, "left_anti").show()
spark.sql("SELECT * FROM emp LEFT ANTI JOIN dept ON emp.deptno = dept.deptno").show()2.7 CROSS JOIN
empDF.join(deptDF, joinExpression, "cross").show()
spark.sql("SELECT * FROM emp CROSS JOIN dept ON emp.deptno = dept.deptno").show()2.8 NATURAL JOIN
自然连接是在两张表中寻找那些数据类型和列名都相同的字段,然后自动地将他们连接起来,并返回所有符合条件的结果。
spark.sql("SELECT * FROM emp NATURAL JOIN dept").show()以下是一个自然连接的查询结果,程序自动推断出使用两张表都存在的 dept 列进行连接,其实际等价于:
spark.sql("SELECT * FROM emp JOIN dept ON emp.deptno = dept.deptno").show()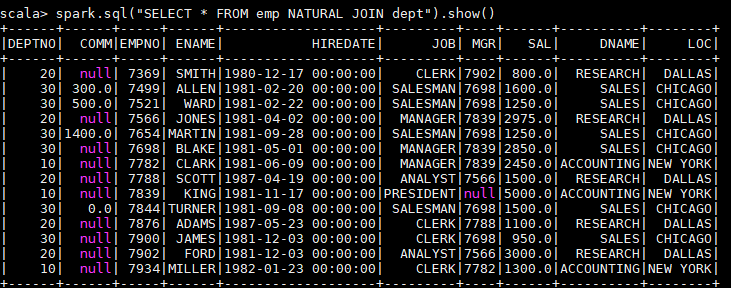
由于自然连接常常会产生不可预期的结果,所以并不推荐使用。
三、连接的执行
在对大表与大表之间进行连接操作时,通常都会触发 Shuffle Join,两表的所有分区节点会进行 All-to-All 的通讯,这种查询通常比较昂贵,会对网络 IO 会造成比较大的负担。
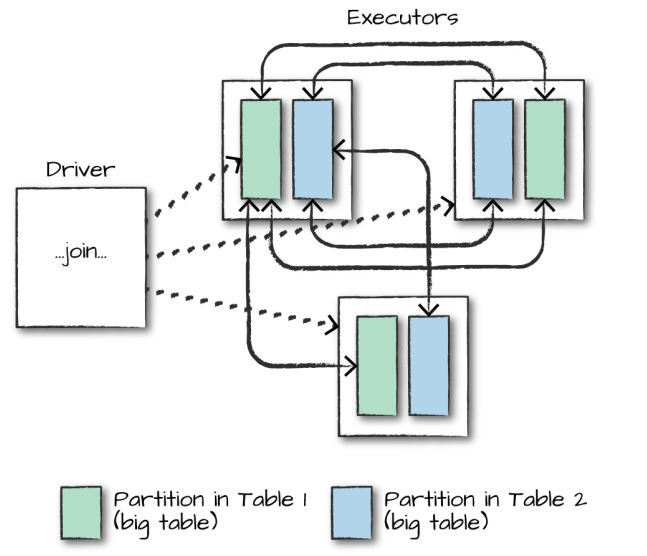
而对于大表和小表的连接操作,Spark 会在一定程度上进行优化,如果小表的数据量小于 Worker Node 的内存空间,Spark 会考虑将小表的数据广播到每一个 Worker Node,在每个工作节点内部执行连接计算,这可以降低网络的 IO,但会加大每个 Worker Node 的 CPU 负担。

是否采用广播方式进行 Join 取决于程序内部对小表的判断,如果想明确使用广播方式进行 Join,则可以在 DataFrame API 中使用 broadcast 方法指定需要广播的小表:
empDF.join(broadcast(deptDF), joinExpression).show()参考资料
- Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Spark 系列(十二)—— Spark SQL JOIN 操作的更多相关文章
- SQL Server 2008空间数据应用系列十二:Bing Maps中呈现GeoRSS订阅的空间数据
原文:SQL Server 2008空间数据应用系列十二:Bing Maps中呈现GeoRSS订阅的空间数据 友情提示,您阅读本篇博文的先决条件如下: 1.本文示例基于Microsoft SQL Se ...
- MySQL 系列(二) 你不知道的数据库操作
第一篇:MySQL 系列(一) 生产标准线上环境安装配置案例及棘手问题解决 第二篇:MySQL 系列(二) 你不知道的数据库操作 本章内容: 查看\创建\使用\删除 数据库 用户管理及授权实战 局域网 ...
- Alamofire源码解读系列(十二)之请求(Request)
本篇是Alamofire中的请求抽象层的讲解 前言 在Alamofire中,围绕着Request,设计了很多额外的特性,这也恰恰表明,Request是所有请求的基础部分和发起点.这无疑给我们一个Req ...
- 爬虫系列(十二) selenium的基本使用
一.selenium 简介 随着网络技术的发展,目前大部分网站都采用动态加载技术,常见的有 JavaScript 动态渲染和 Ajax 动态加载 对于爬取这些网站,一般有两种思路: 分析 Ajax 请 ...
- 第十二章 Python文件操作【转】
12.1 open() open()函数作用是打开文件,返回一个文件对象. 用法格式:open(name[, mode[, buffering[,encoding]]]) -> file obj ...
- Web 前端开发精华文章推荐(jQuery、HTML5、CSS3)【系列十二】
2012年12月12日,[<Web 前端开发人员和设计师必读文章>系列十二]和大家见面了.梦想天空博客关注 前端开发 技术,分享各种增强网站用户体验的 jQuery 插件,展示前沿的 HT ...
- struts2官方 中文教程 系列十二:控制标签
介绍 struts2有一些控制语句的标签,本教程中我们将讨论如何使用 if 和iterator 标签.更多的控制标签可以参见 tags reference. 到此我们新建一个struts2 web 项 ...
- Spark系列之二——一个高效的分布式计算系统
1.什么是Spark? Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有H ...
- Spark(十二)--性能调优篇
一段程序只能完成功能是没有用的,只能能够稳定.高效率地运行才是生成环境所需要的. 本篇记录了Spark各个角度的调优技巧,以备不时之需. 一.配置参数的方式和观察性能的方式 额...从最基本的开始讲, ...
- Spark(十二)SparkSQL简单使用
一.SparkSQL的进化之路 1.0以前: Shark 1.1.x开始:SparkSQL(只是测试性的) SQL 1.3.x: SparkSQL(正式版本)+Datafram ...
随机推荐
- 2019 SDN第三次上机作业
作业要求: 利用Mininet仿真平台构建给定的网络拓扑,配置主机h1和h2的IP地址(h1:10.0.0.1,h2:10.0.0.2),测试两台主机之间的网络连通性: 利用Wireshark工具,捕 ...
- Server concepts 详解
server status 是由 vm_state和task_state 计算出来的,vm_state是虚机当前的稳定状态(例如Active, Error),task_state是虚机当前的瞬间状态( ...
- Compute API 关键概念 详解
Compute API 是 RESTful HTTP 服务,提供管理虚机的能力. 虚机可能有不同的内存大小,CPU数量,硬盘大小,能够在几分钟之内创建出来.和虚机的交互,可以通过Compute API ...
- Alpha2
队名:福大帮 组长博客链接:https://www.cnblogs.com/mhq-mhq/p/11885037.html 作业博客 :https://edu.cnblogs.com/campus/f ...
- Spring Cloud Eureka源码分析 --- client 注册流程
Eureka Client 是一个Java 客户端,用于简化与Eureka Server的交互,客户端同时也具备一个内置的.使用轮询负载算法的负载均衡器. 在应用启动后,将会向Eureka Serve ...
- Linux /var/log下各种日志文件
Linux /var/log下各种日志文件:
- windows服务器卸载补丁命令【转】
一.可以试用cmd命令 wusa.exe /uninstall /kb: wusa.exe /uninstall /kb: wusa.exe /uninstall /kb: 二.使用DISM卸载补 ...
- 【mybatis源码学习】mybatis的结果映射
一.mybatis结果映射的流程 二.mybatis结果映射重要的类 1.org.apache.ibatis.executor.resultset.ResultSetWrapper(对sql执行返回的 ...
- tar_ssh 配合下载文件(适合于带宽充足传输大量小文件场景)
局域网网速快,但是当要传输大量小文件时倘若仍然使用scp,由于每个文件传输完毕都需要独立进行传输完毕的确认,这样就无法充分利用带宽.一方面等待确认时tcp窗口无法填满,另一方面文件传完之前确认也不会开 ...
- Servlet 添加 Cookie 返回 500 的问题
在学习 Servlet 中,学习 Cookie 的时候,往 response 中添加 Cookie ,结果出现 500 的错误 Cookie cookie1 = new Cookie(COOKIE_N ...