Requests库详细的用法
介绍
对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助。入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取。那么简单介绍一下 requests 库的基本用法
安装
利用 pip 安装
pip install requests
基本请求
req = requests.get("http://www.baidu.com")
req = requests.post("http://www.baidu.com")
req = requests.put("http://www.baidu.com")
req = requests.delete("http://www.baidu.com")
req = requests.head("http://www.baidu.com")
req = requests.options("http://www.baidu.com")
get请求
参数是字典,我们也可以传递json类型的参数:
import requests
url = "http://www.baidu.com/s"
params = {'wd': '毛利'}
response = requests.get(url, params=params)
print(response.url) # http://www.baidu.com/s?wd=%E6%AF%9B%E5%88%A9
response.encoding = 'utf-8'
html = response.text
# print(html)
post请求
参数是字典,我们也可以传递json类型的参数:
url = "https://accounts.douban.com/j/mobile/login/basic"
formdata = {
'ck': '',
'name':'13717378202',
'password': '',
'remember': 'false',
'ticket': '',
}
response = requests.post(url, data=formdata)
response.encoding = 'utf-8'
html = response.text
# print(html)
传递URL参数也不用再像urllib中那样需要去拼接URL,而是简单的,构造一个字典,并在请求时将其传递给params参数:

此时,查看请求的URL,则可以看到URL已经构造正确了:

并且,有时候我们会遇到相同的url参数名,但有不同的值,而python的字典又不支持键的重名,那么我们可以把键的值用列表表示:

自定义请求头部
伪装请求头部是采集时经常用的,我们可以用这个方法来隐藏:
headers = {'User-Agent': 'python'}
r = requests.get('http://www.baiducom', headers = headers)
print(r.request.headers['User-Agent'])
设置超时时间
可以通过timeout属性设置超时时间,一旦超过这个时间还没获得响应内容,就会提示错误
requests.get('http://github.com', timeout=0.001)
代理访问
采集时为避免被封IP,经常会使用代理。requests也有相应的proxies属性
import requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "https://10.10.1.10:1080",
}
requests.get("http://httpbin.org/get", proxies=proxies)
如果代理需要账户和密码,则需这样
proxies = {
"http": "http://user:pass@10.10.1.10:3128/",
}
重定向
在网络请求中,我们常常会遇到状态码是3开头的重定向问题,在Requests中是默认开启允许重定向的,即遇到重定向时,会自动继续访问。

ssl验证
有时候我们使用了抓包工具,这个时候由于抓包工具提供的证书并不是由受信任的数字证书颁发机构颁发的,所以证书的验证会失败,所以我们就需要关闭证书验证。
在请求的时候把verify参数设置为False就可以关闭证书验证了。

但是关闭验证后,会有一个比较烦人的warning

可以使用以下方法关闭警告

获取响应信息
代码 含义
resp.json() 获取响应内容(以json字符串)
resp.text 获取响应内容 (以字符串)
resp.content 获取响应内容(以字节的方式)
resp.headers 获取响应头内容
resp.url 获取访问地址
resp.encoding 获取网页编码
resp.request.headers 请求头内容
resp.cookie 获取cookie
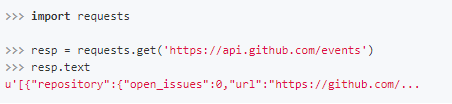
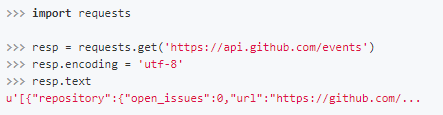
Requests会自动的根据响应的报头来猜测网页的编码是什么,然后根据猜测的编码来解码网页内容,基本上大部分的网页都能够正确的被解码。而如果发现text解码不正确的时候,就需要我们自己手动的去指定解码的编码格式
而如果你需要获得原始的二进制数据,那么使用content属性即可。

如果我们访问之后获得的数据是JSON格式的,那么我们可以使用json()方法,直接获取转换成字典格式的数据。

通过status_code属性获取响应的状态码

通过headers属性获取响应的报头
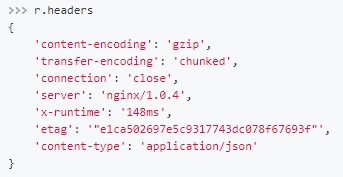
通过cookies属性获取服务器返回的cookies

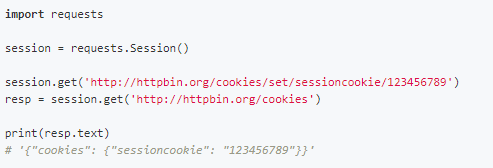
session自动保存cookies
在Requests中,实现了Session(会话)功能,当我们使用Session时,能够像浏览器一样,在没有关闭关闭浏览器时,能够保持住访问的状态。
这个功能常常被我们用于登陆之后的数据获取,使我们不用再一次又一次的传递cookies。
首先我们需要去生成一个Session对象,然后用这个Session对象来发起访问,发起访问的方法与正常的请求是一摸一样的。
```
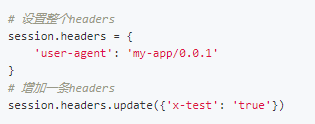
同时,需要注意的是,如果是我们在get()方法中传入headers和cookies等数据,那么这些数据只在当前这一次请求中有效。如果你想要让一个headers在Session的整个生命周期内都有效的话,需要用以下的方式来进行设置:无锡人流多少钱 http://www.bhnfkyy.com/
小试牛刀
登录豆瓣
步骤
找到登录的url,保存cookie
用session保存对话的cookie,再访问网页
# -*- coding:utf-8 -*-
# time :2019/4/3 12:55
# author: 毛利
import requests
class DouBanLogin(object):
def __init__(self,name,password):
self.name = name
self.password = password
def login(self):
sesstion = requests.Session()
sesstion.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
})
# 拿到cookie
#sesstion.get('https://www.douban.com/')
#print(sesstion.cookies)
login_url = 'https://accounts.douban.com/j/mobile/login/basic'
form_data = {
'ck':'' ,
'name': self.name,
'password': self.password,
'remember': 'false',
'ticket': ''
}
res = sesstion.post(login_url, data=form_data)
# print(res.text)
if res.json()["status"] == "success":
print('登录成功')
res = sesstion.get('https://www.douban.com/')
print(res.text)
else:
print('登录失败')
if __name__ == '__main__':
name = input('请输入你的账号')
password = input('请输入你的密码')
login = DouBanLogin(name, password)
login.login()
Requests库详细的用法的更多相关文章
- Python中第三方库Requests库的高级用法详解
Python中第三方库Requests库的高级用法详解 虽然Python的标准库中urllib2模块已经包含了平常我们使用的大多数功能,但是它的API使用起来让人实在感觉不好.它已经不适合现在的时代, ...
- 爬虫requests库的基本用法
需要注意的几个点: 1.后面的s是一个虚拟目录 2.url后面不用加问号,发起请求的时候会自动帮你加上问号 get_url = 'http://www.baidu.com/s' 3. url的特性:u ...
- 5.爬虫 requests库讲解 高级用法
0.文件上传 import requests files = {'file': open('favicon.ico', 'rb')} response = requests.post("ht ...
- 芝麻HTTP: Python爬虫利器之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- Python爬虫利器一之Requests库的用法
前言 之前我们用了 urllib 库,这个作为入门的工具还是不错的,对了解一些爬虫的基本理念,掌握爬虫爬取的流程有所帮助.入门之后,我们就需要学习一些更加高级的内容和工具来方便我们的爬取.那么这一节来 ...
- (爬虫)requests库
一.requests库简介 urllib库和request库的作用一样,都是服务器发起请求数据,但是requests库比urllib库用起来更方便,它的接口更简单,选用哪种库看自己. 如果没有安装过这 ...
- 【python接口自动化】- 使用requests库发送http请求
前言:什么是Requests ?Requests 是⽤Python语⾔编写,基于urllib,采⽤Apache2 Licensed开源协议的 HTTP 库.它⽐ urllib 更加⽅便,可以节约我们⼤ ...
- Requests库作者另一神器Pipenv的用法
前言 我们在运行 Python 项目的时候经常会遇到一些版本问题,例如 A 项目依赖于 Django 1.5,而 B 项目又依赖 Django 2.0,而我们的系统却只有一个 Python 解释器,我 ...
- (转)Python爬虫利器一之Requests库的用法
官方文档 以下内容大多来自于官方文档,本文进行了一些修改和总结.要了解更多可以参考 官方文档 安装 利用 pip 安装 $ pip install requests 或者利用 easy_install ...
随机推荐
- SpringCloud Gateway跨域配置
Springboot版本:2.1.8.RELEASE SpringCloud版本:Greenwich.SR2 yml配置: spring: cloud: gateway: globalcors: co ...
- docker配置阿里云的仓库源以及安装docker-compose
[root@localhost mnt]# cat /etc/docker/daemon.json { "registry-mirrors": ["https://3la ...
- shell脚本:批量修改文件名(添加/删除文件名中字符)
添加字符 举例如下:批量创建10个随机字符串的文件,要求每个文件名后面添加_aaa,后缀名不变: [root@localhost goodboy]# ls adddbbdedf.html baacj ...
- Java 待学习知识
Java 工厂模式和策略模式 Java 面向对象与面向接口的设计模式 Java 六大设计原则 - 单一职责原则 设计模式之禅 大话设计模式
- python字符串拼接N种姿势
字符串大家都不陌生,应用比较广泛,强大,总是会给你一些惊喜的数据类型.我们本篇文章主要介绍的就是关于字符串的多种方法的拼接. 第一种:直接通过+号拼接 输出结果: 2.通过 str.join()方法拼 ...
- Django框架 + Djiango安装 + First Djiango + 常用命令
一.Django框架 MVC框架和MTV框架 参考:https://www.cnblogs.com/taosiyu/p/11260016.html MVC,全名是Model View Controll ...
- Linux CentOS7 通过 yum 搭建 svn 服务器,并配置权限
1,使用 yum 安装 svn 服务器 yum -y install subversion rpm -ql subversion -- 改命令可以查看 svn 的安装位置 2,创建仓库根目录,可任意选 ...
- [MySQL] MySQL存储过程 事务transaction 数据表重建
直接上代码 -- 删除存储过程 DROP PROCEDURE IF EXISTS `renew_message_queue`; -- 添加; 的转义 DELIMITER ;; CREATE PROCE ...
- Mac Pro 2015休眠掉电解决办法
硬件:Mac Pro 2015 系统:MacOs Mojave 10.14.3 问题:合盖的时候,休眠1小时掉电10%,由于之前是128G原装盘不会有这个问题,后面购买了M.2转接卡,更换1T Int ...
- go 单元测试框架介绍
最近项目在补充单元测试,这里介绍以下几个go里流行的单元测试框架. gomock gostub monkey Convey 下面介绍下各个框架的主要用途 convey 主要用途是用来组织测试用例的 g ...