Python爬虫 | 批量爬取今日头条街拍美图
01
前言
上篇文章我们爬取了今日头条街拍美图,心情相当愉悦,今天这篇文章我们使用Selenium来爬取当当网的畅销图书排行。正所谓书中自有黄金屋,书中自有颜如玉,我们通过读书学习来提高自身的才华,自然能有荣华富贵,也自然少不了漂亮小姐姐。
02
准备工作
在爬取数据前,我们需要安装Selenium库以及Chrome浏览器,并配置好ChromeDriver。
03
Selenium
Selenium是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获得浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些JavaScript动态渲染的页面来说,这种爬取方式非常有效。
Selenium库的安装比较简单一行代码就行:
pip install selenium
也可以到PyPI下载(https://pypi.python.org/pypi/selenium/#downloads)对应的wheel文件,然后进入到wheel文件目录,使用pip安装:
pip install .........whl
安装验证,进入Python命令行交互模式,如下图:

这样Selenium就安装完毕了。
04
ChromeDriver安装
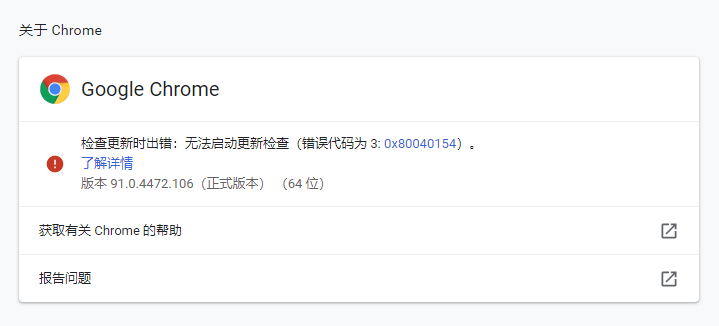
首先我们先查看Chrome的版本:点击Chrome菜单“帮助”--->“关于Google Chrome”,即可查看Chrome的版本号,如下图:
打开ChromeDriver的官方网站,根据自身Chrome浏览器版本下载ChromeDriver并安装:
注意:ChromeDriver和Chrome浏览器一定要对应,否则可能无法正常工作。
ChromeDriver的环境变量配置,直接将chromedriver.exe文件拖到Python的Scripts目录下。
到这来,准备工作就完成了,下面我们正式开始抓取当当网的畅销图书排行。
05
实战演练
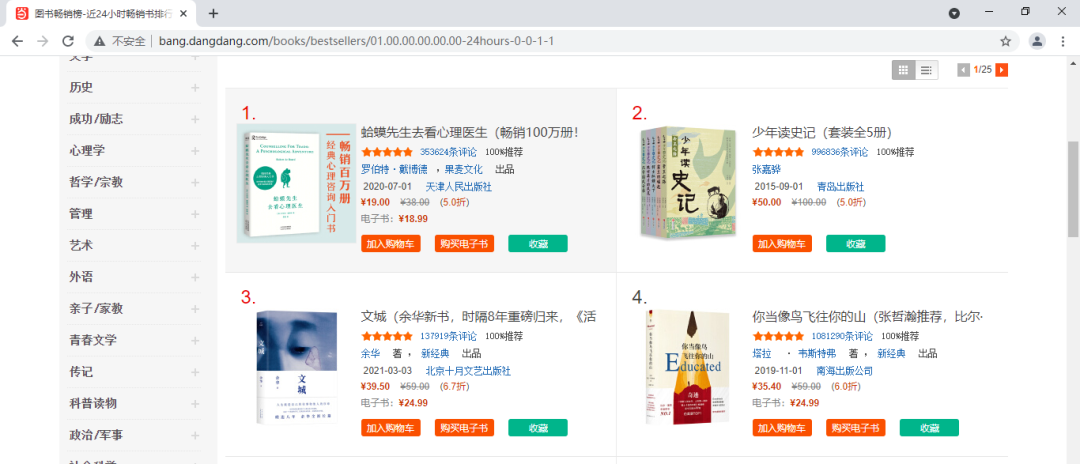
首先,我们进入当当网的畅销图书网页,我们要利用Selenium抓取图书信息并用pyquery解析得到图书的排名、图片、名称、价格、评论等信息。如下图:
进入开发者工具中的Network,查看Request URL,如下图所示:
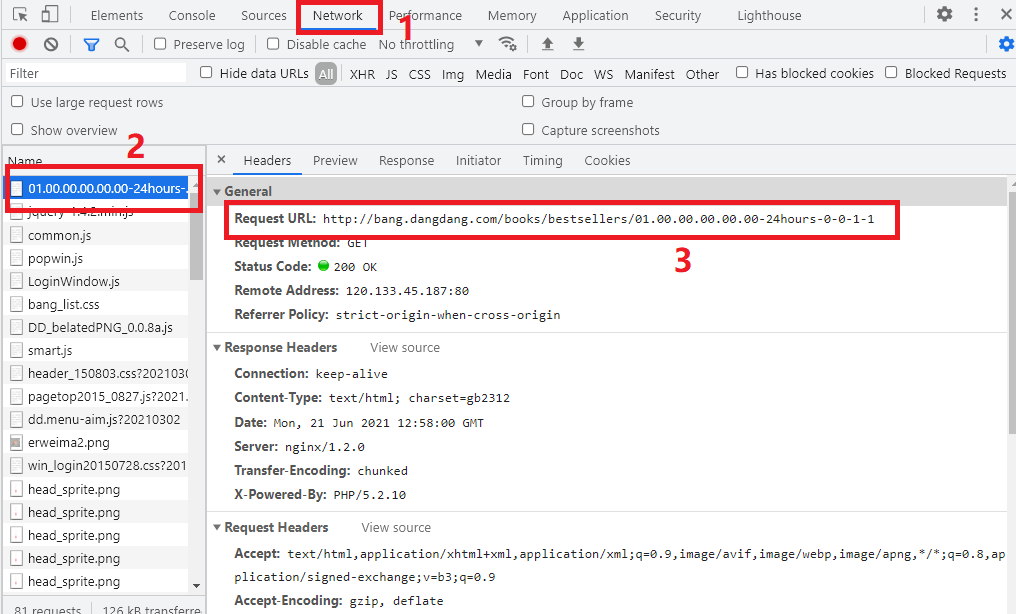
在页面下方,有个分页导航,我们点击下一页,观察Request URL的变化:
http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours\-0-0-1-1 #第1页
http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours\-0-0-1-2 #第2页
http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours\-0-0-1-23 #第23页
http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours\-0-0-1\-page #第n页
我们发现该URL只有最后面的那个数字发生变化,所以我们构造的URL就非常简单了,那个page就是翻页的关键字。
06
首页爬取
首先我们先声明chrome浏览器对应,webdriver支持主流的浏览器,比如说:谷歌浏览器、火狐浏览器、IE浏览器等等。通过WebDriverWait()方法,指定最长等待时间,当规定时间内没加载出来就抛出异常。通过page参数来进行翻页。
代码如下:
browser=webdriver.Chrome()
wait=WebDriverWait(browser,10)
def index_page(page):
print('正在爬取第',page,'页')
try:
url='http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-'+str(page)
browser.get(url)
get_booklist()
except TimeoutException:
index_page(page)
07
解析商品列表
接下来,我们就可以实现get_booklist()方法来解析商品列表了,这里我们直接调用page_source获取页面源代码,然后用pyquery进行解析,实现代码如下:
def get_booklist():
html=browser.page_source
doc=pq(html)
items=doc('.bang_list li').items()
for item in items:
book={
'排名':item.find('.list_num').text(),
'书名':item.find('.name').text(),
'图片':item.find('.pic img').attr('src'),
'评论数':item.find('.star a').text(),
'推荐':item.find('.tuijian').text(),
'作者':item.find('.publisher_info a').text(),
'日期':item.find('.publisher_info span').text(),
'原价':item.find('.price_r').text().replace('¥',''),
'折扣':item.find('.price_s',).text(),
'电子书':item.find('.price_e').text().replace('电子书:','').replace('¥','')
}
saving_book(book)
08
保存数据
接下来,我们将书本信息保存为csv格式,实现代码如下:
with open('data.csv','a',newline='',)as csvfile:
writer=csv.writer(csvfile)
writer.writerow(['排名','书名','图片','评论数','推荐','作者','原价','折扣','电子书'])
def saving_book(book):
with open('data.csv', 'a', newline='')as csfile:
writer = csv.writer(csfile)
writer.writerow([book.get('排名'), book.get('书名'), book.get('图片'), book.get('评论数'), book.get('推荐'), book.get('作者'),book.get('原价'),book.get('折扣'),book.get('电子书')])
09
遍历每页
刚才我们所定义的index_page()方法需要接收参数page,page代表页码,这里我们实现页码遍历即可,实现代码如下:
if __name__ == '__main__':
for page in range(1,3):
index_page(page)
这里我们只遍历2页,感兴趣的可以遍历多页。
10
结果展示
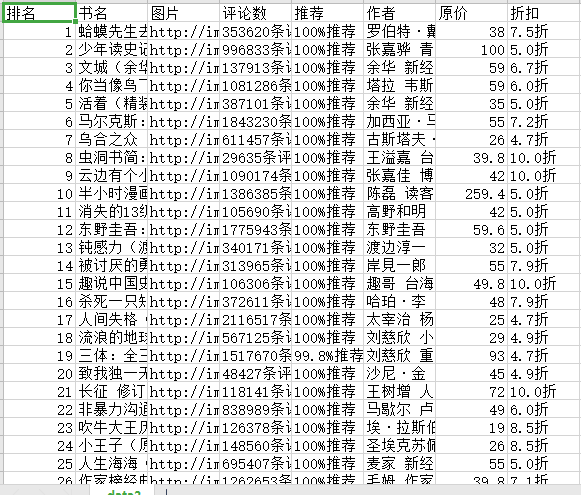
好了,关于Python爬虫——Selenium爬取当当畅销图书排行讲到这里了,感谢观看!我们下篇文章再见!
-------------------**************************** End -------------------************************************
往期精彩文章推荐:

欢迎各位大佬点击链接加入群聊【helloworld开发者社区】:https://jq.qq.com/?_wv=1027&k=mBlk6nzX进群交流IT技术热点。
本文转自 https://mp.weixin.qq.com/s/wU3bo7PH86HnsEnikuU6Wg,如有侵权,请联系删除。
Python爬虫 | 批量爬取今日头条街拍美图的更多相关文章
- 【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图【华为云技术分享】
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 【Python3网络爬虫开发实战】 分析Ajax爬取今日头条街拍美图
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:haoxuan10 本节中,我们以今日头条为例来尝试通过分析Ajax请求 ...
- 转:【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 分析Ajax爬取今日头条街拍美图-崔庆才思路
站点分析 源码及遇到的问题 代码结构 方法定义 需要的常量 关于在代码中遇到的问题 01. 数据库连接 02.今日头条的反爬虫机制 03. json解码遇到的问题 04. 关于response.tex ...
- 分析Ajax来爬取今日头条街拍美图并保存到MongDB
前提:.需要安装MongDB 注:因今日投票网页发生变更,如下代码不保证能正常使用 #!/usr/bin/env python #-*- coding: utf-8 -*- import json i ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- Python Spider 抓取今日头条街拍美图
""" 抓取今日头条街拍美图 """ import os import time import requests from hashlib ...
- 15-分析Ajax请求并抓取今日头条街拍美图
流程框架: 抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果. 抓取详情页内容:解析返回结果,得到详情页的链接,并进一步抓取详情页的信息. 下载图片与保存数据库:将 ...
- 分析Ajax请求并抓取今日头条街拍美图
项目说明 本项目以今日头条为例,通过分析Ajax请求来抓取网页数据. 有些网页请求得到的HTML代码里面并没有我们在浏览器中看到的内容.这是因为这些信息是通过Ajax加载并且通过JavaScript渲 ...
- 2.分析Ajax请求并抓取今日头条街拍美图
import requests from urllib.parse import urlencode # 引入异常类 from requests.exceptions import RequestEx ...
随机推荐
- c++ 中const 原理
前言 在c++ 中和别的语言不一样,高级语言是将const编译了,c又不同这里不介绍,而c++ 是实现了. 正文 const 原理 请看一个解析: const a=10; int*p=&a; ...
- locust常用的配置参数【locust版本:V1.1.1】
locust 官网文档地址:https://docs.locust.io/en/stable/configuration.html Locust QQ 群: 执行命令如: master: locust ...
- 鸿蒙HarmonyOS实战-ArkUI动画(布局更新动画)
前言 动画是一种通过连续展示一系列静止的图像(称为帧)来创造出运动效果的艺术形式.它可以以手绘.计算机生成或其他各种形式呈现.在动画中,每一帧都具有微小的变化,当这些帧被快速播放时,人眼会产生视觉上的 ...
- Linux命令之查找CPU资源利用情况(lscpu和top详解)
1.lscpu命令:获取CPU架构完整详细信息,例如架构信息,CPU模式,CPU频率,CPU核心数.线程数.缓存大小. 在终端输入"lscpu": 参数详解: [Architect ...
- 力扣454(java&python)-四数相加 II(中等)
题目: 给你四个整数数组 nums1.nums2.nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足: 0 <= i, j, k, l &l ...
- 传统微服务框架如何无缝过渡到服务网格 ASM
简介: 让我们一起来看下传统微服务迁移到服务网格技术栈会有哪些已知问题,以及阿里云服务网格 ASM 又是如何无缝支持 SpringCloud .Dubbo 这些服务的. 作者:宇曾 背景 软件 ...
- 【云原生】拿下 Gartner 容器产品第一,阿里云打赢云原生关键一战!
近日,Gartner 发布 2020 年公共云容器报告,据报告显示,阿里云和 AWS 拥有最丰富的产品布局,覆盖 9 项产品能力,并列排名第一. 据 Gartner 分析师评论,阿里云拥有丰富的容器产 ...
- Serverless Kubernetes:理想,现实与未来
简介: 当前 Serverless 容器的行业趋势如何?有哪些应用价值?如果 Kubernetes 天生长在云上,它的架构应该如何设计?Serverless 容器需要哪些基础设施?阿里云容器服务产品负 ...
- Apsara Stack 技术百科 | 可运营的行业云,让云上资源跑起来
简介:企业级云管理平台,如何打造千人千面的个性化体验,从应用.云资源.硬件等进行全局智能优化,实现资源配置的最佳配比,构建精细化运营能力? 距离第一例新冠疫情病例的发现,不知不觉中已经过去两年, ...
- 供应链商品域DDD实践
简介: DDD是一套方法论,实践能否成功,不仅仅是个技术问题,更是执行贯彻实施的问题.本文将就DDD的基本概念和DDD的实施进行分享. 作者 | 侧帽来源 | 阿里技术公众号 前言 供应链商品域DDD ...