hadoop部署2
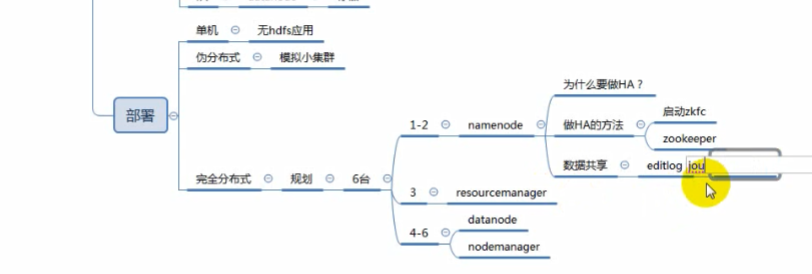
完全分布式部署介绍
学习目标
二、NameNode HA+完全分布式部署
学习目标
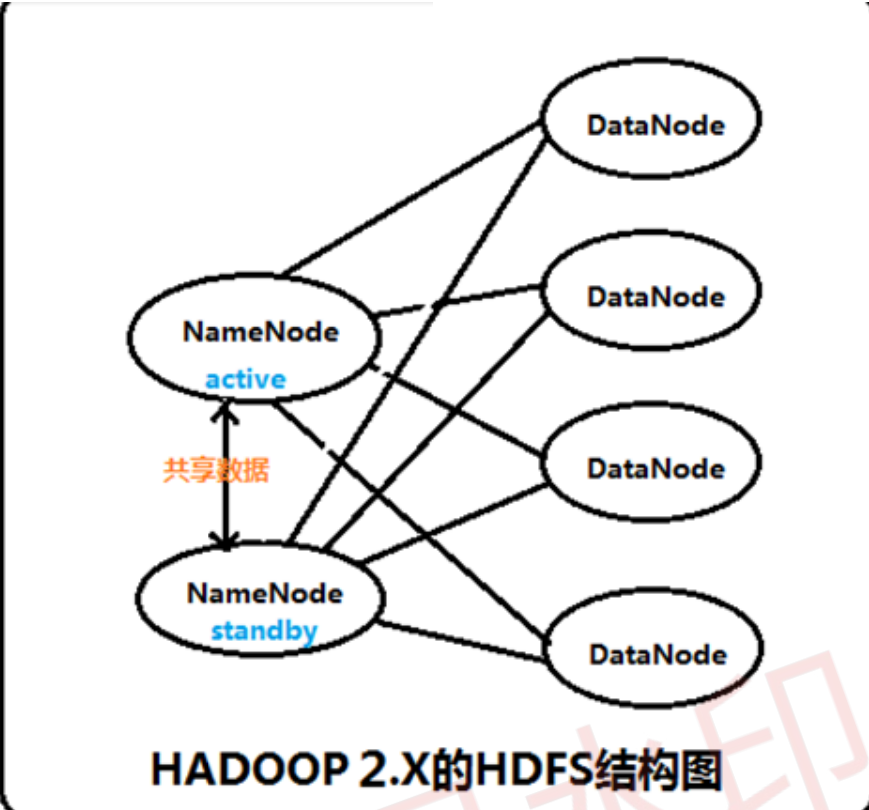
1)什么是HA?
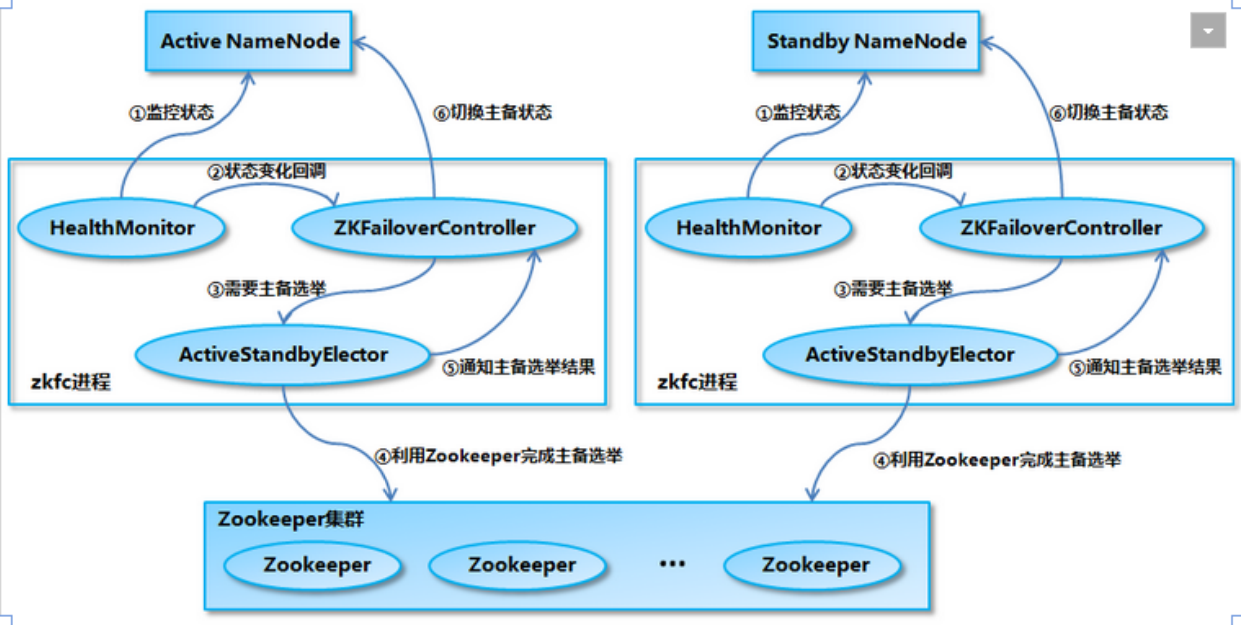
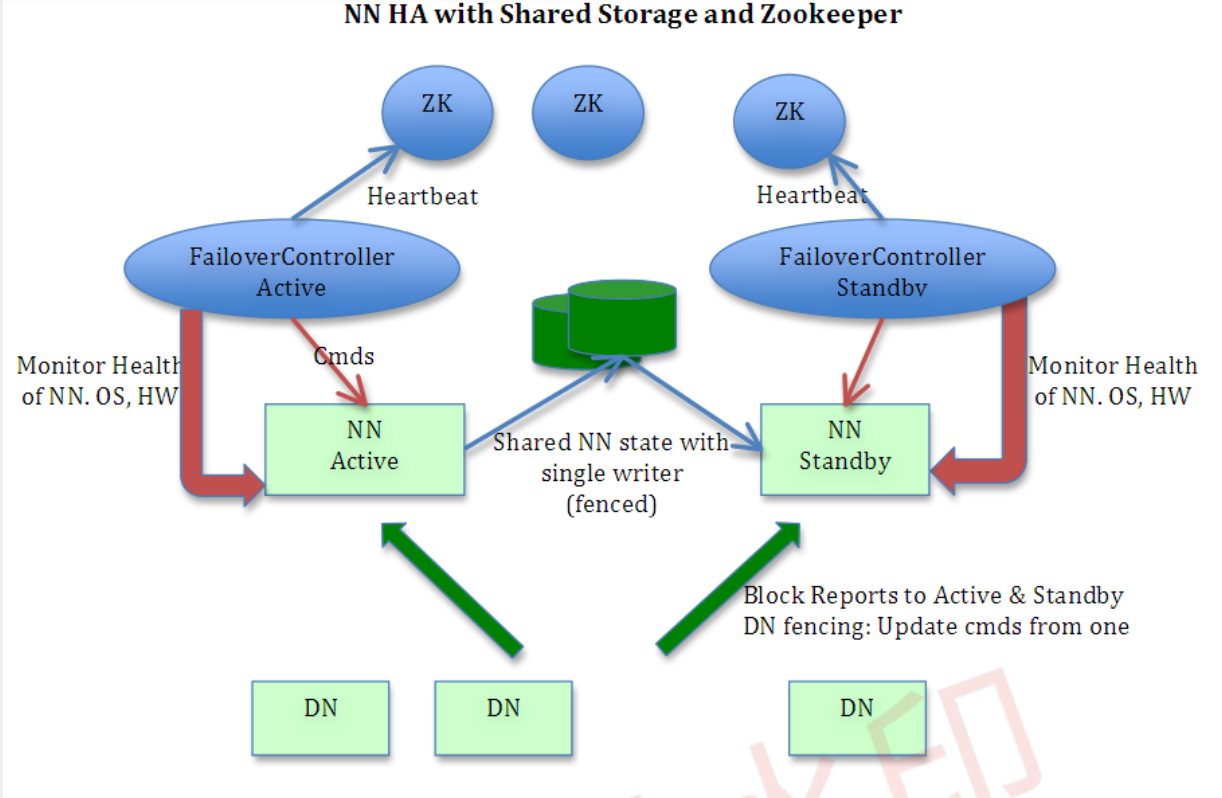
2)NameNode HA切换实现方法

zkfc提供以下功能:
Health monitoring
ZooKeeper session management
ZooKeeper-based election
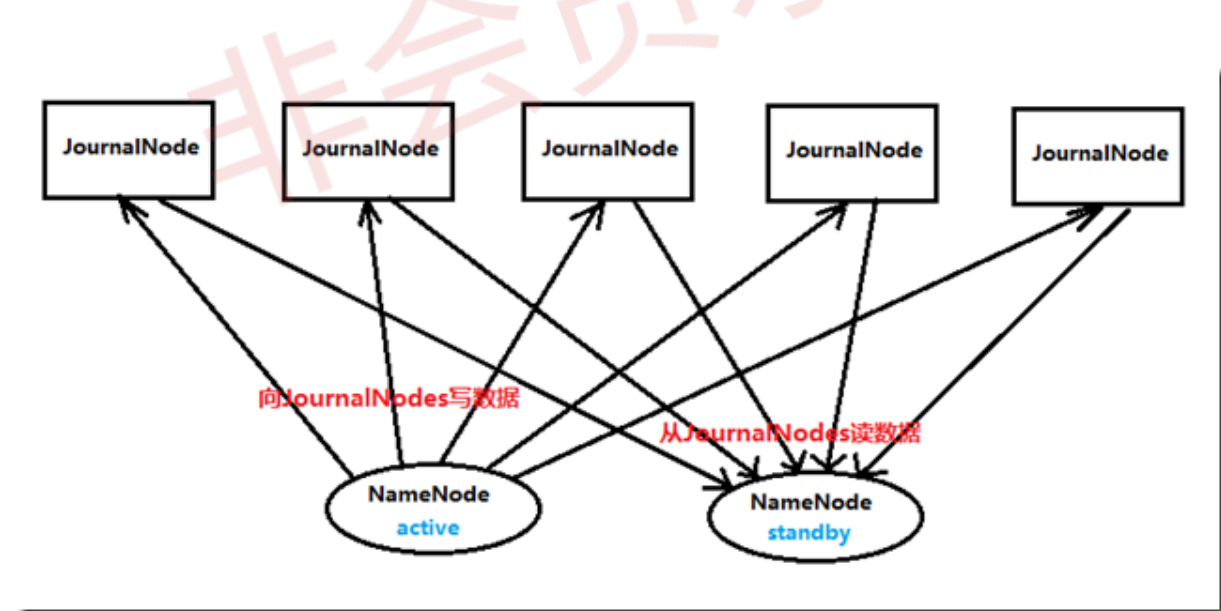
3)NameNode HA数据共享方法

实施
[root@localhost ~]#ntpdate time1.aliyun.com
[root@localhost ~]#vim /etc/hosts
192.168.208.5 hd1
192.168.208.10 hd2
192.168.208.20 hd3
192.168.208.30 hd4
192.168.208.40 hd5
192.168.208.50 hd6

[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl disable firewalld
[root@localhost ~]# sed -ri 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
[root@localhost ~]#firefox http://download.oracle.com
[root@localhost ~]#tar xf jdk-8u191-linux-x64.tar.gz -C /usr/local
[root@localhost ~]#mv /usr/local/jdk1.8 /usr/local/jdk
[root@localhost ~]#ssh-keygen -t rsa -f /root/.ssh/id_rsa -P ''
[root@localhost ~]#cd /root/.ssh
[root@localhost ~]#cp id_rsa.pub authorized_keys
[root@localhost ~]#for i in hd2 hd3 hd4 hd5 hd6;do scp -r /root/.ssh $i:/root;done
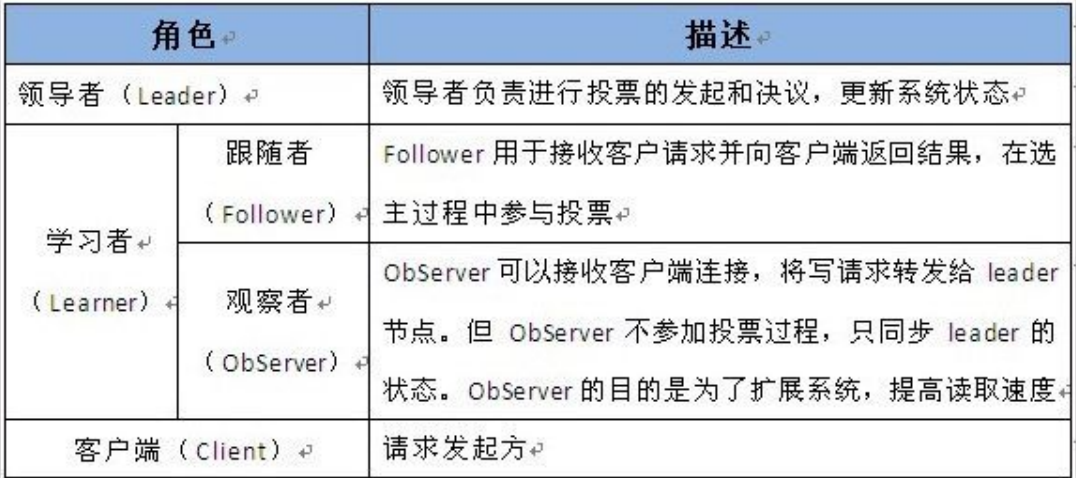
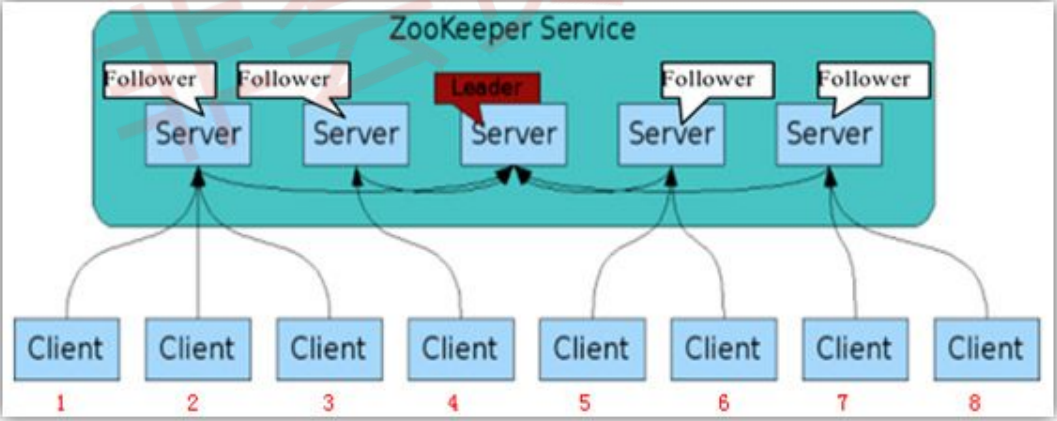
Leader主要有三个功能
Follower主要有四个功能
6.1)获取软件包
[root@localhost ~]#wget https://www-eu.apache.org/dist/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz
后三台部署zookeeper

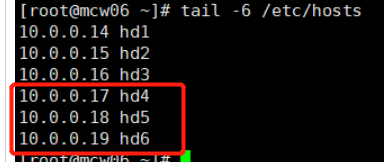
6.2)部署软件包
[root@localhost ~]#tar xf zookeeper-3.4.13.tar.gz -C /usr/local
[root@localhost ~]#mv /usr/local/zookeeper-3.4.13 /usr/local/zookeeper
[root@localhost ~]#mv /usr/local/zookeeper/conf/zoo.sample.cfg /usr/local/zookeeper/conf/zoo.cfg
[root@localhost ~]#vim /usr/local/zookeeper/conf/zoo.cfg
dataDir=/opt/data
[root@localhost ~]#mkdir /opt/data
[root@localhost ~]#echo 1 > /opt/data/myid

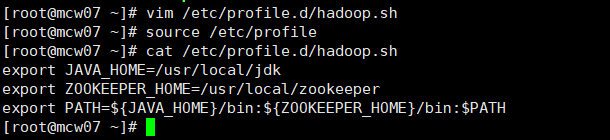
6.3)添加环境变量
[root@localhost ~]#vim /etc/profile.d/hadoop.sh
export JAVA_HOME=/usr/local/jdk
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=${JAVA_HOME}/bin:${ZOOKEEPER_HOME}/bin:$PATH
[root@localhost ~]# source /etc/profile
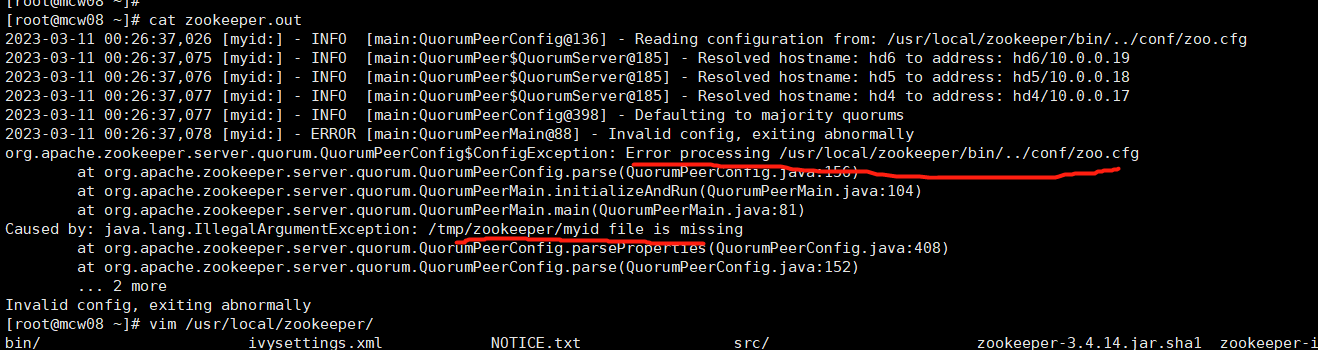
6.4)验证zookeeper
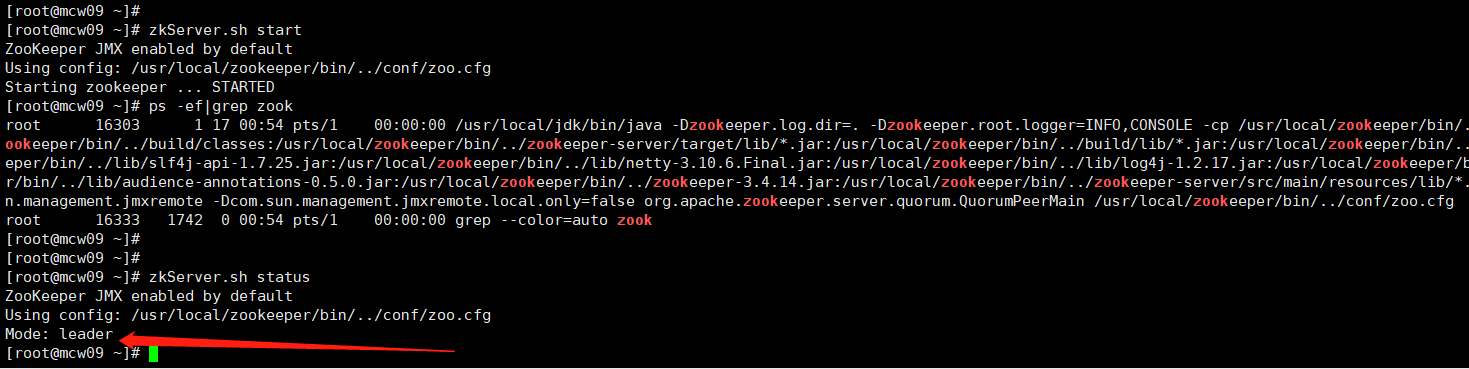
[root@localhost ~]#zkServer.sh start
[root@localhost ~]#zkServer.sh status
[root@localhost ~]#zkServer.sh stop
由下图可知,dataDir才是真的指定myid的目录的。可能是版本不同的原因吧
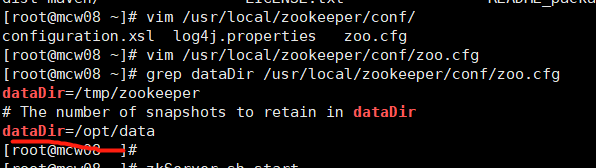
测试成功.myid不知道是否需要填写不同的值,还是都是1就可以
10.0.0.17 hd4 follower myid是1
10.0.0.18 hd5 follower myid是2
10.0.0.19 hd6 leader myid是3
7)hadoop软件包获取
[root@localhost ~]#wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
[root@localhost ~]#tar xf hadoop-2.8.5.tar.gz -C /opt
8)完全分布式(HA)配置文件修改
8.1)hadoop-env.sh
[root@localhost ~]#vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk

8.2)core-site.xml
/opt/data/tmp不存在,会自动创建
[root@localhost ~]#vim core-site.xml <!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property> <!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/tmp</value>
</property> <!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hd4:2181,hd5:2181,hd6:2181</value>
</property>
环境基本一致,所以不需要修改,直接复制上去

8.3)hdfs-site.xml
nameserver是ns1,ns1下有两个namenode:nn1,nn2;指定nn1和nn2的地址,元数据的存放位置等
[root@localhost ~]#vim hdfs-site.xml <!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property> <!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property> <!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>hd1:9000</value>
</property> <!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>hd1:50070</value>
</property> <!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>hd2:9000</value>
</property> <!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>hd2:50070</value>
</property> <!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hd4:8485;hd5:8485;hd6:8485/ns1</value>
</property> <!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/journal</value>
</property> <!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property> <!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property> <!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
8.4)配置datanode节点记录文件 slaves
[root@localhost ~]#vim slaves
hd4
hd5
hd6
8.5)mapred-site.xml
[root@localhost ~]#cp /opt/hadoop285/etc/hadoop/mapred-site.xml.template /opt/hadoop285/etc/hadoop/mapred-site.xml
[root@localhost ~]#vim mapred-site.xml
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
8.6)yarn-site.xml
[root@localhost ~]#vim yarn-site.xml
<!-- 指定resourcemanager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hd3</value>
</property>
<!-- 指定nodemanager启动时加载server的方式为shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>

9)复制修改后的hadoop目录到所有集群节点
[root@localhost ~]#scp -r hadoop hdX:/opt
[root@localhost ~]#scp /etc/profile.d/hadoop.sh hdX:/etc/profile.d/
[root@localhost ~]#source /etc/profile


10)在datanode节点(3台)启动zookeeper
[root@localhost ~]#zkServer.sh start
11)启动journalnode(在namenode上操作,例如hd1)
[root@localhost ~]#hadoop-daemons.sh start journalnode
[root@localhost ~]#jps
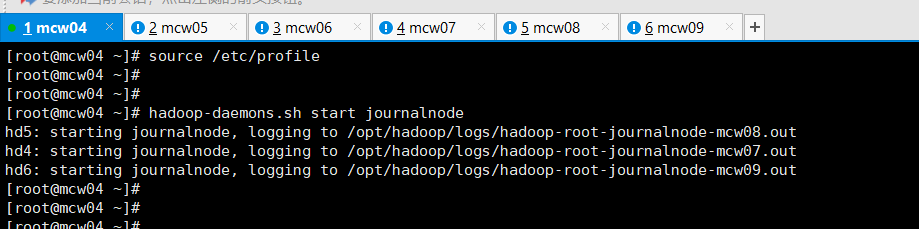
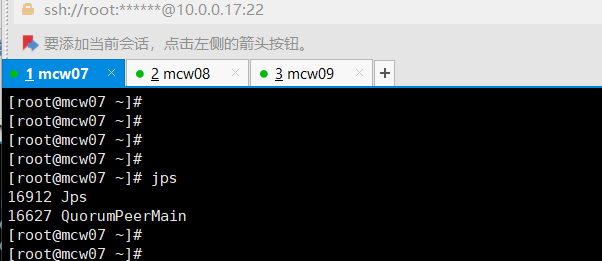
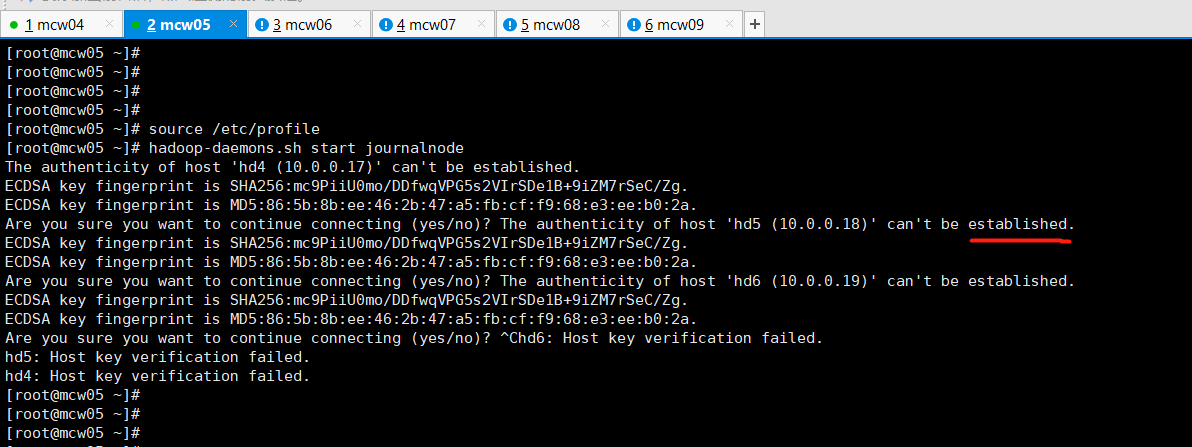
上面那个验证查看,没有启动成功的,上面是zk的。下面这个才是jn的
12)格式化hdfs文件系统(在namenode上操作,例如hd1)
[root@localhost ~]#hdfs namenode -format
失败了。报错了
格式化失败: [root@mcw04 ~]# hdfs namenode -format
23/03/11 10:13:01 INFO ipc.Client: Retrying connect to server: hd5/10.0.0.18:8485. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
23/03/11 10:13:01 INFO ipc.Client: Retrying connect to server: hd6/10.0.0.19:8485. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
23/03/11 10:13:01 INFO ipc.Client: Retrying connect to server: hd4/10.0.0.17:8485. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
23/03/11 10:13:02 INFO ipc.Client: Retrying connect to server: hd6/10.0.0.19:8485. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
23/03/11 10:13:10 WARN ipc.Client: Failed to connect to server: hd4/10.0.0.17:8485: retries get failed due to exceeded maximum allowed retries number: 10
java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) 去三个节点上查端口没有开启
[root@mcw08 ~]# ss -lntup|grep 8485
[root@mcw08 ~]# 查看配置,这个端口是那个服务
hdfs-site.xml: <!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hd4:8485;hd5:8485;hd6:8485/ns1</value>
</property> 停止这个服务,发现没有启动
[root@mcw04 ~]# hadoop-daemons.sh stop journalnode
hd6: no journalnode to stop
hd4: no journalnode to stop
hd5: no journalnode to stop
[root@mcw04 ~]# 在hd1上启动这个服务
[root@mcw04 ~]# hadoop-daemons.sh start journalnode
hd6: starting journalnode, logging to /opt/hadoop/logs/hadoop-root-journalnode-mcw09.out
hd5: starting journalnode, logging to /opt/hadoop/logs/hadoop-root-journalnode-mcw08.out
hd4: starting journalnode, logging to /opt/hadoop/logs/hadoop-root-journalnode-mcw07.out
[root@mcw04 ~]#
[root@mcw04 ~]# hadoop-daemons.sh start journalnode
hd4: journalnode running as process 17035. Stop it first.
hd6: journalnode running as process 16741. Stop it first.
hd5: journalnode running as process 17113. Stop it first.
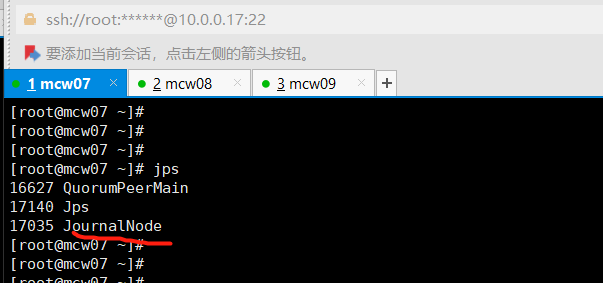
[root@mcw04 ~]# 在hd4-6的JournalNode节点上查看,服务已经启动
[root@mcw07 ~]# jps
16627 QuorumPeerMain
17140 Jps
17035 JournalNode
[root@mcw07 ~]# hd1这个namenode上格式化
[root@mcw04 ~]# hdfs namenode -format 将hd1格式化生成的目录传输到hd2,省去hd2格式化,两个namenode都有这个元数据了
[root@mcw04 ~]# ls /opt/data/
tmp
[root@mcw04 ~]# ls /opt/data/tmp/
dfs
[root@mcw04 ~]# ls /opt/data/tmp/dfs/
name
[root@mcw04 ~]# ls /opt/data/tmp/dfs/name/
current
[root@mcw04 ~]# ls /opt/data/tmp/dfs/name/current/
fsimage_0000000000000000000 fsimage_0000000000000000000.md5 seen_txid VERSION
[root@mcw04 ~]#
[root@mcw04 ~]# scp -rp /opt/data hd2:/opt/
VERSION 100% 212 122.4KB/s 00:00
seen_txid 100% 2 3.1KB/s 00:00
fsimage_0000000000000000000.md5 100% 62 100.4KB/s 00:00
fsimage_0000000000000000000 100% 321 728.1KB/s 00:00
[root@mcw04 ~]#
13)格式化zk(namenode上操作,例如hd1)
[root@localhost ~]#hdfs zkfc -formatZK

14)启动hdfs(namenode上操作,例如hd1)
[root@localhost ~]#start-dfs.sh
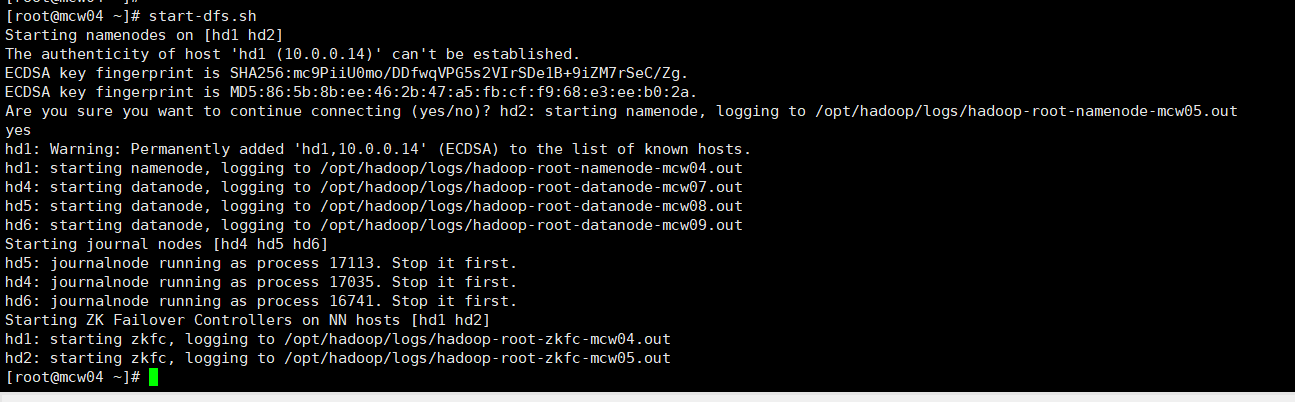
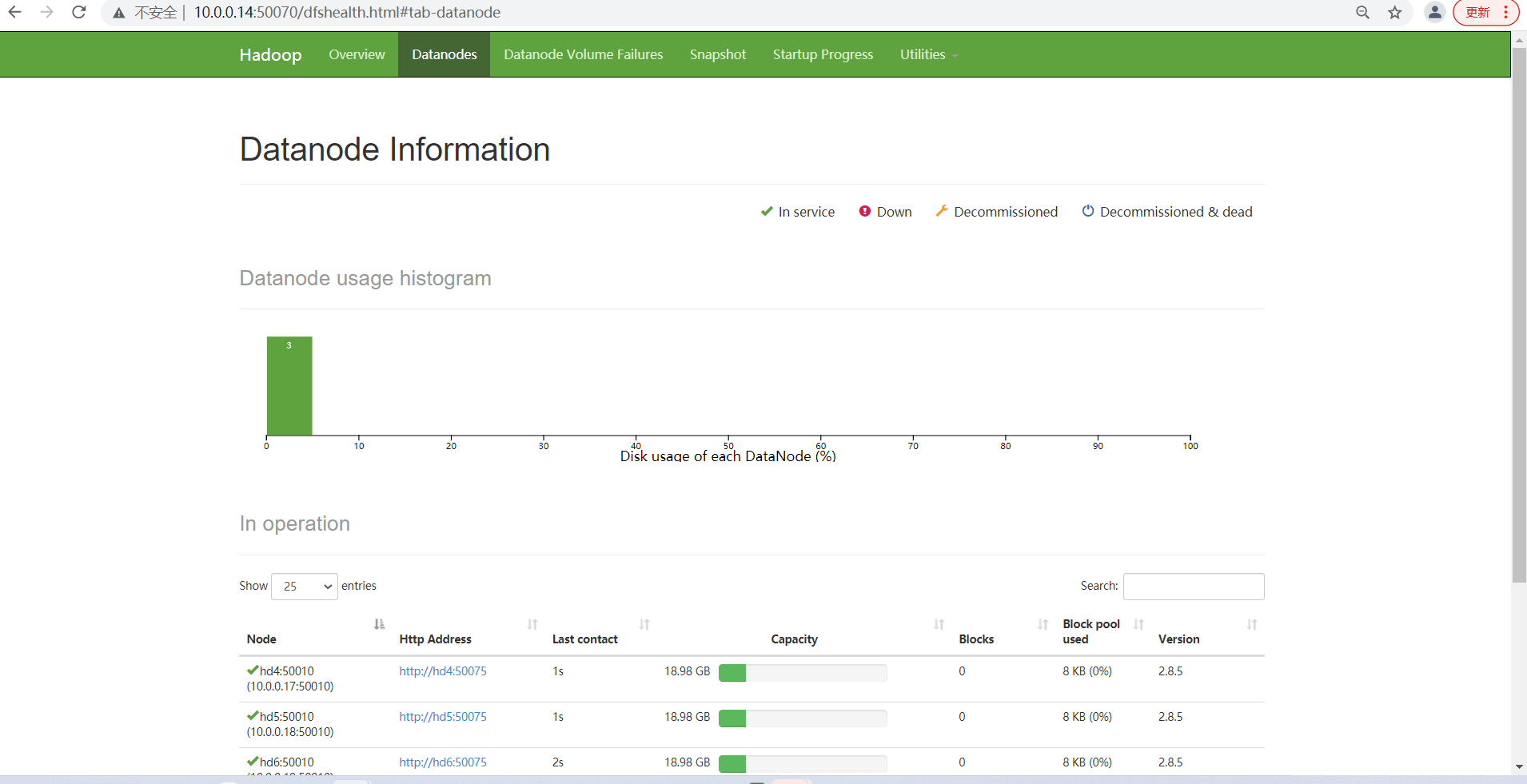
查看各个节点服务启动情况

15)启动yarn(namenode上操作,例如想让hd2成为resourcemanager,需要在hd2上启动。)
[root@localhost ~]#start-yarn.sh

16)访问
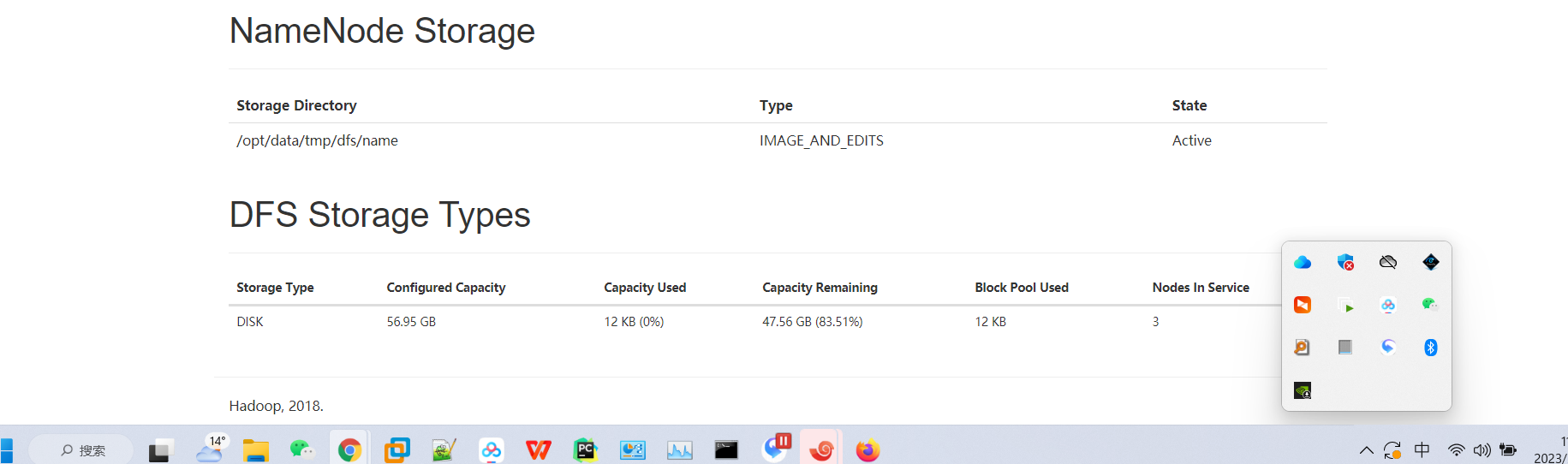
NameNode1:http://hd1:50070 查看NameNode状态
NameNode2:http://hd2:50070 查看NameNode状态
NameNode3:http://hd3:8088 查看yarn状态
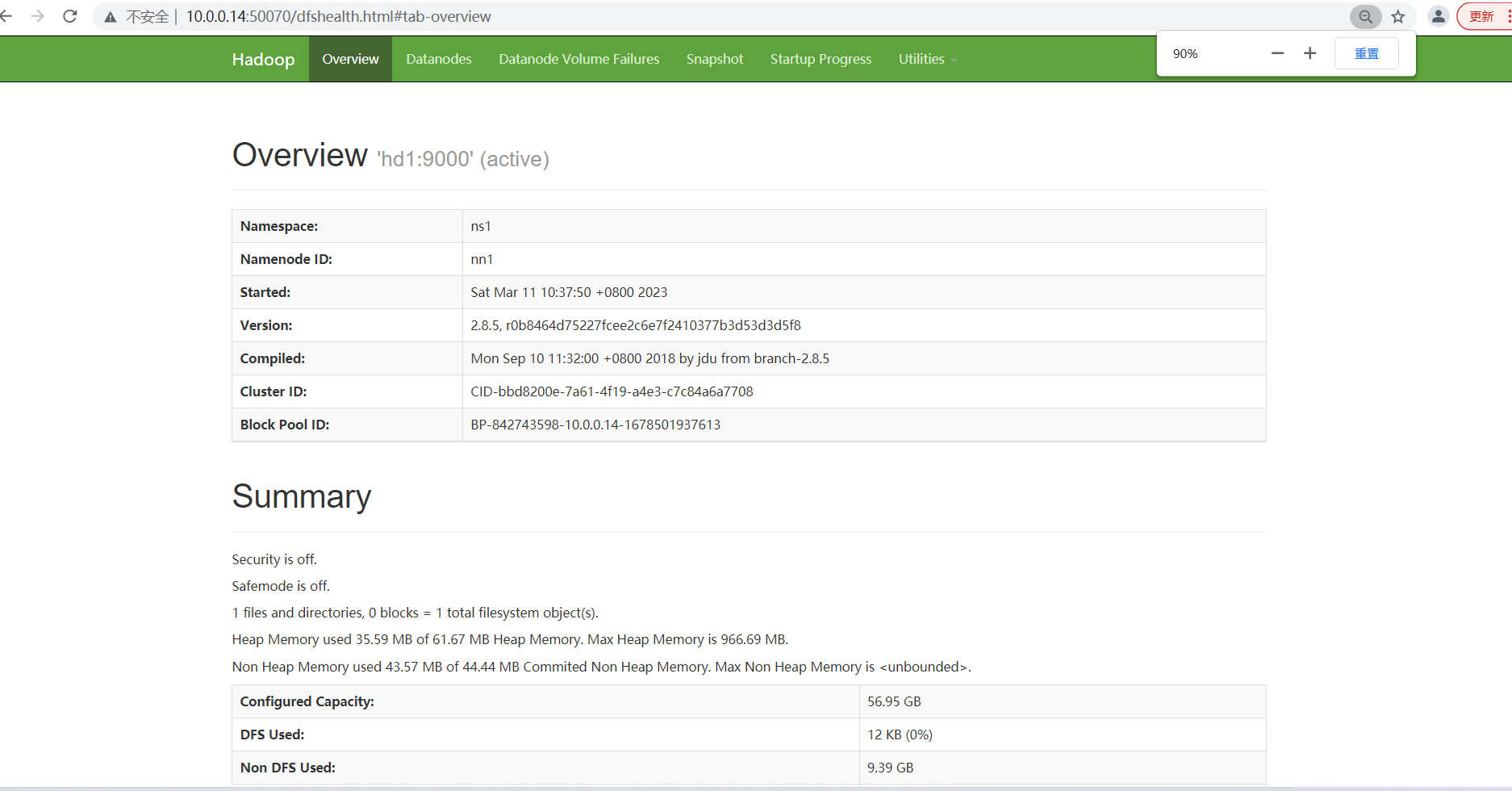

第三个页面访问失败。hd1上启动的yarn,但是ResourceManager没有启动
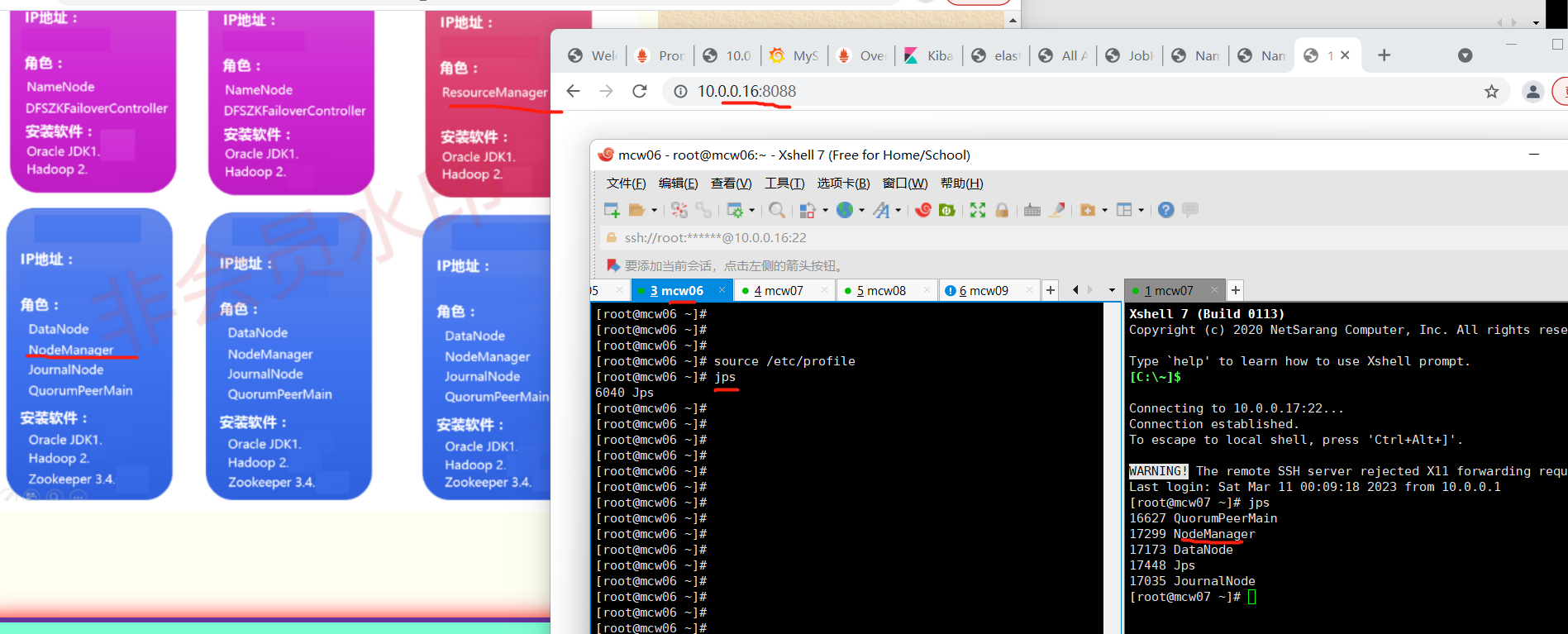
之前在hd1上执行开启yarn,但是ResourceManager没有启动,在hd1上先停止。然后在hd3也就是主机6上开启,然后就成功开启了但是ResourceManager和NodeManager。我们之前规划的就是主机6作为ResourceManager,因此,我们配置里面应该是也有体现的吧。
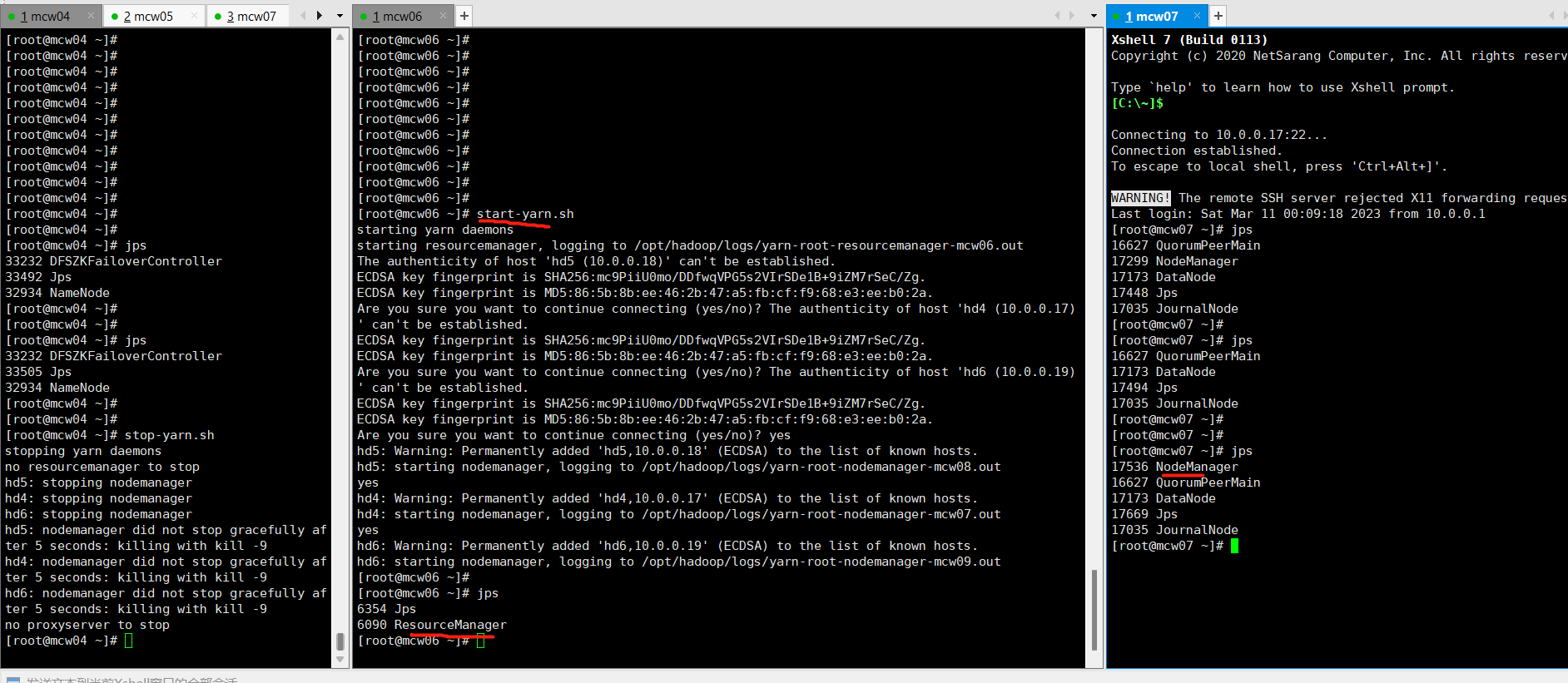
再次访问,可以看到已经成功访问了

页面查看

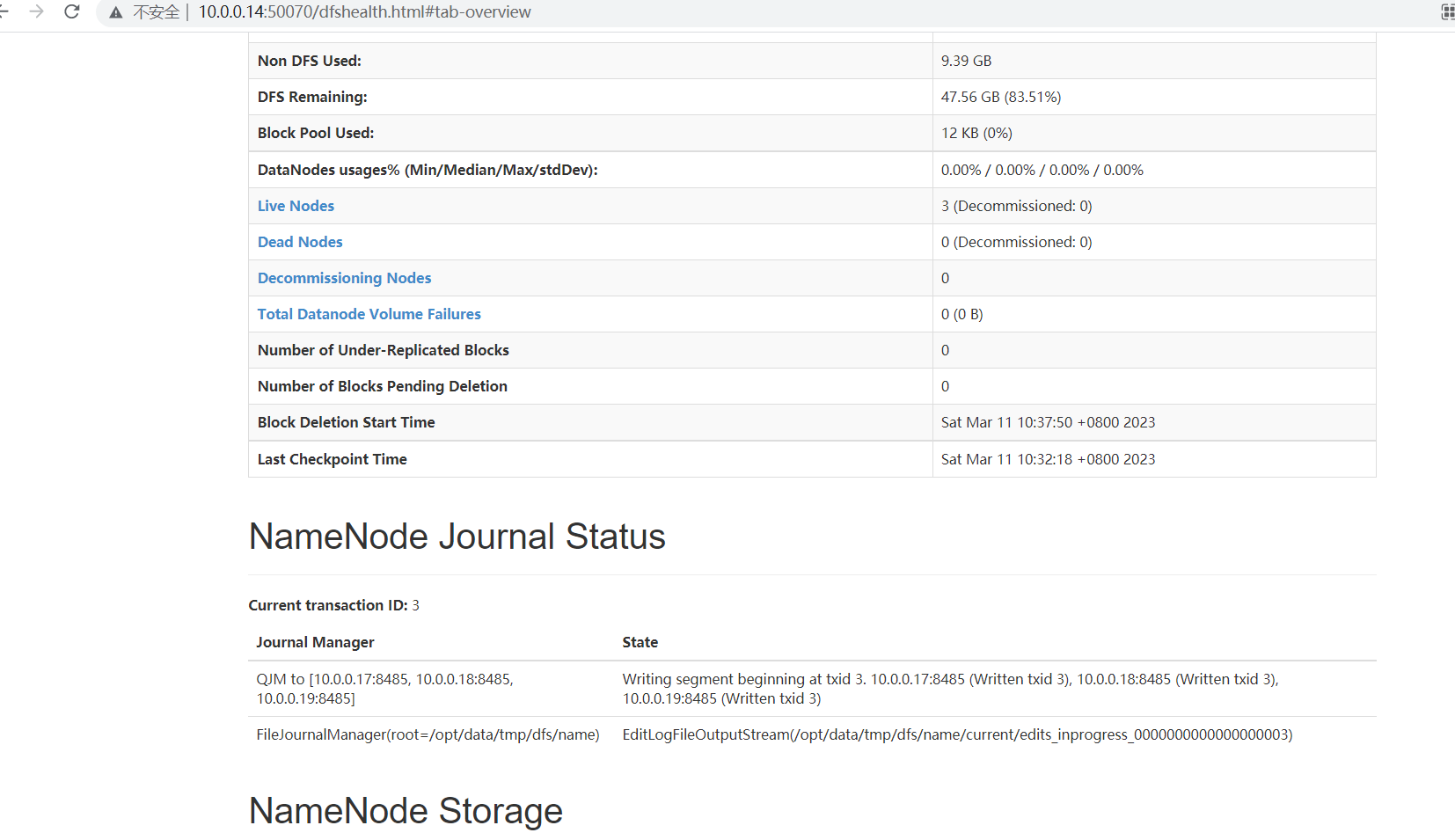
=====

点击链接的时候,是我笔记本上,没法解析。只能给自己笔记本添加一下解析才能访问了

===

===

====
=======
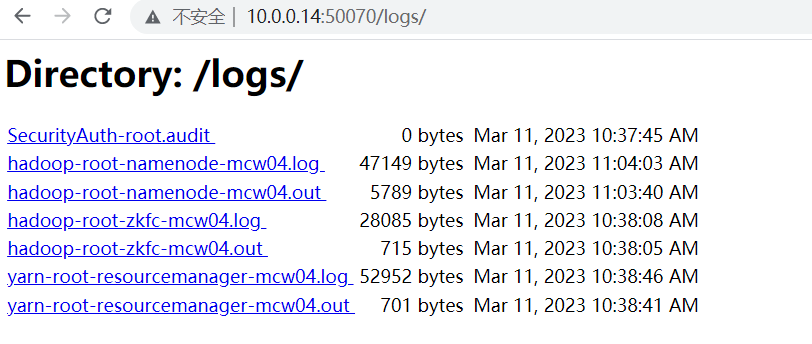
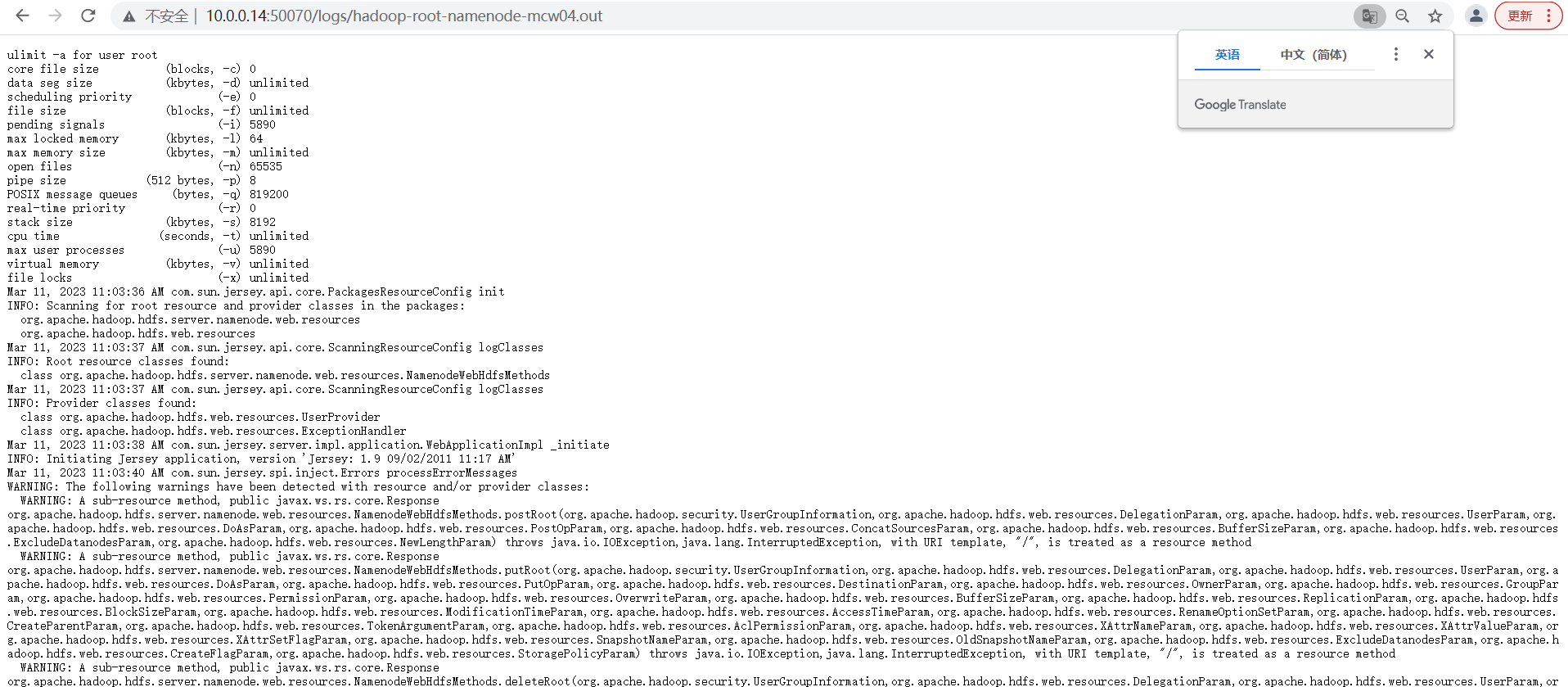
检测使用
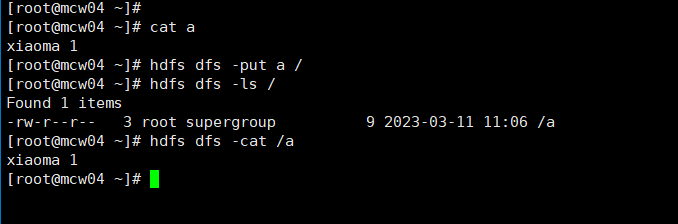



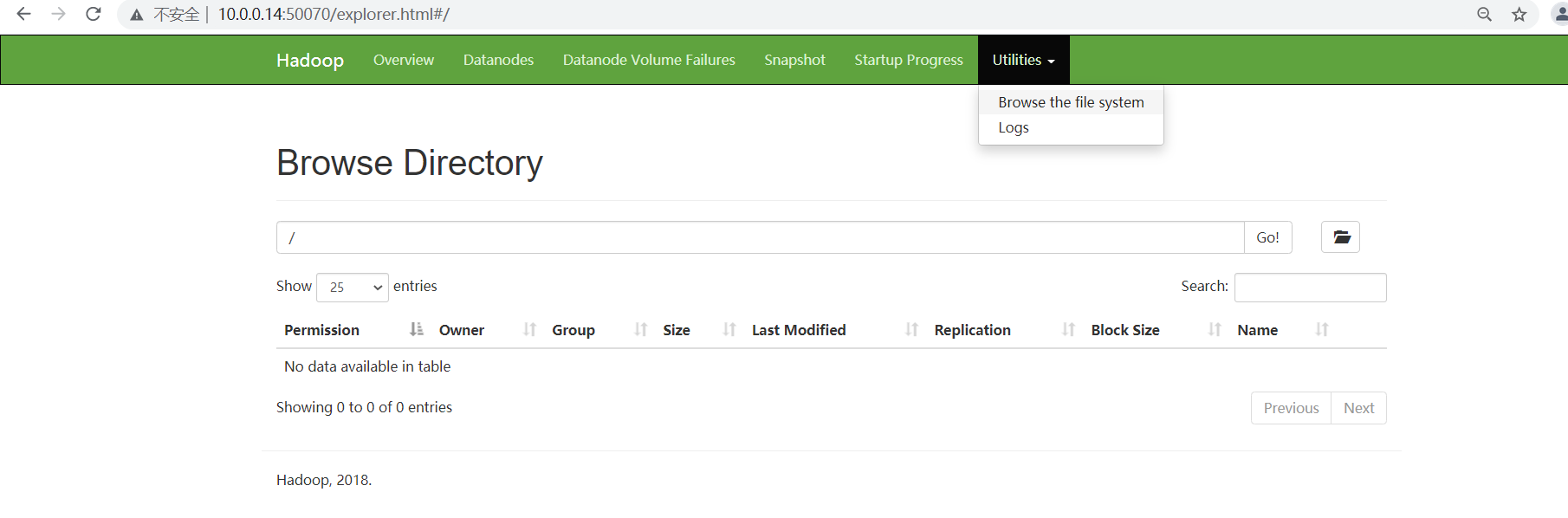
创建文件夹


从这里创建失败,没有权限。可以去使用命令行创建。

总结
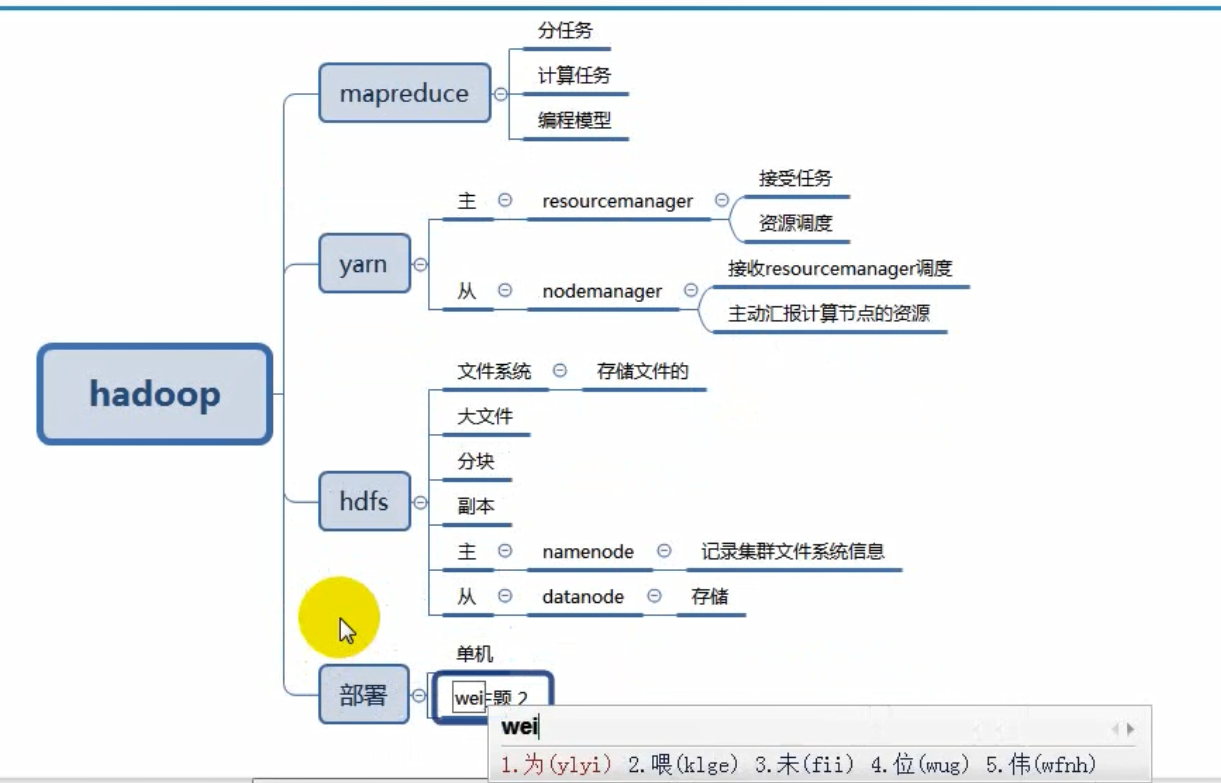

hadoop大数据统计中的应用思路
日志本身输出是json,然后用flink解析json,变成table。,hadoop是存储层,你可以理解原始日志是ODS层,把原始数据发送到kafka,然后用flink去处理kafka的日志,写到hadoop,
.theme.i hot air balloon 98d92063a6。 你是读取Hadoop多个日志文件,然后根据逗号切割,将第一列数据分组统计每个出现的个数么,类似于这样?
一般来说 数据链路就是
原始日志>kakfa>程序解析>原始日志存储到hdfs
然后基于hdfs的数据计算后 > 落库hdfs > 同步mysql/gp 做报表展示
程序解析这里是flink。 sparkstreaming
大致的意思可能是:
程序解析后存储到hdfs,然后用Hadoop的计算功能统计结果,把统计结果写入到hdfs,然后程序从hdfs读取统计结果中需要的字段(可能不是所有字段数据)写入到数据库。有的时候,这个统计结果,可能会同步到多个数据库,给不同的平台使用吧
json 日志处理后:这样

hadoop部署2的更多相关文章
- hadoop部署小结的命令
hadoop部署总结的命令 学习笔记,转自:hadoop部署总结的命令http://www.aboutyun.com/thread-5385-1-1.html(出处: about云开发)
- Hadoop 部署文档
Hadoop 部署文档 1 先决条件 2 下载二进制文件 3 修改配置文件 3.1 core-site.xml 3.2 hdfs-site.xml 3.3 mapred-site.xml 3.4 ya ...
- hadoop进阶----hadoop经验(一)-----生产环境hadoop部署在超大内存服务器的虚拟机集群上vs几个内存较小的物理机
生产环境 hadoop部署在超大内存服务器的虚拟机集群上 好 还是 几个内存较小的物理机上好? 虚拟机集群优点 虚拟化会带来一些其他方面的功能. 资源隔离.有些集群是专用的,比如给你三台设备只跑一个 ...
- Hadoop部署方式-完全分布式(Fully-Distributed Mode)
Hadoop部署方式-完全分布式(Fully-Distributed Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本博客搭建的虚拟机是伪分布式环境(https://w ...
- Hadoop部署方式-伪分布式(Pseudo-Distributed Mode)
Hadoop部署方式-伪分布式(Pseudo-Distributed Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载相应的jdk和Hadoop安装包 JDK:h ...
- Hadoop部署方式-本地模式(Local (Standalone) Mode)
Hadoop部署方式-本地模式(Local (Standalone) Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Hadoop总共有三种运行方式.本地模式(Local ...
- hadoop部署中遇到ssh设置的问题
尽管hadoop和一些培训视频课程上讲分布式部署比较详细,但是在部署时仍遇到了一些小问题,在此mark一下: 1.linux的namenode主机上安装了ssh,也启动了ssh,并且执行了: /etc ...
- hadoop部署工具与配置工具
https://github.com/xianglei/phpHiveAdmin 随着Hadoop的推出,大数据处理实现了技术上的落地.但是对于一般的公司和开发者而言,Hadoop依旧是一个陌生或者难 ...
- hadoop部署、启动全套过程
Hadoop是Apache基金会的开源项目,为开发者提供了一个分布式系统的基础架构,用户可以在不了解分布式系统的底层细节的情况下开发分布式的应用,充分利用集群的强大功能,实现高速运算和存储.Hadoo ...
- hadoop部署错误
hadoop的单机部署很简单也不容易出错,但是对生产环境的价值和意义不大,但是可以快速用于开发. 部署hadoop的错误原因不少,并且很奇怪. 比如,用户名不同,造成客户端和服务器通讯产生认证失败的错 ...
随机推荐
- Docker学习路线9:运行容器
要启动一个新的容器,我们使用 docker run 命令,后跟镜像名称.基本语法如下: docker run [选项] 镜像 [COMMAND] [ARG...] 例如,要运行官方的 Nginx 镜像 ...
- C# 窗口停靠隐藏类
引用:https://www.cnblogs.com/lidj/archive/2012/07/06/2579923.html 最近修改了一下.可以更方便的用在各个窗体上了 代码也简洁很多.直接引用一 ...
- C# DevExpress下GridControl控件的增删查改
DevExpress的GridControl控件可以从任何数据源绑定数据并进行增删查改等操作,和VS自带的dataGridView控件对比,GridControl控件可以实现更多自定义的功能,界面UI ...
- Makefile编写模板 & 学习笔记
一.模板 # 伪命令 .PHONY: clean compileSo compileExe run: compileExe @./main compileExe: compileSo @g++ mai ...
- 动态库 DLL 封装一:dll分类
动态库分为三种: Non-MFC-DLL(非MFC动态库): 非MFC动态库不采用MFC类库结构,其带出函数为标准C接口,能被非MFC或MFC编写的应用程序所调用 MFC Regular DLL( ...
- HarmonyOS音频开发指导:使用AudioRenderer开发音频播放功能
AudioRenderer是音频渲染器,用于播放PCM(Pulse Code Modulation)音频数据,相比AVPlayer而言,可以在输入前添加数据预处理,更适合有音频开发经验的开发者,以 ...
- github 小技巧
前言 简单记一下github 小技巧,因为经常忘. 正文 就是如何快速搜索到自己想找的项目. 如果自己知道项目名,那么直接输入就可以搜索到. 如果不是,那么一般要通过高级搜索. https://git ...
- SpringCloud做的微服务项目--外卖订餐系统
本项目用到的组件技术可以参考我上一篇博客,来学习. 项目需求: 客户端:针对普通用户,用户登录,用户退出,菜品订购,我的订单 后台管理系统:针对管理员,管理员登录,管理员退出,添加菜品,查询菜品,修改 ...
- json文件读取并转换成为字典python
# JSON到字典转化 f2 = open('info.json', 'r') info_data = json.load(f2) print(info_data) # 显示数据类型 print(ty ...
- 4款值得推荐的AI辅助编程工具(支持C#语言)
前言 在这个AI迅速发展的阶段,涌现出了一大批好用的AI辅助编程工具.AI辅助编程工具能够提高开发效率.改善代码质量.降低bug率,是现代软件开发过程中的重要助手.今天大姚给大家分享4款AI辅助编程工 ...