9个SQL运维常遇到的问题
摘要:本文重点介绍单个SQL语句持续执行慢的场景。
本文分享自华为云社区《GaussDB(DWS) SQL性能问题案例集》,作者:黎明的风。
本文重点介绍单个SQL语句持续执行慢的场景。我们可以对执行慢的SQL进行单独分析,SELECT、INSERT、UPDATE等语句都可以使用explain verbose + SQL语句输出查询计划来进行分析,这样只输出查询计划,语句不会被实际的执行。
如果查询计划只出现__REMOTE_FQS_QUERY__或__REMOTE_LIGHT_QUERY__,看不到具体的计划,可以先执行set enable_fast_query_shipping to off; 然后再重新打印执行计划。
经常遇到的问题有以下几个:
【案例1】语句中包含不下推的函数
检查查询计划中是否包含_REMOTE_TABLE_QUERY_关键字, 如果有则表示语句没有下推,数据需要从DN上收取到CN上,然后语句在CN上执行。语句不下推原因,要从CN的日志中查找,搜索的关键字为:SQL can’t be shipped,以下为函数造成的不下推例子:
LOG: SQL can't be shipped, reason: Function Fun1() can not be shipped
此外如果出现以下几种不下推的关键字:__REMOTE_GROUP_QUERY__、__REMOTE_LIMIT_QUERY__、
__REMOTE_SORT_QUERY__。这种需要检查enable_stream_operator参数是否处于关闭状态,一般来说打开STREAM开关后,语句就可以下推执行了。
如果出现以下两种关键字,表示语句可以下推执行:
__REMOTE_FQS_QUERY__:表明语句走了Fast Query Shipping(FQS),SQL语句会下发到DN上执行,并且各DN之间没有数据交互,常见的场景有过滤条件为等值查询(where id = 1),或者关联的列是表的分布列的查询(where t1.id = t2.id)。
__REMOTE_LIGHT_QUERY__:表明语句走了Light Proxy(CN轻量化),将语句下发给了单个DN去处理,常见的场景过滤条件是分布列的等值查询(where id = 1),或者向一个DN插入数据的INSERT语句。
【案例2】表上有索引但没有走索引扫描,进行了全表扫描
从查询计划中可以看到Seq Scan或CStore Scan这样的关键字,如下所示:
对于行存表:-> Seq Scan on t1
对于列存表:-> CStore Scan on col_t1
出现这种问题通常有以下几种情况:
没有对所查询的表收集统计信息
如果表的实际行数很大,而估算行数很小,查询时可能会走全表顺序扫描,造成执行速度慢。此时通过analyze表更新统计信息,让优化器选择最佳的查询计划,一般就可以解决执行慢的问题。
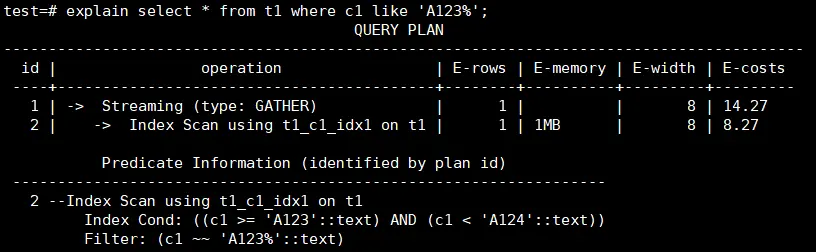
【案例3】模糊匹配没有走索引
后模糊匹配查询可以通过建立一个BTREE索引来实现,需要根据数据类型设置索引的operator,对于text,varchar和char分别设置和text_pattern_ops,varchar_pattern_ops和bpchar_pattern_ops。
例如c1列的类型为text,创建索引时增加text_pattern_ops。
CREATE INDEX ON t1 (c1 text_pattern_ops);
创建索引后,可以看到语句执行时会使用到前面创建的索引,执行速度会变快。
【案例4】创建索引时所指定列的顺序问题
多列复合索引的组织结构与单列字段索引结构类似,按索引内表达式指定的顺序编排。当创建多列复合索引时,选择什么样的列的顺序,对查询性能会带来一定的影响。
例如按照c_date,c1和c2列的顺序建立检索,如果符合c_date条件的数据很多,通过这个索引扫描的数据就很会很多,造成执行时间长。

新建多列复合索引,将查询条件里的等值条件的列放到索引列的前面,先使用等值进行过滤,需要扫描的数据变少,查询变快。

【案例5】分区表没有分区剪枝进行了全表扫描
问题背景:XSYX局点使用MERGE INTO语句将每天的数据入库到表里,目标表为分区表,业务上线运行一段时间后发现MERGE INTO速度逐渐变慢。
原因分析:MERGE INTO语句的源表和目标表都是分区表,当前仅对源表增加了时间的过滤条件,可以进行分区剪枝。目标表由于没有指定时间过滤条件,进行的是全表扫描,随着每日的入库业务运行,目标表的数据量越来越大,造成执行速度越来越慢。
解决方案:由于源表的数据在MERGE INTO时会导入到目标表的对应分区里,可以对目标表增加时间的过滤条件进行分区剪枝。
业务修改前的查询计划:
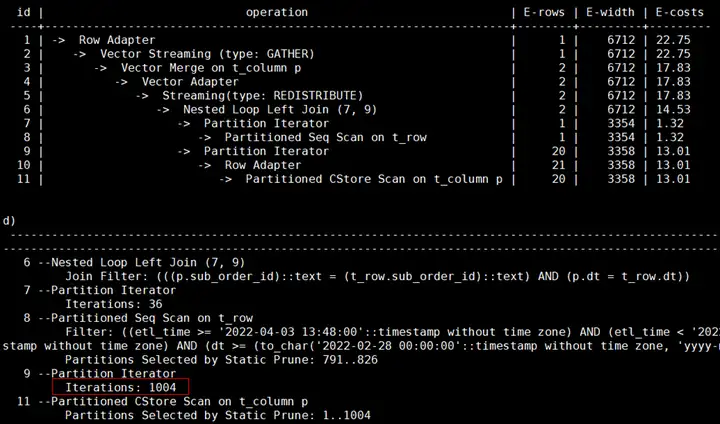
对目标表增加了时间过滤条件后的计划显示可以走分区剪枝:

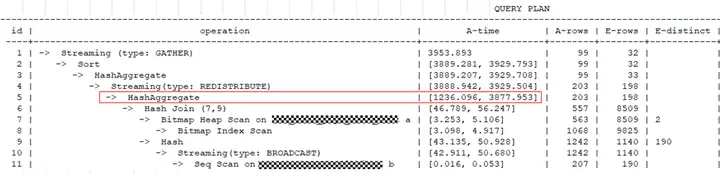
【案例6】表数据在DN节点上有存储倾斜
从查询计划中的A-time可以看到最长和最短的执行时间相差很大,说明在不同DN上扫描数据的时间不同。

在查询计划的DN信息中,通过rows可以看出在datanode1上扫描的数据量明显多于datanode2,说明有存储倾斜,这种情况建议对表进行合理的设计,选择合适的分布列,将数据均匀分布到所有的DN上。

【案例7】自定义函数引起执行慢
问题现象:查询语句比较简单,两个表做关联后输出了其中一列的值,在输出前增加了一个自定义函数对数据进行了处理。
原因分析:自定义函数里逻辑相对复杂,包含了对表的查询及数据计算逻辑,造成执行变慢。
解决方案;业务上对自定义函数进行性能优化。
【案例8】查询视图执行时间长
问题现象:某YD局点从C80版本迁移数据到8.1.1版本后,查询PG_STAT_USER_TABLES视图的时间由几分钟变成半个小时都不出结果。
原因分析:8.1.1版本中的PG_STAT_USER_TABLES视图在获取插入、更新、删除的行数的字段数值时,每一条记录都涉及到CN和DN的交互,在数据量和集群规模大的情况下耗时较多。
解决方案:建议根据应用的实际需要,将视图定义中不需要的函数注释掉以提升查询效率。
【案例9】关闭indexscan和bitmapscan后可以使用并行提升性能
问题现象: 查询计划中显示走了Index Scan,通过索引查询出的数据量比较大,速度慢。
原因分析:由于使用索引扫描时无法使用并行查询,当索引访问的数据量大时执行速度较慢。
解决方案:将enable_indexscan和enable_bitmapscan参数关闭,设置query_dop后走并行查询。
9个SQL运维常遇到的问题的更多相关文章
- 聊聊数据库~5.SQL运维上篇
1.6.SQL运维篇 运维这块逆天只能说够用,并不能说擅长,所以这篇就当抛砖之用,欢迎补充和纠错 PS:再说明下CentOS优化策略这部分的内容来源:首先这块逆天不是很擅长,所以主要是参考网上的DBA ...
- 聊聊数据库~6.SQL运维中篇
上篇回顾:https://www.cnblogs.com/dotnetcrazy/p/10810798.html#top 1.6.5.MySQL日志相关 本文的测试环境:MySQL5.7.26.Mar ...
- SQL运维
1.碎片扫描 dbcc showconfig('table_name')
- SQL Server 自动化运维系列
本系列为SQL SERVER自动化运维的一些操作技巧点,所有内容都是根据日常运维过程中最经常遇到的问题,并为此形成了一些自动化运维的方式,皆为原创.... 供部分DBA和开发人员浏览借鉴,所应用平台基 ...
- 1、SQL Server自动化运维 - 备份(一)业务数据库
为了能够恢复数据,数据库运维基础就是备份,备份自动化也是运维自动化首要进行的. 笔者的备份自动化,通过配置表快速配置为前提,同时记录备份过程,尽可能的减少人工操作.首先将SQL Server备份按用途 ...
- 从运维的角度分析使用阿里云数据库RDS的必要性--你不应该在阿里云上使用自建的MySQL/SQL Server/Oracle/PostgreSQL数据库
开宗明义,你不应该在阿里云上使用自建的MySQL or SQL Server数据库,对了,还有Oracle or PostgreSQL数据库. 云数据库 RDS(Relational Database ...
- 亿级SQL Server运维的最佳实践PPT分享
这次分享是我在微软的一次分享,关于SQL Server运维最佳实践的部分,由于受众来自不同背景,因此我让分享在一个更加抽象的角度进行,PPT分享如下: 点击这里进行下载
- 从一个简单的约束看规范性的SQL脚本对数据库运维的影响
之前提到了约束的一些特点,看起来也没什么大不了的问题,http://www.cnblogs.com/wy123/p/7350265.html以下以实际生产运维中遇到的一个问题来说明规范的重要性. 如下 ...
- sql server 运维时CPU,内存,操作系统等信息查询(用sql语句)
我们只要用到数据库,一般会遇到数据库运维方面的事情,需要我们寻找原因,有很多是关乎处理器(CPU).内存(Memory).磁盘(Disk)以及操作系统的,这时我们就需要查询他们的一些设置和内容,下面讲 ...
- 【自动化】基于Spark streaming的SQL服务实时自动化运维
设计背景 spark thriftserver目前线上有10个实例,以往通过监控端口存活的方式很不准确,当出故障时进程不退出情况很多,而手动去查看日志再重启处理服务这个过程很低效,故设计利用Spark ...
随机推荐
- 【Azure Logic App】在Azure Logic App中使用SMTP发送邮件示例
问题描述 在Azure Logic App的官网介绍中,使用SMTP组件发送邮件非常简单(https://docs.azure.cn/zh-cn/connectors/connectors-creat ...
- Go命令大全:全面解析与实践
本文详尽地探讨了Go语言的内建命令集,包括但不限于go build.go run.go get等.文章首先列举了所有常用的Go命令,并用表格形式简洁地解释了它们的功能.随后,我们逐一深入讲解了每个命令 ...
- Newbie_calculations
拿到这道题是个应用程序,经过上次的经验就跟程序交互了一下,结果根本交互不了,输入什么东西都没有反应 然后打开ida分析发现有几个函数还有一堆的操作数,看到这一堆东西就没心思分析了,后面才知道原来就是要 ...
- Istio:微服务开发的终极利器,你还在为繁琐的通信和部署流程烦恼吗?
引言 在前面的讲解中,我们已经提及了微服务的一些弊端,并介绍了Istio这样的解决方案.那么,对于我们开发人员来说,Istio究竟会带来哪些变革呢?今天我们就来简要探讨一下! Kubernetes简单 ...
- C/C++ 常用加密与解密算法
计算机安全和数据隐私是现代应用程序设计中至关重要的方面.为了确保数据的机密性和完整性,常常需要使用加密和解密算法.C++是一种广泛使用的编程语言,提供了许多加密和解密算法的实现.本文将介绍一些在C++ ...
- 数据结构(C语言版 第2版)课后习题答案全集 严蔚敏
有的小伙伴在网上奋力的找 严蔚敏版 第2版 数据结构 的始终无果,那么我这里就整理好,放在同名公众号中了,也可扫文章末尾的二维码直达公众号,回复数据结构的关键词即可拿到.
- vue + node 前后端分离项目解决跨域问题
vue + node 前后端分离项目解决跨域问题 由于前端 和 后端 项目运行于不同端口,无法直接传递数据 后端 app.js 添加如下代码 var cors = require('cors') ap ...
- java-导出pdf
前言: 纯代码画pdf格式 <!-- iText PDF --> <dependency> <groupId>com.itextpdf</groupId& ...
- [ABC327G] Many Good Tuple Problems
题目链接 简化题意:有一个 \(n\) 个点的图,问有多少个长度为 \(M\) 的边序列,满足连边后图是二分图. \(n\le 30,m\le 10^9\) 考虑先强制要求无重边. 定义 \(f_{i ...
- A Novel Cascade Binary Tagging Framework for Relational Triple Extraction(论文研读与复现)
A Novel Cascade Binary Tagging Framework for Relational Triple Extraction Zhepei Wei,Jianlin Su, Yue ...