带你认识图数据库性能和场景测试利器LDBC SNB
摘要:本文主要介绍基于交互式查询所用的数据生成器(下文简称Datagen),及LDBC SNB数据如何在华为图引擎服务GES中应用。
本文分享自华为云社区《【图数据库性能和场景测试利器LDBC SNB】系列一:数据生成器简介 & 应用于GES服务》,作者:闹闹与球球
本文的主要内容包括:基于交互式查询所用的数据生成器(下文简称Datagen)介绍,及LDBC SNB数据如何在华为图引擎服务GES中应用。LDBC SNB所预设的节点和关系、数据生成器和系统的测试用例,形成了一个逻辑自恰的数据“武林”,以ldbc snb为测试标准的图数据库产品,就像是行走于其中的侠客们,都得遵循同一套“武林规矩”(测试用例),究竟谁能击败各方高手,问鼎盟主呢?
LDBC SNB概述
LDBC SNB,全称The Linked Data Benchmark Council’s Social Network Benchmark,官网地址:http://ldbcouncil.org。LDBC是一个致力于发展图数据管理的产业联盟组织,它开发了一套标准的benchmarks,用于系统地衡量不同图数据库产品的功能和性能。SNB是基于社交网络场景开发的一组benchmarks,由交互式场景(Interactive workload)和商业智能场景(Business Intelligence workload)组成。
LDBC SNB 项目包括3个组件:数据生成器(Datagen)、测试驱动程序(Test Driver,用于执行Benchmark的测试)和测试用例实现(Reference Implementation,目前提供了基于Cypher(Neo4j)和SQL(PostgreSQL)两种查询语言的测试用例实现)
LDBC SNB有两种工作模式:
1、交互式查询(Interactive workload),适用于事务性的在线查询场景,比如基础的增删改查、shortestpath、多跳等;
2、商业智能 (Business Intelligence workload),适用于根据企业业务场景制定的复杂查询和大规模离线图分析等场景。
在不同的工作模式下,【Datagen】、【Test Driver】 和【测试用例实现】都是不同的。
章节概览
一、Datagen介绍
- 数据模型
- Data Types
- Data Schema
- Datagen的安装和运行流程
- Datagen的参数设置
- 常规参数设置
- 规模因子
- 序列化模式
二、LDBC SNB在GES中的应用
一、Datagen介绍
数据模型
Data Types
Datagen支持的属性datatype如下, 每种属性都支持单值和列表两种模式。

(截图来源于官方文档http://ldbcouncil.org/ldbc_snb_docs/ldbc-snb-specification.pdf)
Data Schema
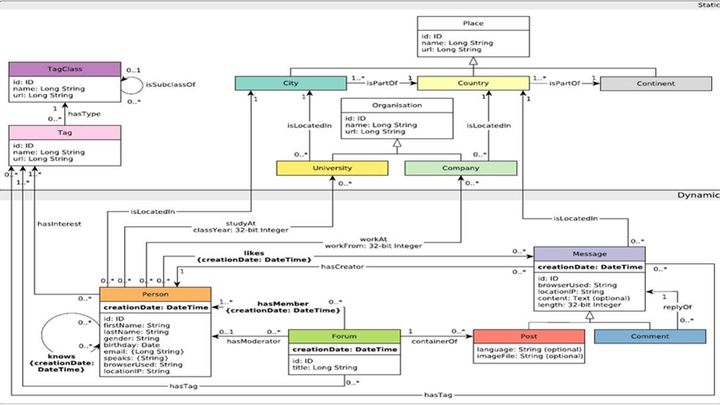
(截图来源于官方文档http://ldbcouncil.org/ldbc_snb_docs/ldbc-snb-specification.pdf)
如图所示,Datagen生成的数据有预设的一套图模型,包括:
8种节点:organization & place & tag & tagClass & person & forum & post & comment
15种关系,如下表:
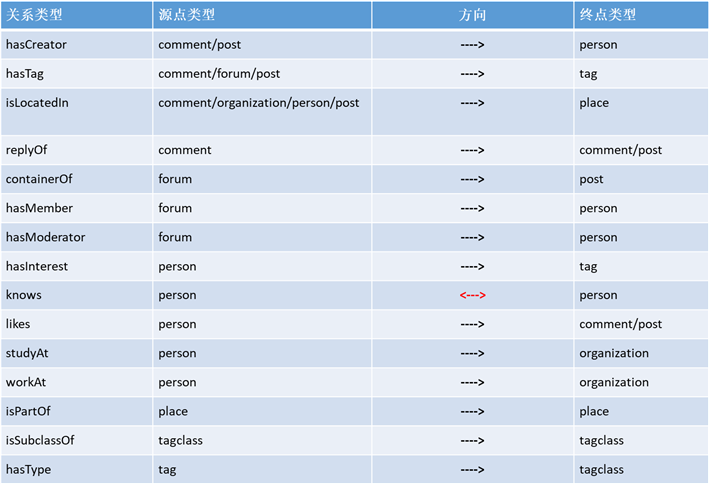
这些预设的节点和关系,形成了一个逻辑自恰的数据“武林”,以ldbc snb为测试标准的图数据库产品,就像是行走于其中的侠客们,都得遵循同一套“武林规矩”(测试用例),究竟谁能击败各方高手,问鼎盟主呢?且拭目以待吧。
安装和运行流程
在Interactive Workload模式下,Datagen的底座为hadoop;在BI Workload模式下,底座为Spark。
本次调研主要使用基于伪分布式hadoop的Datagen。
1)下载基于hadoop的ldbc datagen
https://github.com/ldbc/ldbc_snb_datagen_hadoop
2)使用伪分布式的hadoop
cd ldbc_snb_datagen_hadoop/
cp params-csv-composite.ini params.ini
wget http://archive.apache.org/dist/hadoop/core/hadoop-3.2.1/hadoop-3.2.1.tar.gz
tar xf hadoop-3.2.1.tar.gz
export HADOOP_CLIENT_OPTS="-Xmx2G"
# set this to the Hadoop 3.2.1 directory
export HADOOP_HOME=`pwd`/hadoop-3.2.1
./run.sh
3)编译时出现缺失的jar包问题解决(报错如下)
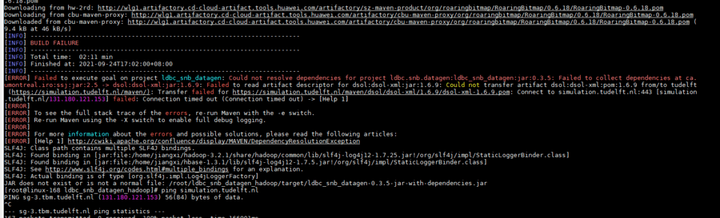
解决方案:
从windows环境下载https://simulation.tudelft.nl/maven/dsol/dsol-xml/1.6.9/
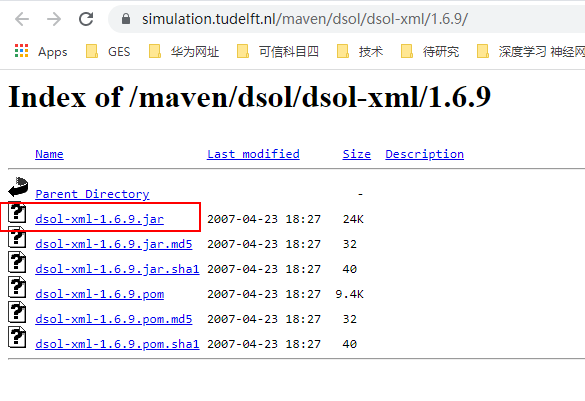
手动安装缺失的jar包到本地的maven仓库
mvn install:install-file -Dfile=dsol-xml-1.6.9.jar -DgroupId=dsol -DartifactId=dsol-xml -Dversion=1.6.9 -Dpackaging=jar
4)再次运行,完成生成
sh run.sh
生成的数据文件存储在${outputDir}/social_network。
参数设置
(以下参数介绍均省略了前缀“ldbc.snb.datagen.”,即参数的完整格式为“ldbc.snb.datagen.xxx”)
1)常规参数
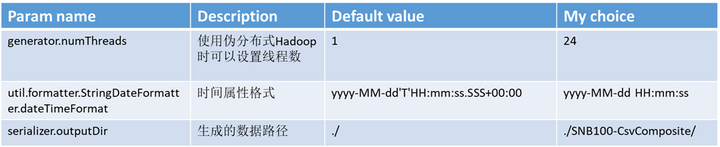
2)规模因子
LDBC SNB支持生成不同规模的图数据集,generator.scaleFactor参数各取值对应的点边数目如下表:

(截图来源于官方文档http://ldbcouncil.org/ldbc_snb_docs/ldbc-snb-specification.pdf)
3)序列化模式
Datagen主要有4种Csv文件的序列化模式,所生成的数据格式各有不同。
CsvBasic
基础序列化模式,每种节点、节点和节点之间的关系都有独立的csv文件,如图一所示:
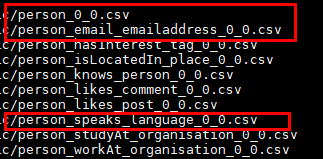
图一 每种节点、节点和节点之间的关系都有独立的csv文件,其中person_xx.csv均为person节点的属性数据。
若某个属性有多个取值,例如person的email属性有多个值,则将person的email记录单独生成一个csv文件,并将多个email分成多行记录展示,如图二所示:
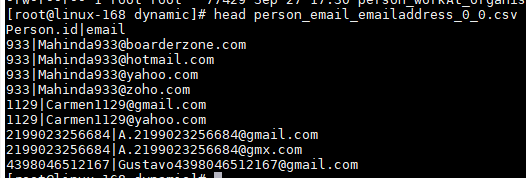
图二 person的email属性单独存储,并在多个email分成多条记录展示
CsvComposite(此模式生成的数据,与GES支持的Csv格式相似度最高)
在CsvBasic的基础上,将有多个值的属性和其他属性合并为一个记录,如图三;并将多个值进行合并(以list的格式,分号分隔),如图四;
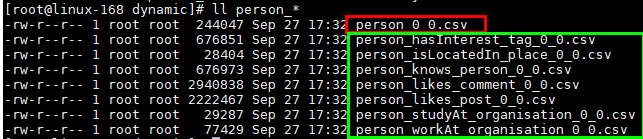
图三 person节点的属性记录合并为person_0_0.csv

图四 language和email两个list属性合并在一行
CsvMergeForeign
在CsvBasic基础上,如果节点间关系是1对多的,则将关系作为外键合并入节点的属性文件中展示,如图五

图五 将comment-hasCreator->person、comment-isLocatedIn->place、comment-replyOf->post、comment-replyOf->comment关系与comment属性文件合并
CsvCompositeMergeForeign
是CsvComposite和 CsvMergeForeign的结合,既合并了list属性,又将一对多关系进行了压缩表示,如图六

图六 place列表示person-isLocatedIn->place关系的外键表示,同时language和email以list形式展示
各序列化模式对应的参数值如下
CsvBasic
- ldbc.snb.datagen.serializer.dynamicActivitySerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.activity.CsvBasicDynamicActivitySerializer
- ldbc.snb.datagen.serializer.dynamicPersonSerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.person.CsvBasicDynamicPersonSerializer
- #ldbc.snb.datagen.serializer.staticSerializer:ldbc.snb.datagen.serializer.snb.csv.staticserializer.CsvBasicStaticSerializer
CsvComposite
- ldbc.snb.datagen.serializer.dynamicActivitySerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.activity.CsvCompositeDynamicActivitySerializer
- ldbc.snb.datagen.serializer.dynamicPersonSerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.person.CsvCompositeDynamicPersonSerializer
- ldbc.snb.datagen.serializer.staticSerializer:ldbc.snb.datagen.serializer.snb.csv.staticserializer.CsvCompositeStaticSerializer
CsvMergeForeign
- ldbc.snb.datagen.serializer.dynamicActivitySerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.activity.CsvMergeForeignDynamicActivitySerializer
- ldbc.snb.datagen.serializer.dynamicPersonSerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.person.CsvMergeForeignDynamicPersonSerializer
- ldbc.snb.datagen.serializer.staticSerializer:ldbc.snb.datagen.serializer.snb.csv.staticserializer.CsvMergeForeignStaticSerializer
CsvCompositeMergeForeign
- ldbc.snb.datagen.serializer.dynamicActivitySerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.activity.CsvCompositeMergeForeignDynamicActivitySerializer
- ldbc.snb.datagen.serializer.dynamicPersonSerializer:ldbc.snb.datagen.serializer.snb.csv.dynamicserializer.person.CsvCompositeMergeForeignDynamicPersonSerializer
- ldbc.snb.datagen.serializer.staticSerializer:ldbc.snb.datagen.serializer.snb.csv.staticserializer.CsvCompositeMergeForeignStaticSerializer
二、LDBC SNB在GES中的应用
Datagen生成的数据集与GES格式有以下3点区别
- 不同label的点id之间可能存在id重复的现象;
- knows关系是双向的;
- 没有label列。
使用DatagenToGES数据转换脚本(基于CsvComposite序列化模式)可以将LDBC数,需在python3.6环境下运行。
DatagenTOGES脚本有如下功能:
- 将8种节点类型映射为1-8个数字前缀,将原id转换为以数字前缀为开头、长度为20bytes的新id,解决不同label的点之间id重复的问题;
- 增加knows边文件的反向边数据;
- 增加label列。
转换前文件格式(CsvComposite序列化模式):
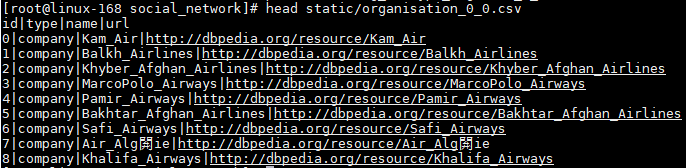

转换后文件格式:
DatagenToGES转换规模因子为100的大规模数据集用时约半个小时。
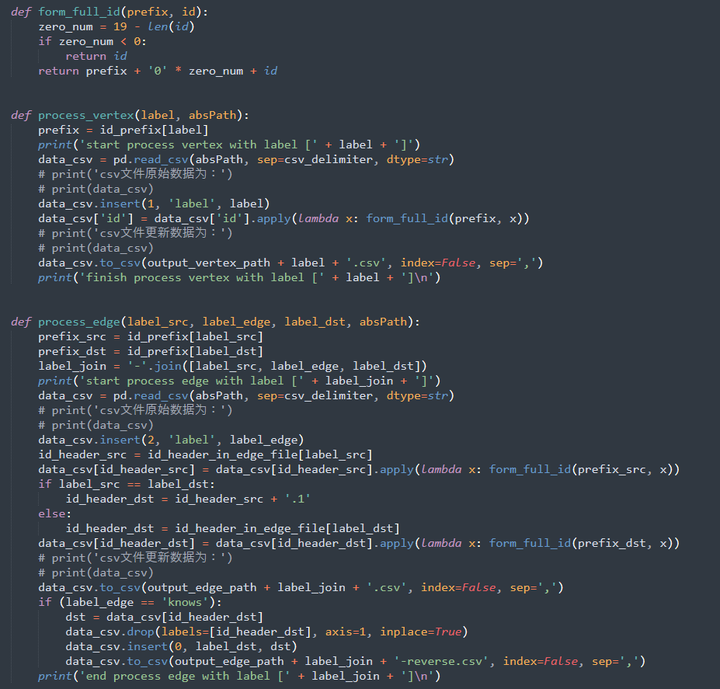
数据转换脚本核心代码片段:
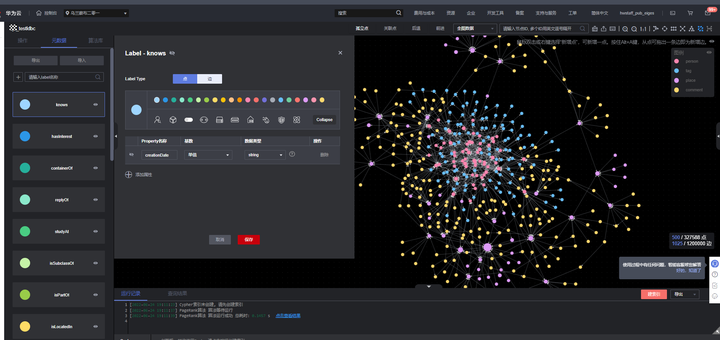
在GES中导入转换后的LDBC SNB(示例数据为SF0.1),并执行PageRank算法,效果如下图:
带你认识图数据库性能和场景测试利器LDBC SNB的更多相关文章
- 从一个 issue 出发,带你玩图数据库 NebulaGraph 内核开发
如何 build NebulaGraph?如何为 NebulaGraph 内核做贡献?即便是新手也能快速上手,从本文作为切入点就够了. NebulaGraph 的架构简介 为了方便对 NebulaGr ...
- 入门级----黑盒测试、白盒测试、手工测试、自动化测试、探索性测试、单元测试、性能测试、数据库性能、压力测试、安全性测试、SQL注入、缓冲区溢出、环境测试
黑盒测试 黑盒测试把产品软件当成是一个黑箱子,只有出口和入口,测试过程中只要知道往黑盒中输入什么东西,知道黑盒会出来什么结果就可以了,不需要了解黑箱子里面是如果做的. 即测试人员不用费神去理解软件里面 ...
- OPPO 图数据库平台建设及业务落地
本文首发于 OPPO 数智技术公众号,WeChat ID: OPPO_tech 1.什么是图数据库 图数据库(Graph database)是以图这种数据结构存储和查询的数据库.与其他数据库不同,关系 ...
- NoSQL 数据库的使用场景
摘要:对比传统关系型数据库,NoSQL有着更为复杂的分类——键值.面向文档.列存储.图数据库.这里就带你一览NoSQL各种类型的适用场景及一些知名公司的方案选择. 在过去几年,关系型数据库一直是数据持 ...
- Nebula Graph 技术总监陈恒:图数据库怎么和深度学习框架进行结合?
引子 Nebula Graph 的技术总监在 09.24 - 09.30 期间同开源中国·高手问答的小伙伴们以「图数据库的设计和实践」为切入点展开讨论,包括:「图数据库的存储设计」.「图数据库的计算设 ...
- Neo4j图数据库从入门到精通(转)
add by zhj: 转载时,目录没整理好,还会跳转到原文 其实RDB也可以存储多对多的关系,使用的是中间表,GDB使用的是边,RDB中的实体存储在数据表,而GDB存储在节点.两者使用的底层技术不同 ...
- 数栈运维实例:Oracle数据库运维场景下,智能运维如何落地生根?
从马车到汽车是为了提升运输效率,而随着时代的发展,如今我们又希望用自动驾驶把驾驶员从开车这项体力劳动中解放出来,增加运行效率,同时也可减少交通事故发生率,这也是企业对于智能运维的诉求. 从人工运维到自 ...
- 高性能内存图数据库RedisGraph(一)
作为一种简单.通用的数据结构,图可以表示数据对象之间的复杂关系.生物信息学.计算机网络和社交媒体等领域中产生的大量数据,往往是相互连接.关系复杂且低结构化的,这类数据对传统数据库而言十分棘手,一个简单 ...
- 陈宏智:字节跳动自研万亿级图数据库ByteGraph及其应用与挑战
导读: 作为一种基础的数据结构,图数据的应用场景无处不在,如社交.风控.搜广推.生物信息学中的蛋白质分析等.如何高效地对海量的图数据进行存储.查询.计算及分析,是当前业界热门的方向.本文将介绍字节跳动 ...
- mysql数据库性能优化(包括SQL,表结构,索引,缓存)
优化目标减少 IO 次数IO永远是数据库最容易瓶颈的地方,这是由数据库的职责所决定的,大部分数据库操作中超过90%的时间都是 IO 操作所占用的,减少 IO 次数是 SQL 优化中需要第一优先考虑,当 ...
随机推荐
- Redis平台-整合PHP
1.Redis的相关介绍: 定义: redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合 ...
- 【Java集合】了解集合的框架体系结构及常用实现类,从入门到精通!
前言 通过Java基础的学习,我们掌握了主要的Java语言基本的语法,同时了解学习了Java语言的核心-面向对象编程思想. 从集合框架开始,也就是进入了java这些基础知识及面向对象思想进入实际应用编 ...
- React 基础介绍以及demo实践
这篇文章是之前给新同事培训react基础所写的文章,现贴这里供大家参考: 1.什么是React? React 是一个用于构建用户界面的JavaScript库核心专注于视图,目的实现组件化开发 2.组件 ...
- 从这里开始,跟我一起搞懂 MySQL!
提前申明:<MySQL 基础实战>系列是学习极客时间林晓斌的<MySQL实战45讲>的整理和总结,希望大家仅做为学习使用! 架构示意图 Server 层:包括连接器.查询缓存. ...
- 发现AI自我意识:不期而遇的局部技术奇点
Q*的启示 之前的文章里提到过,人工智能思维能力创造的必不可少的条件是状态空间的搜索.今天的大新闻里,我们都看到了Q*的确使用了搜索算法.所以今天我会稍微谈一下这个话题. 主要思想就是人工智能的进一步 ...
- 深入了解PBKDF2加密技术:原理与实践
摘要:本文详细介绍了PBKDF2(Password-Based Key Derivation Function 2)加密技术,包括其原理.算法流程和实际应用,旨在帮助读者更好地理解这一重要的加密方法. ...
- java-图片添加水印
前言: 需求:需要在图片中添加水印,防止盗用 优缺点: 优点:保护版权,防止盗用 缺点 可能会影响图片的视觉效果:如果水印过大或过醒目,可能会影响图片的视觉效果. 可能会增加 ...
- SFX的妙用——如何在不安装软件的情况下打开自定义格式文件?
前段时间看到群友讨论压缩包能不能运行,想起了N年前用自解压文件SFX实现的一个"需求":在没有安装任何应用软件的Windows(当时还要支持XP)上能双击打开自定义格式的文件.当时 ...
- Windows服务器,通过Nginx部署VUE+Django前后端分离项目
目录 基本说明 安装 Nginx 部署 VUE 前端 部署 Django 后端 Django admin 静态文件(CSS,JS等)丢失的问题 1. 基本说明 本文介绍了在 windows 服务器下, ...
- HDFS存储原理
冗余数据保存问题: 一个数据块默认被保存三次 好处:1.加快数据传输错误(假如要同时访问数据块1 因为他冗余存储就会有3份 所以会加快数据传输速度) 2.很容易检查数据错误 3.保证数据可靠性 数据的 ...