重新整理数据结构与算法(c#)—— 堆排序[二十一]
前言
将下面按照从小到大排序:
int[] arr = { 4, 6, 8, 5, 9 };
这时候可以通过冒泡排序,计数排序等。
但是一但数据arr很大,那么会产生排序过于缓慢,堆排序就是一个很好的解决方案。
树的堆,有最大堆和最小堆。
看下最大堆:
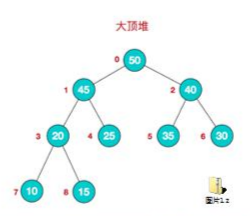
它是这样子的,就是说一个节点的大小一定大于它的左节点和右节点大小。
如何利用最大堆。进行从大到小的排序呢?
细节
细节如下:
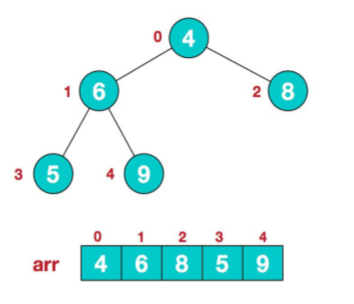
假如堆排序后:
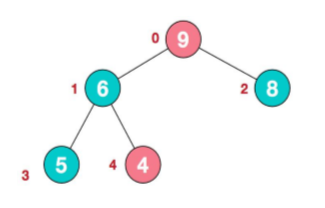
那么用root(根节点,最大节点)和最后一个数组元素进行交换,那么下次进行堆排序的元素就是length-1个,就不用管最后一个元素,因为最后一个元素已经排好序,且最大。
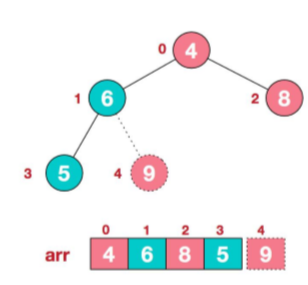
那么现在回到一个问题上了,就是如何进行最大堆排序呢?
有如下步骤:
1.找到树的最后非叶子节点。arr.length/2-1
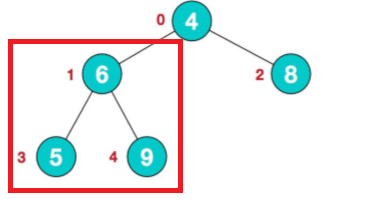
现在只需要关注红框的子树。
2.先把最后一个非叶子节点作为子树,进行堆排序。(比较他们的左右节点,把最大的和根节点进行交换)
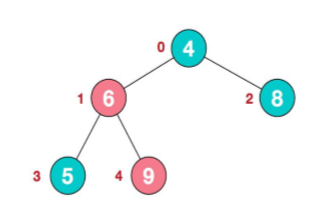
那么也就是下面已经是最大堆了。
然后在往上比较:
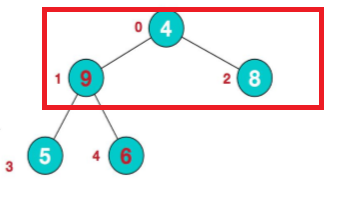
分为两种情况,一个就是加入有节点和根节点进行交换的话,那个节点就要作为子树进行堆排序。
比如这里,4和9要进行交换了,那么下面就不是最大堆了,所以左子树要再次进行最大堆结构化。
代码
static void Main(string[] args)
{
int[] arr = { 4, 6, 8, 5, 9 };
//制作成第一个大顶堆
for (int i=arr.Length/2-1;i>=0;i--)
{
adjustHeap(arr,i,arr.Length);
}
int temp = 0;
for (int j = arr.Length - 1; j > 0; j--)
{
//交换
temp = arr[j];
arr[j] = arr[0];
arr[0] = temp;
// j 为需要比较元素的个数为:j-1+1=j
adjustHeap(arr, 0, j);
}
foreach (var i in arr)
{
Console.WriteLine(i);
}
Console.ReadKey();
}
public static void adjustHeap(int[] arr,int i,int lenght)
{
int temp = arr[i];
for (int k= 2*i+1;k < lenght; k=2*k+1)
{
if (k + 1 < lenght)
{
if (arr[k] < arr[k + 1])
{
k++;
}
}
if (arr[k] > arr[i])
{
arr[i] = arr[k];
i = k;
}
else
{
//因为下面都是排序好了的
break;
}
}
arr[i] = temp;
}
结果:
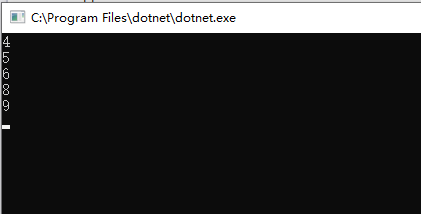
性能测试
static void Main(string[] args)
{
//int[] arr = { 4, 6, 8, 5, 9 };
int[] arr = new int[8000000];
for (int i = 0; i < 8000000; i++)
{
arr[i] = (int)((new Random().Next()) * 8000000); // 生成一个[0, 8000000) 数
}
Stopwatch stopwatch = new Stopwatch();
stopwatch.Start();
//制作成第一个大顶堆
for (int i=arr.Length/2-1;i>=0;i--)
{
adjustHeap(arr,i,arr.Length);
}
int temp = 0;
for (int j = arr.Length - 1; j > 0; j--)
{
//交换
temp = arr[j];
arr[j] = arr[0];
arr[0] = temp;
// j 为需要比较元素的个数为:j-1+1=j
adjustHeap(arr, 0, j);
}
stopwatch.Stop();
Console.WriteLine(stopwatch.ElapsedMilliseconds);
Console.ReadKey();
}
public static void adjustHeap(int[] arr,int i,int lenght)
{
int temp = arr[i];
for (int k= 2*i+1;k < lenght; k=2*k+1)
{
if (k + 1 < lenght)
{
if (arr[k] < arr[k + 1])
{
k++;
}
}
if (arr[k] > arr[i])
{
arr[i] = arr[k];
i = k;
}
else
{
//因为下面都是排序好了的
break;
}
}
arr[i] = temp;
}
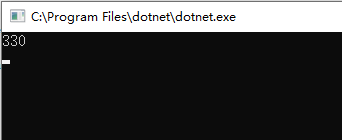
测试的时间为:
重新整理数据结构与算法(c#)—— 堆排序[二十一]的更多相关文章
- C#数据结构与算法系列(二十一):希尔排序算法(ShellSort)
1.介绍 希尔排序是希尔(Donald Shell)于1959年提出的一种排序算法.希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为缩小增量排序. 2.基本思想 希尔排 ...
- Java数据结构与算法解析(十二)——散列表
散列表概述 散列表就是一种以 键-值(key-indexed) 存储数据的结构,我们只要输入待查找的值即key,即可查找到其对应的值. 散列表的思路很简单,如果所有的键都是整数,那么就可以使用一个简单 ...
- 数据结构与算法16—平衡二叉(AVL)树
我们知道,对于一般的二叉搜索树(Binary Search Tree),其期望高度(即为一棵平衡树时)为log2n,其各操作的时间复杂度O(log2n)同时也由此而决定.但是,在某些极端的情况下(如在 ...
- C#数据结构与算法系列(二十三):归并排序算法(MergeSort)
1.介绍 归并排序(MergeSort)是利用归并的思想实现的排序方法,该算法采用经典的分治策略(分治法将问题分(divide)成一些小的问题然后递归求解, 而治(conquer)的阶段则将分的阶段得 ...
- Java数据结构和算法(十二)——2-3-4树
通过前面的介绍,我们知道在二叉树中,每个节点只有一个数据项,最多有两个子节点.如果允许每个节点可以有更多的数据项和更多的子节点,就是多叉树.本篇博客我们将介绍的——2-3-4树,它是一种多叉树,它的每 ...
- 数据结构与算法问题 AVL二叉平衡树
AVL树是带有平衡条件的二叉查找树. 这个平衡条件必须保持,并且它必须保证树的深度是O(logN). 一棵AVL树是其每一个节点的左子树和右子树的高度最多差1的二叉查找树. (空树的高度定义为-1). ...
- C#数据结构与算法系列(二十):插入排序算法(InsertSort)
1.介绍 插入排序算法属于内部排序算法,是对于欲排序的元素以插入的方式找寻该元素的适当位置,以达到排序的目的 2.思想 插入排序(Insertion Sorting)的基本思想是:把n个待排序的元素看 ...
- 重新整理数据结构与算法(c#)—— 图的深度遍历和广度遍历[十一]
参考网址:https://www.cnblogs.com/aoximin/p/13162635.html 前言 简介图: 在数据的逻辑结构D=(KR)中,如果K中结点对于关系R的前趋和后继的个数不加限 ...
- C#数据结构与算法系列(二):稀疏数组(SparseArray)
1.介绍 当一个数组中大部分元素为0,或者为同一个值的数组时,可以使用稀疏数组来保存该数组. 稀疏数组的处理方法是: 1.记录数组一共有几行几列,有多少个不同的值 2.把具有不同值的元素的 ...
- C#数据结构与算法系列(二十二):快速排序算法(QuickSort)
1.介绍 快速排序(QuickSort)是对冒泡排序的一种改进,基本思想是:通过一趟排序将要排序的数据分割成独立的两部分, 其中一部分的所有数据都比另一部分的所有数据都要小,然后再按此方法对这两部分数 ...
随机推荐
- CPNtools协议建模安全分析---实例(三)
对于复杂的系统的建模或者协议的建模,各种颜色集的定义以及变量的声明很重要,要区分明确,对于函数行业进程的定义更加复杂.CPN对协议的描述只适合简单逻辑性的协议分析,如果协议包括复杂的算法,那么CPN就 ...
- 删除无用的docker镜像与容器
docker rm `docker ps -a | grep Exited | awk '{print $1}'` 删除异常停止的docker容器 docker rmi -f `docker imag ...
- Zabbix与乐维监控对比分析(五)——可视化篇
前面我们详细介绍了Zabbix与乐维监控的架构与性能.Agent管理.自动发现.权限管理.对象管理.告警管理方面的对比分析,相信大家对二者的对比分析有了相对深入的了解,接下来我们将对二者的可视化功能进 ...
- [VueJsDev] 基础知识 - Node.js常用函数
[VueJsDev] 目录列表 https://www.cnblogs.com/pengchenggang/p/17037320.html Node.js 常用函数 总结常用 node 函数 用的 E ...
- 金蝶中间件 前后台连不上 报跨域 前台解决方案: --user-data-dir="c:\ChromeDebug" --test-type --disable-web-security
chrome 浏览器的快捷方式后面加参数 --user-data-dir="c:\ChromeDebug" --test-type --disable-web-security
- 使用systemback工具制定Debian.ISO文件
1.安装systemback https://nchc.dl.sourceforge.net/project/systemback/1.8/Systemback_Install_Pack_v1.8.4 ...
- AWS ES ISM学习应用笔记
Elastic Search 6以上版本推出 ILM,用于管理Index的生命周期,但AWS上的ES是基于OSS版本的ES,所以自己开发了ISM来代替ILM.项目是从logstash往ES写入数据,但 ...
- ETL工具-KETTLE教程实例实战2----环境介绍
一.整体结构图 Kettle 是"Kettle E.T.T.L. Envirnonment"只取首字母的缩写,这意味着它被设计用来帮助你实现你的ETTL 需要:抽取.转换.装入和加 ...
- epoll水平触发与边缘触发
把高电平看作文件描述符是可读或可写状态,低电平黑色表示不可读或不可写,epoll_wait的水平触发就是蓝色的时候epoll_wait就会被触发,而边缘触发就是红色的时候epoll_wait会触发,且 ...
- 【Mahjong hdu 枚举】搜索枚举
#####枚举 import java.io.*; import java.util.*; public class Main { static HashSet<String> set1; ...