SQLServer 执行计划的简单学习和与类型转换的影响
SQLServer 执行计划的简单学习和与类型转换的影响
背景
最近一直在看SQLServer数据库
索引.存储.还有profiler的使用 并且用到了 deadlock graph
但是感觉还是不太深入
数据库的查询计划学习的还是太少.
正好同事说到了jdbc里面的 :sendStringParametersAsUnicode
参数的问题.
一直没搞明白影响程度, 所以想继续学习验证一下.
方式
-- 开启记录的事项
SET STATISTICS TIME ON
SET STATISTICS IO ON
SET STATISTICS PROFILE ON
-- 刷新缓存, 避免有影响.
dbcc dropcleanbuffers
验证思路
本次主要是想验证 where 条件后面 等于的字符串 在带不带 N 的影响.
所以执行的SQL主要如下:
SET STATISTICS TIME ON
SET STATISTICS IO ON
SET STATISTICS PROFILE ON
dbcc dropcleanbuffers
--- 第一个SQL
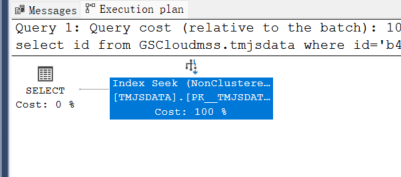
select id from xxx.tablename where id='b45db192-1392-4afd-954b-cb0b5c63abb0'
--- 第二个SQL
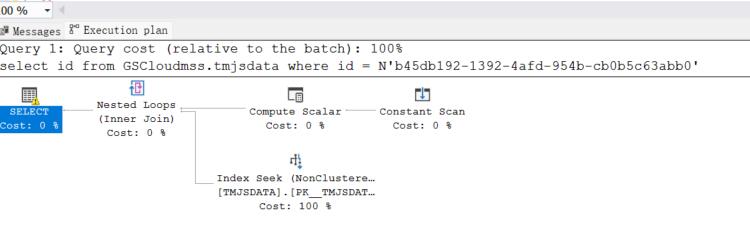
select id from xxx.tablename where id = N'b45db192-1392-4afd-954b-cb0b5c63abb0'
带 N 的执行时间
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
SQL Server 执行时间:
CPU 时间不是在纤程模式下测量的,占用时间 = 0 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
(1 行受影响)
表 'TMJSDATA'。扫描计数 1,逻辑读取 4 次,物理读取 4 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
(5 行受影响)
(1 行受影响)
SQL Server 执行时间:
CPU 时间不是在纤程模式下测量的,占用时间 = 89 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
SQL Server 执行时间:
CPU 时间不是在纤程模式下测量的,占用时间 = 0 毫秒。
不带N的执行情况
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
SQL Server 执行时间:
CPU 时间不是在纤程模式下测量的,占用时间 = 0 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
(1 行受影响)
表 'TMJSDATA'。扫描计数 0,逻辑读取 4 次,物理读取 4 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
(2 行受影响)
(1 行受影响)
SQL Server 执行时间:
CPU 时间不是在纤程模式下测量的,占用时间 = 1 毫秒。
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
SQL Server 执行时间:
CPU 时间不是在纤程模式下测量的,占用时间 = 0 毫秒。
分析-基础知识
预读:用于估计信息,去硬盘读取数据到缓存。
物理读:查询计划生成以后,如果发现缓存缺少所需要的数据,让缓存再次去读硬盘数据。
逻辑读:SQLSERVER去内存里的缓存取数据或者执行计划
SQLSERVER存储的最小单位是页,每一页大小为8K,即8*1024=8192字节,
SQLSERVER对页的读取是原子性的,即要么读完一页,要么完全不读。
即使仅仅要获得一条数据,也要读完该页,而页之间的数据组织结构为B树结构。所以SQLSERVER对于逻辑读,物理读,预读的单位是页。
扫描计数是指在SQL查询执行过程中,统计表或索引的扫描次数的过程。
扫描操作常常是影响查询性能的重要因素,因为扫描比索引查找更消耗资源。
官方文档里面的解释为:
扫描计数是在任何方向都达到叶级别后启动的查询/扫描数,目的在于检索用于构造输出的最终数据集的所有值。
在任意方向到达叶级别之后开始的搜索或扫描次数,搜索/扫描目的是检索所有用于构造输出的最终数据集的值。
如果使用的索引是主键上的唯一索引或聚集索引,且只搜索一个值,则扫描计数为 0。 例如,WHERE Primary_Key_Column = <value>。
当使用对非主键列定义的非唯一的聚集索引搜索一个值时,扫描计数为 1。 此过程的目的是针对你正在搜索的键值检查重复值。 例如,WHERE Clustered_Index_Key_Column = <value>。
当 N 为通过使用索引键定位键值后,在叶级别的左侧或右侧启动的不同查找或扫描数时,则扫描计数为 N
分析-简单结论
因为数据库表结构是 varchar 类型的 where条件强行指定 N之后
发现查询计划出现了偏差.
会多一次扫描计数, 并且执行的时间也会变长, 的确存在较严重的性能下降.
查询计划也复杂一些. 所以感觉类型转换在数据库的执行过程中还是存在较严重的性能风险
非常不建议使用.
建议还是固定好数据结构数据类型. 避免出现字段变更导致性能问题.
带-N 的查询结果
不带-N的执行计划
SQLServer 执行计划的简单学习和与类型转换的影响的更多相关文章
- mysql之优化器、执行计划、简单优化
mysql之优化器.执行计划.简单优化 2018-12-12 15:11 烟雨楼人 阅读(794) 评论(0) 编辑 收藏 引用连接: https://blog.csdn.net/DrDanger/a ...
- SQLSERVER执行计划详解
序言 本篇主要目的有二: 1.看懂t-sql的执行计划,明白执行计划中的一些常识. 2.能够分析执行计划,找到优化sql性能的思路或方案. 如果你对sql查询优化的理解或常识不是很深入,那么推荐几骗博 ...
- MySQL数据库执行计划(简单版)
+++++++++++++++++++++++++++++++++++++++++++标题:MySQL数据库执行计划简单版时间:2019年2月25日内容:MySQL数据库执行计划简单版重点:MySQL ...
- 看懂SqlServer执行计划
在园子看到一篇SQLServer关于查询计划的好文,激动啊,特转载.原文出自:http://www.cnblogs.com/fish-li/archive/2011/06/06/2073626.htm ...
- SqlServer 执行计划及Sql查询优化初探
网上的SQL优化的文章实在是很多,说实在的,我也曾经到处找这样的文章,什么不要使用IN了,什么OR了,什么AND了,很多很多,还有很多人拿出仅几S甚至几MS的时间差的例子来证明着什么(有点可笑),让许 ...
- Oracle性能优化之oracle中常见的执行计划及其简单解释
一.访问表执行计划 1.table access full:全表扫描.它会访问表中的每一条记录(读取高水位线以内的每一个数据块). 2.table access by user rowid:输入源ro ...
- SqlServer执行计划
MSSQLSERVER执行计划详解 * from ServiceInvoke; --创建时间聚集索引扫描 * from AdoLog; --主键ID聚集索引扫描 --2.根据聚集索引排序-性能提升 - ...
- SQLServer 执行计划
http://www.cnblogs.com/fish-li/archive/2011/06/06/2073626.html#_label0 http://www.jb51.net/article ...
- SqlServer 中如何查看某一个Sql语句是复用了执行计划,还是重新生成了执行计划
我们知道SqlServer的查询优化器会将所执行的Sql语句的执行计划作缓存,如果后续查询可以复用缓存中的执行计划,那么SqlServer就会为后续查询复用执行计划而不是重新生成一个新的执行计划,因为 ...
- sqlser 2005 使用执行计划来优化你的sql
一:sqlserver 执行计划介绍 sqlserver 执行计是在sqlser manager studio 工具中打开,是检查一条sql执行效率的工具.建议配合SET STATISTICS ...
随机推荐
- win11 右击还原 win10的
以管理员身份 打开 powershell, 然后输入如下代码 .\reg.exe add "HKCU\Software\Classes\CLSID\{86ca1aa0-34aa-4e8b-a ...
- Jenkins汉化配置
登录进入Jenkins首页 输入:本地ip+端口号(localhost:8099) 进入插件管理页面(Manage Jenkins)安装相关插件 搜索:到available栏目搜索:Locale pl ...
- Boost程序库完全开发指南:1-开发环境和构建工具
Boost官方于2019年12月发布的1.72版编写,共包含160余个库/组件,涵盖字符串与文本处理.容器.迭代器.算法.图像处理.模板元编程.并发编程等多个领域,使用Boost,将大大增强C++ ...
- MySQL思维导图:MySQL的架构介绍
MySQL的架构介绍(思维导图形式) MySQL简介 概述 MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性. ...
- MySQL篇:第二章_初识MySQL
初始MySQL MySQL的背景 1.前身属于瑞典的一家公司,MySQL AB 2.08年被sun公司收购 3.09年sun被oracle收购 MySQL的优点 1.开源.免费.成本低 2.性能高.移 ...
- 终于搞懂了Python模块之间的相互引用问题
摘要:详细讲解了相对路径和绝对路径的引用方法. 在某次运行过程中出现了如下两个报错: 报错1: ModuleNotFoundError: No module named '__main__.src_t ...
- web自动化测试(1):再谈UI发展史与UI、功能自动化测试
前言(废话) 行文前,安利下文章:<图形界面操作系统发展史--计算机界面发展历史回顾>.<再谈MV*(MVVM MVP MVC)模式的设计原理-封装与解耦> 1973年4月,X ...
- 在Linux(CentOS7)服务器上安装Java的JDK
一.介绍 最近,我在做有关CI/CD的测试,真是一步一个坑啊,碰得我头破血流,这么难得的经验,必须记录下来,以防以后想找却找不到.说道CI/CD最好的工具,大家肯定是一致推荐Jenkins,对了,我现 ...
- Kubernetes(K8S) Controller - Deployment 介绍
什么是controller 实际存在的,管理和运行容器的对象 Pod 和 Controller 关系 Pod 是通过 Controller 实现应用的运维,比如伸缩.滚动升级等等 Pod 和 Cont ...
- Zookeeper面试题总结
1.请简述Zookeeper的选举机制 假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的. 假设这些服务器 ...