Kubernetes(K8S) Node NotReady 节点资源不足 Pod无法运行
k8s 线上集群中 Node 节点状态变成 NotReady 状态,导致整个 Node 节点中容器停止服务。
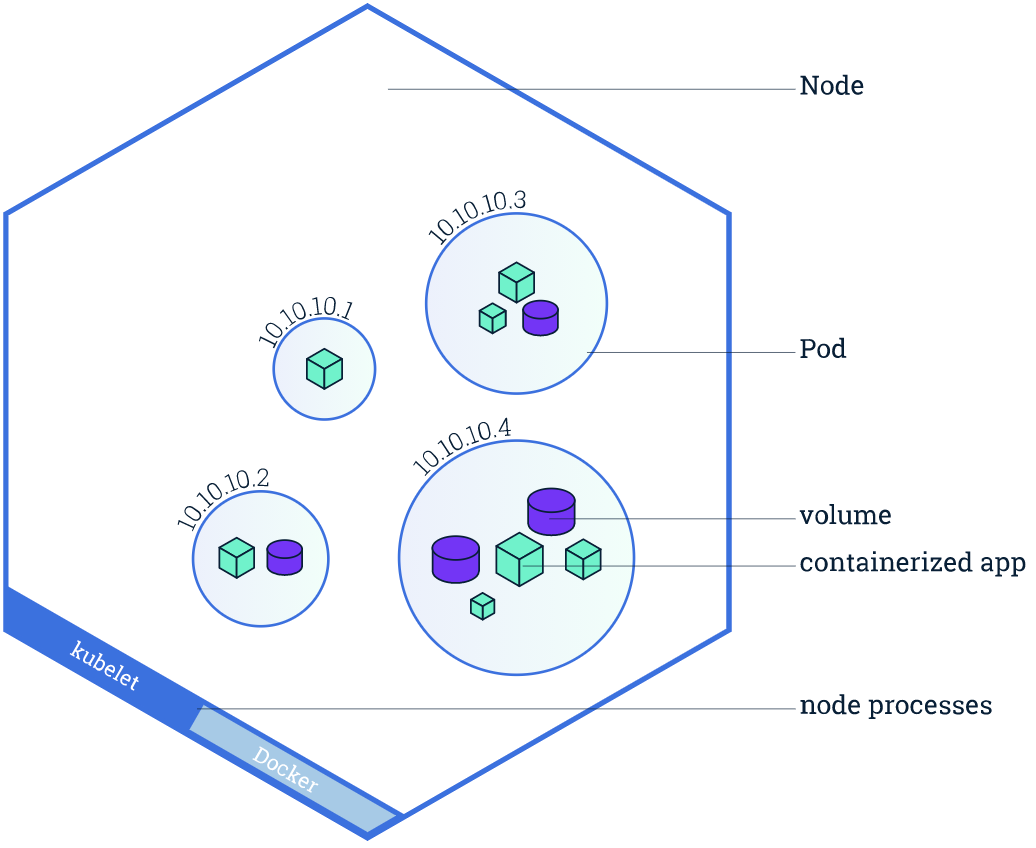
一个 Node 节点中是可以运行多个 Pod 容器,每个 Pod 容器可以运行多个实例 App 容器。Node 节点不可用,就会直接导致 Node 节点中所有的容器不可用,Node 节点是否健康,直接影响该节点下所有的实例容器的健康状态,直至影响整个 K8S 集群
# 查看节点的资源情况
[root@k8smaster ~]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8smaster 269m 13% 1699Mi 22%
k8snode1 1306m 65% 9705Mi 82%
k8snode2 288m 14% 8100Mi 68%
# 查看节点状态
[root@k8smaster ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8smaster Ready master 33d v1.18.19
k8snode1 NotReady <none> 33d v1.18.19
k8snode2 Ready <none> 33d v1.18.19
# 查看节点日志
[root@k8smaster ~]# kubectl describe nodes k8snode1
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1 (50%) 7100m (355%)
memory 7378Mi (95%) 14556Mi (188%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning SystemOOM 30m kubelet System OOM encountered, victim process: java, pid: 29417
Warning SystemOOM 30m kubelet System OOM encountered, victim process: java, pid: 29418
Warning SystemOOM 30m kubelet System OOM encountered, victim process: java, pid: 29430
Warning SystemOOM 30m kubelet System OOM encountered, victim process: erl_child_setup, pid: 26391
Warning SystemOOM 30m kubelet System OOM encountered, victim process: beam.smp, pid: 26134
Warning SystemOOM 30m kubelet System OOM encountered, victim process: 1_scheduler, pid: 26392
Warning SystemOOM 29m kubelet System OOM encountered, victim process: java, pid: 28855
Warning SystemOOM 29m kubelet System OOM encountered, victim process: java, pid: 28637
Warning SystemOOM 28m kubelet System OOM encountered, victim process: java, pid: 29348
Normal NodeHasSufficientMemory 24m (x5 over 3h11m) kubelet Node k8snode1 status is now: NodeHasSufficientMemory
Normal NodeHasSufficientPID 24m (x5 over 3h11m) kubelet Node k8snode1 status is now: NodeHasSufficientPID
Normal NodeHasNoDiskPressure 24m (x5 over 3h11m) kubelet Node k8snode1 status is now: NodeHasNoDiskPressure
Warning SystemOOM 9m57s (x26 over 28m) kubelet (combined from similar events): System OOM encountered, victim process: java, pid: 30289
Normal NodeReady 5m38s (x9 over 30m) kubelet Node k8snode1 status is now: NodeReady
# 查看 pod 分在哪些节点上,发现 都在node1 上,【这是问题所在】
[root@k8smaster ~]# kubectl get pod,svc -n thothehp-test -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/basic-67ffd66f55-zjrx5 1/1 Running 13 45h 10.244.1.89 k8snode1 <none> <none>
pod/c-api-69c786b7d7-m5brp 1/1 Running 11 3h53m 10.244.1.78 k8snode1 <none> <none>
pod/d-api-6f8948ccd7-7p6pb 1/1 Running 12 139m 10.244.1.82 k8snode1 <none> <none>
pod/gateway-5c84bc8775-pk86m 1/1 Running 7 25h 10.244.1.84 k8snode1 <none> <none>
pod/im-5fc6c47d75-dl9g4 1/1 Running 8 83m 10.244.1.86 k8snode1 <none> <none>
pod/medical-5f55855785-qr7r5 1/1 Running 12 83m 10.244.1.90 k8snode1 <none> <none>
pod/pay-5d98658dbc-ww4sg 1/1 Running 11 83m 10.244.1.88 k8snode1 <none> <none>
pod/elasticsearch-0 1/1 Running 0 80m 10.244.2.66 k8snode2 <none> <none>
pod/emqtt-54b6f4497c-s44jz 1/1 Running 5 83m 10.244.1.83 k8snode1 <none> <none>
pod/nacos-0 1/1 Running 0 80m 10.244.2.67 k8snode2 <none> <none>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/nacos-headless ClusterIP None <none> 8848/TCP,7848/TCP 45h app=nacos
service/service-basic ClusterIP None <none> 80/TCP 45h app=ehp-basic
service/service-c-api ClusterIP None <none> 80/TCP 3h53m app=ehp-cms-api
service/service-d-api ClusterIP None <none> 80/TCP 139m app=ehp-ds-api
service/service-gateway NodePort 10.101.194.234 <none> 80:30180/TCP 25h app=ehp-gateway
service/service-im ClusterIP None <none> 80/TCP 129m app=ehp-im
service/service-medical ClusterIP None <none> 80/TCP 111m app=ehp-medical
service/service-pay ClusterIP 10.111.162.80 <none> 80/TCP 93m app=ehp-pay
service/service-elasticsearch ClusterIP 10.111.74.111 <none> 9200/TCP,9300/TCP 2d3h app=elasticsearch
service/service-emqtt NodePort 10.106.201.96 <none> 61613:31616/TCP,8083:30804/TCP 2d5h app=emqtt
service/service-nacos NodePort 10.106.166.59 <none> 8848:30848/TCP,7848:31176/TCP 45h app=nacos
[root@k8smaster ~]#
加大内存,重启,内存加大后,会自动分配一些到 Node2 上面,也可以能过 label 指定某个 POD 选择哪个 Node 节点
# 需要重启docker
[root@k8snode1 ~]# systemctl restart docker
# 需要重启kubelet
[root@k8snode1 ~]# sudo systemctl restart kubelet
# 查看节点的资源情况
[root@k8smaster ~]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8smaster 269m 13% 1699Mi 22%
k8snode1 1306m 65% 9705Mi 82%
k8snode2 288m 14% 8100Mi 68%
Kubernetes(K8S) Node NotReady 节点资源不足 Pod无法运行的更多相关文章
- Kubernetes K8S之固定节点nodeName和nodeSelector调度详解
Kubernetes K8S之固定节点nodeName和nodeSelector调度详解与示例 主机配置规划 服务器名称(hostname) 系统版本 配置 内网IP 外网IP(模拟) k8s-mas ...
- Kubernetes K8S之通过yaml文件创建Pod与Pod常用字段详解
YAML语法规范:在kubernetes k8s中如何通过yaml文件创建pod,以及pod常用字段详解 YAML 语法规范 K8S 里所有的资源或者配置都可以用 yaml 或 Json 定义.YAM ...
- 容器编排系统K8s之节点污点和pod容忍度
前文我们了解了k8s上的kube-scheduler的工作方式,以及pod调度策略的定义:回顾请参考:https://www.cnblogs.com/qiuhom-1874/p/14243312.ht ...
- Kubernetes调整Node节点快速驱逐pod的时间
在高可用的k8s集群中,当Node节点挂掉,kubelet无法提供工作的时候,pod将会自动调度到其他的节点上去,而调度到节点上的时间需要我们慎重考量,因为它决定了生产的稳定性.可靠性,更快的迁移可以 ...
- Kubernetes(k8s)集群部署(k8s企业级Docker容器集群管理)系列之部署master/node节点组件(四)
0.前言 整体架构目录:ASP.NET Core分布式项目实战-目录 k8s架构目录:Kubernetes(k8s)集群部署(k8s企业级Docker容器集群管理)系列目录 1.部署master组件 ...
- kubernetes之node资源紧缺时pod驱逐机制
在系统硬件资源紧缺的情况下保证node的稳定性, 是kubelet需要解决的一个重要问题 1.驱逐策略 kubelet持续监控主机的资源使用情况, 一旦出现资源紧缺的迹象, kubelet就会主动终止 ...
- Kubernetes【K8S】(三):资源清单
K8S中的资源 K8S中所有的内容都抽象为资源,资源实例化之后叫做对象.一般使用yaml格式的文件来创建符合我们预期的pod,这样的yaml文件我们一般成为资源清单. 名称空间级资源 工作负载型资源( ...
- pod(一):Kubernetes(k8s)创建pod的两种方式
目录 一.系统环境 二.前言 三.pod 四.创建pod 4.1 环境介绍 4.2 使用命令行的方式创建pod 4.2.1 创建最简单的pod 4.2.2 创建pod,指定镜像下载策略 4.2.3 创 ...
- 二进制搭建kubernetes多master集群【四、配置k8s node】
上一篇我们部署了kubernetes的master集群,参考:二进制搭建kubernetes多master集群[三.配置k8s master及高可用] 本文在以下主机上操作部署k8s node k8s ...
- Kubernetes K8S之资源控制器Daemonset详解
Kubernetes的资源控制器Daemonset详解与示例 主机配置规划 服务器名称(hostname) 系统版本 配置 内网IP 外网IP(模拟) k8s-master CentOS7.7 2C/ ...
随机推荐
- Safepoints: Meaning, Side Effects and Overheads(译文)
Safepoints: Meaning, Side Effects and Overheads (安全点:含义.副作用和开销) 去年,我一直在进行有关profiling以及JVM运行时/执行的一些讨论 ...
- VMPFC可以融合既有的片段信息来模拟出将来的情感场景
Ventromedial prefrontal cortex supports affective future simulation by integrating distributed knowl ...
- Java SPI机制学习之开发实例
原创/朱季谦 在该文章正式开始前,先对 Java SPI是什么做一个简单的介绍. SPI,是Service Provider Interface的缩写,即服务提供者接口,它允许开发人员定义一组接口,并 ...
- 关于Spring i18n国际化 报错No message found under code * for locale 'zh_CN'.的解决方案
第一步 创建资源文件 国际化文件命名格式:基本名称 _ 语言 _ 国家.properties 这里我建了两个配置文件,一个是zh_CN中文的,一个是en_GB英文的,然后在里面随便写点测试文本语句 第 ...
- 面向对象java前三次pta作业
目录: 1.前言 2.设计与分析 3.踩坑心得 4.主要困难及改进建议 5.总结 1.前言 面向对象程序设计(Object-Oriented Programming,简称OOP)是一种编程范式,它以对 ...
- mac端 安卓UI自动化安装环境配置
安装JDK 官网下载安装包https://www.oracle.com/java/technologies/javase/javase8u211-later-archive-downloads.h ...
- .NET8极致性能优化Non-GC Heap
前言 .NET8里面JIT引入了一个新的机制,叫做Non-GC Heap.JIT可以确保相关对象分配在Non-GC Heap上,该堆像其名称一样,不受GC管理.JIT需要保证这个对象没有被GC引用,并 ...
- sqlite数据库删除了数据,为什么文件不会变小?
SQLite数据库文件的大小不会自动缩小,即使删除了其中的数据. 这是因为在SQLite中,当数据被删除时,它实际上并没有立即从磁盘上移除,而是被标记为[已删除], 这种处理机制,被删除的数据仍然占用 ...
- SpringBoot整合数据可视化大屏使用
整合数据可视化大屏是现代化应用程序中的一个重要组成部分,它可以帮助我们更直观地展示和理解大量的数据. 在Spring Boot框架中,我们可以使用一些优秀的前端数据可视化库来实现数据可视化大屏,例如E ...
- java-EasyExcel模板导出
前言: 需求:根据自定义模板导出Excel,包含图片.表格,采用EasyExcel 提示:EasyExcel请使用 3.0 以上版本, 对图片操作最重要的类就是 WriteCellData<V ...