白话 Pulsar Bookkeeper 的存储模型

最近我们的 Pulsar 存储有很长一段时间数据一直得不到回收,但消息确实已经是 ACK 了,理论上应该是会被回收的,随着时间流逝不但没回收还一直再涨,最后在没找到原因的情况下就只有一直不停的扩容。
最后磁盘是得到了回收,过程先不表,之后再讨论。
为了防止类似的问题再次发生,我们希望可以监控到磁盘维度,能够列出各个日志文件的大小以及创建时间。
这时就需要对 Pulsar 的存储模型有一定的了解,也就有了这篇文章。
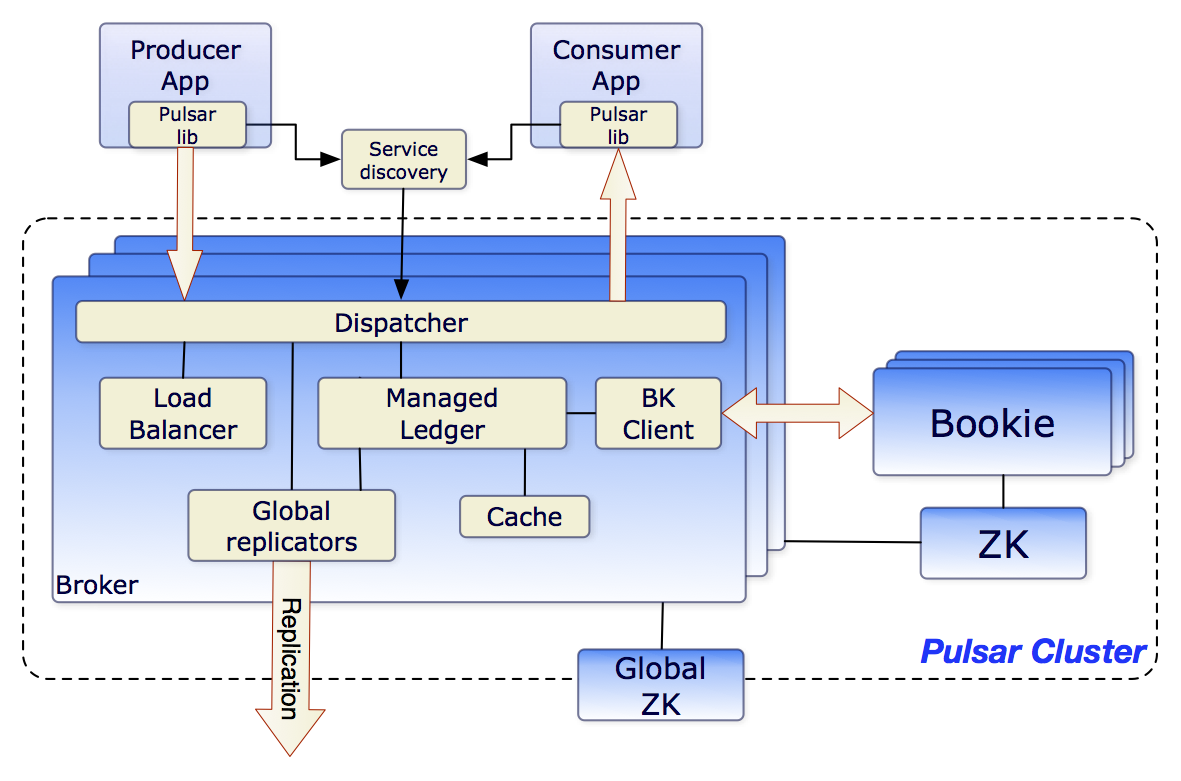
讲到 Pulsar 的存储模型,本质上就是 Bookkeeper 的存储模型。
Pulsar 所有的消息读写都是通过 Bookkeeper 实现的。
Bookkeeper是一个可扩展、可容错、低延迟的日志存储数据库,基于 Append Only 模型。(数据只能追加不能修改)
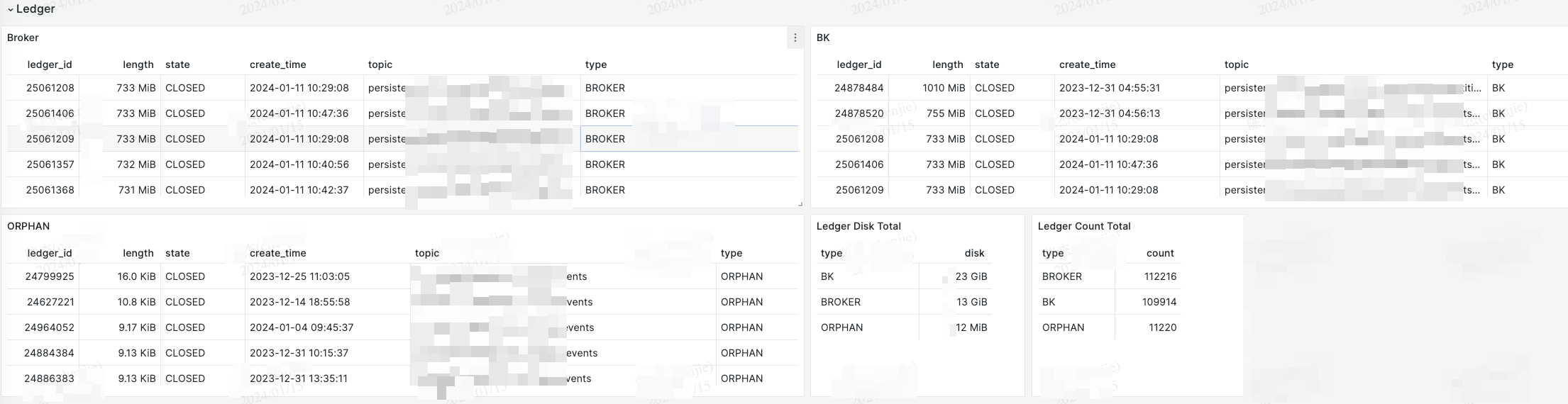
这里我利用 Pulsar 和 Bookkeeper 的 Admin API 列出了 Broker 和 BK 中 Ledger 分别占用的磁盘空间。
关于这个如何获取和计算的,后续也准备提交给社区。
背景
但和我们实际 kubernetes 中的磁盘占用量依然对不上,所以就想看看在 BK 中实际的存储日志和 Ledger 到底差在哪里。
知道 Ledger 就可以通过 Ledger 的元数据中找到对应的 topic,从而判断哪些 topic 的数据导致统计不能匹配。
Bookkeeper 有提提供一个Admin API 可以返回当前 BK 所使用了哪些日志文件的接口:
https://bookkeeper.apache.org/docs/admin/http#endpoint-apiv1bookielist_disk_filefile_typetype

从返回的结果可以看出,落到具体的磁盘上只有一个文件名称,是无法知道具体和哪些 Ledger 进行关联的,也就无法知道具体的 topic 了。
此时只能大胆假设,应该每个文件和具体的消息 ID 有一个映射关系,也就是索引。
所以需要搞清楚这个索引是如何运行的。
存储模型
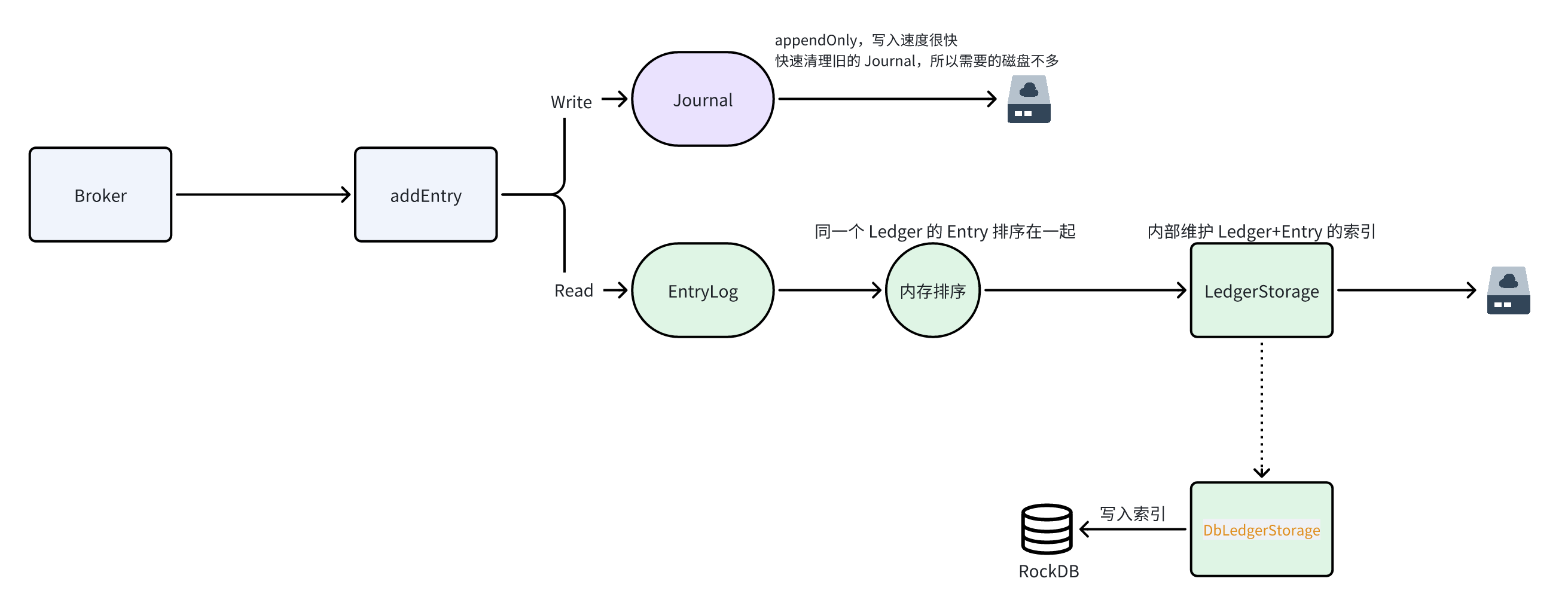
我查阅了一些网上的文章和源码大概梳理了一个存储流程:
- BK 收到写入请求,数据会异步写入到
Journal/Entrylog - Journal 直接顺序写入,并且会快速清除已经写入的数据,所以需要的磁盘空间不多(所以从监控中其实可以看到 Journal 的磁盘占有率是很低的)。
- 考虑到会随机读消息,EntryLog 在写入前进行排序,保证落盘的数据中同一个 Ledger 的数据尽量挨在一起,充分利用 PageCache.
- 最终数据的索引通过
LedgerId+EntryId生成索引信息存放到RockDB中(Pulsar的场景使用的是DbLedgerStorage实现)。 - 读取数据时先从获取索引,然后再从磁盘读取数据。
- 利用
Journal和EntryLog实现消息的读写分离。
简单来说 BK 在存储数据的时候会进行双写,Journal 目录用于存放写的数据,对消息顺序没有要求,写完后就可以清除了。
而 Entry 目录主要用于后续消费消息进行读取使用,大部分场景都是顺序读,毕竟我们消费消息的时候很少会回溯,所以需要充分利用磁盘的 PageCache,将顺序的消息尽量的存储在一起。
同一个日志文件中可能会存放多个 Ledger 的消息,这些数据如果不排序直接写入就会导致乱序,而消费时大概率是顺序的,但具体到磁盘的表现就是随机读了,这样读取效率较低。
所以我们使用 Helm 部署 Bookkeeper 的时候需要分别指定 journal 和 ledgers 的目录
volumes:
# use a persistent volume or emptyDir
persistence: true
journal:
name: journal
size: 20Gi
local_storage: false
multiVolumes:
- name: journal0
size: 10Gi
# storageClassName: existent-storage-class
mountPath: /pulsar/data/bookkeeper/journal0
- name: journal1
size: 10Gi
# storageClassName: existent-storage-class
mountPath: /pulsar/data/bookkeeper/journal1
ledgers:
name: ledgers
size: 50Gi
local_storage: false
storageClassName: sc
# storageClass:
# ... useMultiVolumes: false
multiVolumes:
- name: ledgers0
size: 1000Gi
# storageClassName: existent-storage-class
mountPath: /pulsar/data/bookkeeper/ledgers0
- name: ledgers1
size: 1000Gi
# storageClassName: existent-storage-class
mountPath: /pulsar/data/bookkeeper/ledgers1
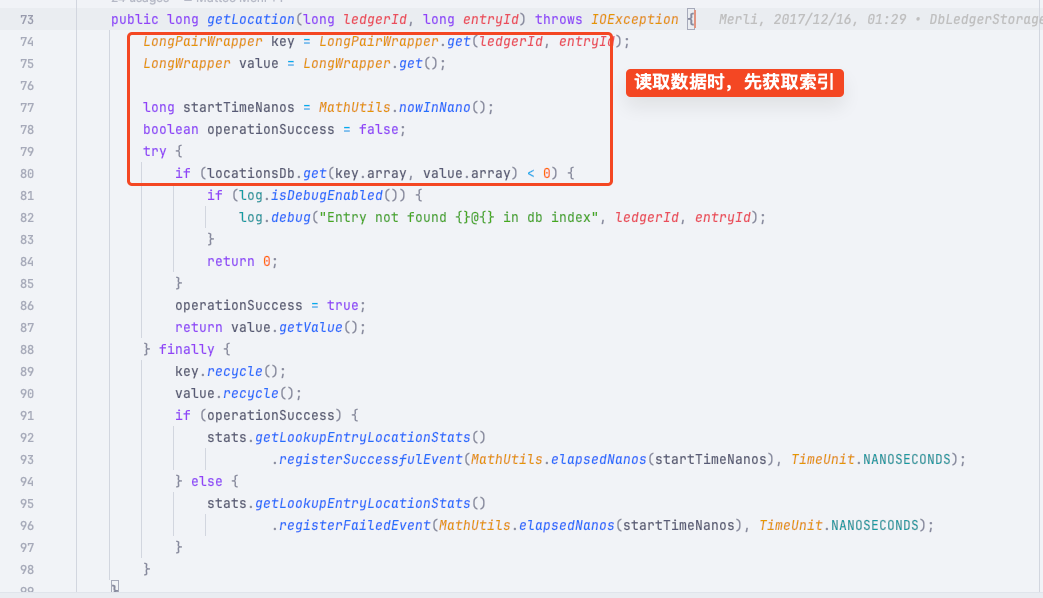
每次在写入和读取数据的时候都需要通过消息 ID 也就是 ledgerId 和 entryId 来获取索引信息。
也印证了之前索引的猜测。
所以借助于 BK 读写分离的特性,我们还可以单独优化存储。
比如写入 Journal 的磁盘因为是顺序写入,所以即便是普通的 HDD 硬盘速度也很快。
大部分场景下都是读大于写,所以我们可以单独为 Ledger 分配高性能 SSD 磁盘,按需使用。
因为在最底层的日志文件中无法直接通过 ledgerId 得知占用磁盘的大小,所以我们实际的磁盘占用率对不上的问题依然没有得到解决,这个问题我还会持续跟进,有新的进展再继续同步。
白话 Pulsar Bookkeeper 的存储模型的更多相关文章
- 翟佳:高可用、强一致、低延迟——BookKeeper的存储实现
分享嘉宾:翟佳 StreamNative 联合创始人 编辑整理:张晓伟 美团点评 出品平台:DataFunTalk 导读:多数读者们了解BookKeeper是通过Pulsar,实际上BookKeepe ...
- Entity Framework 6 Recipes 2nd Edition(10-5)译 -> 在存储模型中使用自定义函数
10-5. 在存储模型中使用自定义函数 问题 想在模型中使用自定义函数,而不是存储过程. 解决方案 假设我们数据库里有成员(members)和他们已经发送的信息(messages) 关系数据表,如Fi ...
- SQLite剖析之存储模型
前言 SQLite作为嵌入式数据库,通常针对的应用的数据量相对于DBMS的数据量小.所以它的存储模型设计得非常简单,总的来说,SQLite把一个数据文件分成若干大小相等的页面,然后以B树的形式来组织这 ...
- Bitcask 存储模型
Bitcask 存储模型 Bitcask 是一个日志型.基于hash表结构的key-value存储模型,以Bitcask为存储模型的K-V系统有 Riak和 beansdb新版本. 日志型数据存储 何 ...
- LSM存储模型
LSM存储模型 数据库有3种基本的存储引擎: 哈希表,支持增.删.改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统.对于key-value的插入以及查询,哈希表的复杂度 ...
- SQLite入门与分析(八)---存储模型(1)
写在前面:SQLite作为嵌入式数据库,通常针对的应用的数据量相对于通常DBMS的数据量是较小的.所以它的存储模型设计得非常简单,总的来说,SQLite把一个数据文件分成若干大小相等的页面,然后以B树 ...
- LSM树存储模型
----<大规模分布式存储系统:原理解析与架构实战>读书笔记 之前研究了Bitcask存储模型,今天来看看LSM存储模型,两者尽管同属于基于键值的日志型存储模型.可是Bitcask使用哈希 ...
- 剖析Elasticsearch集群系列第一篇 Elasticsearch的存储模型和读写操作
剖析Elasticsearch集群系列涵盖了当今最流行的分布式搜索引擎Elasticsearch的底层架构和原型实例. 本文是这个系列的第一篇,在本文中,我们将讨论的Elasticsearch的底层存 ...
- 剖析Elasticsearch集群系列之一:Elasticsearch的存储模型和读写操作
转载:http://www.infoq.com/cn/articles/analysis-of-elasticsearch-cluster-part01 1.辨析Elasticsearch的索引与Lu ...
- 并发编程学习笔记之Java存储模型(十三)
概述 Java存储模型(JMM),安全发布.规约,同步策略等等的安全性得益于JMM,在你理解了为什么这些机制会如此工作后,可以更容易有效地使用它们. 1. 什么是存储模型,要它何用. 如果缺少同步,就 ...
随机推荐
- HTTP响应状态码([RFC9110])
本内容翻译自[RFC9110]15. Status Codes,不足之处请自行查阅文档. 15. 状态码 响应的状态码是一个三位整数代码,用于描述请求的结果和响应的语义,包括请求是否成功以及附带了什么 ...
- 【python】无法安装pip,报错ImportError: No module named 'pip'解决方案
命令提示符输入以下代码即可 python -m ensurepip
- Salesforce LWC学习(四十六) 自定义Datatable实现cell onclick功能
本篇参考:https://developer.salesforce.com/docs/component-library/bundle/lightning-datatable 背景:我们有时会有这种类 ...
- NestJs系列之使用Vite搭建项目
介绍 在使用nest创建项目时,默认使用webpack进行打包,有时候启动项目需要1-2分钟.所以希望采用vite进行快速启动项目进行开发. 本文主要使用NestJs.Vite和swc进行配置.文章实 ...
- Markdown References
每次写文章,用到都要查一下的Markdown语法 字体颜色 [Markdown笔记]设置字体颜色 字体颜色 Font colors Decrsiption Demonstration Effect 选 ...
- JXNU acm选拔赛 不安全字符串
不安全字符串 Time Limit : 3000/1000ms (Java/Other) Memory Limit : 65535/32768K (Java/Other) Total Submis ...
- ZincSearch轻量级全文搜索引擎入门到
ZincSearch轻量级全文搜索引擎入门到 Zinc是一个用于对文档进行全文搜索的搜索引擎.它是开源的,内置在 Go 中.Zinc不是从头开始构建索引引擎,而是构建在 bluge 之上,这是一个出色 ...
- Kubernetes Service 中的 external-traffic-policy 是什么?
[摘要] external-traffic-policy,顾名思义"外部流量策略",那这个配置有什么作用呢?以及external是指什么东西的外部呢,集群.节点.Pod?今天我们就 ...
- 2023“强网杯”部分WP
强网先锋 SpeedUp 题目 我的解答: 分析代码可知是求2的27次方的阶乘的每一位的和. 使用在线网址直接查看:https://oeis.org/A244060/list 然后sha256加密 f ...
- java中获取公网IP
package com.dashan.utils.iputils; import org.apache.commons.lang.StringUtils; import java.io.Buffere ...