白话 Pulsar Bookkeeper 的存储模型

最近我们的 Pulsar 存储有很长一段时间数据一直得不到回收,但消息确实已经是 ACK 了,理论上应该是会被回收的,随着时间流逝不但没回收还一直再涨,最后在没找到原因的情况下就只有一直不停的扩容。
最后磁盘是得到了回收,过程先不表,之后再讨论。
为了防止类似的问题再次发生,我们希望可以监控到磁盘维度,能够列出各个日志文件的大小以及创建时间。
这时就需要对 Pulsar 的存储模型有一定的了解,也就有了这篇文章。
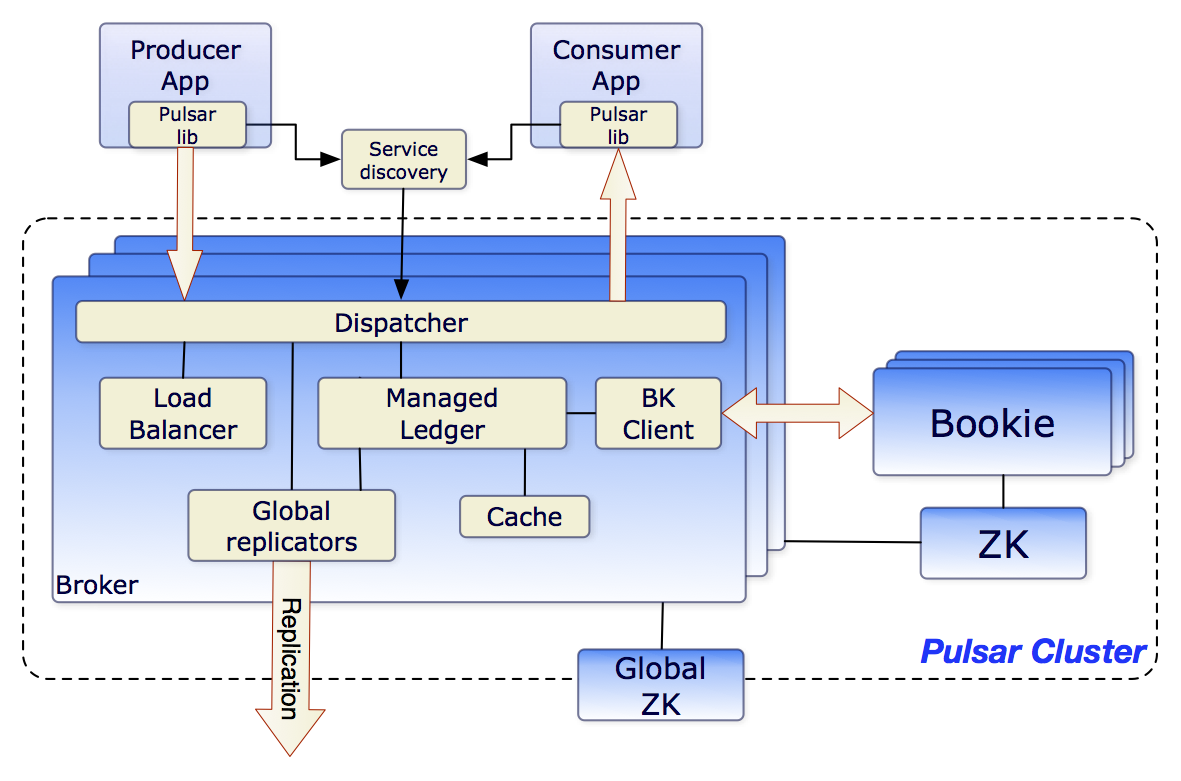
讲到 Pulsar 的存储模型,本质上就是 Bookkeeper 的存储模型。
Pulsar 所有的消息读写都是通过 Bookkeeper 实现的。
Bookkeeper是一个可扩展、可容错、低延迟的日志存储数据库,基于 Append Only 模型。(数据只能追加不能修改)
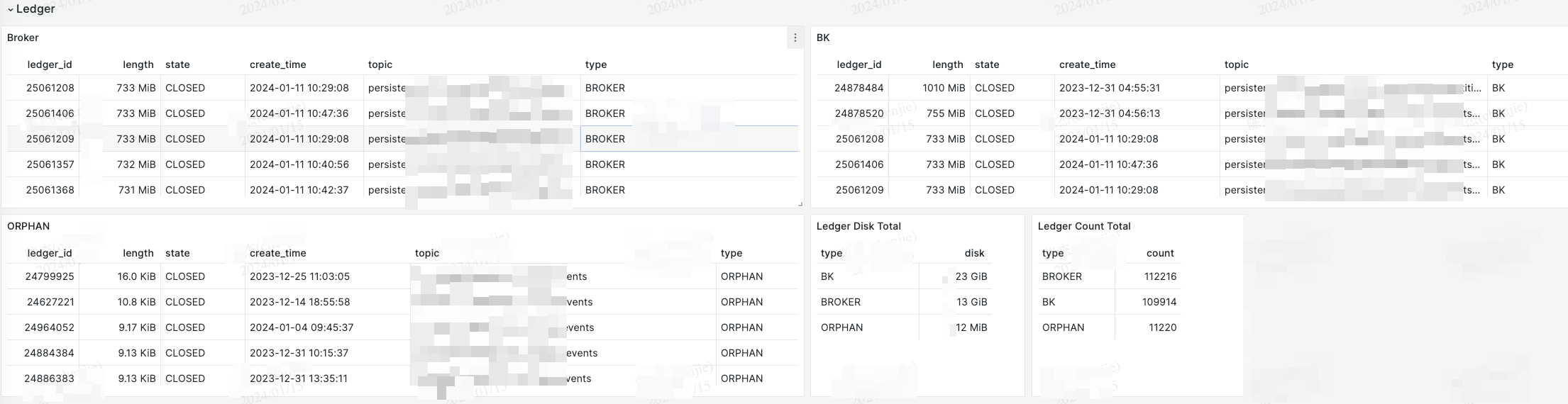
这里我利用 Pulsar 和 Bookkeeper 的 Admin API 列出了 Broker 和 BK 中 Ledger 分别占用的磁盘空间。
关于这个如何获取和计算的,后续也准备提交给社区。
背景
但和我们实际 kubernetes 中的磁盘占用量依然对不上,所以就想看看在 BK 中实际的存储日志和 Ledger 到底差在哪里。
知道 Ledger 就可以通过 Ledger 的元数据中找到对应的 topic,从而判断哪些 topic 的数据导致统计不能匹配。
Bookkeeper 有提提供一个Admin API 可以返回当前 BK 所使用了哪些日志文件的接口:
https://bookkeeper.apache.org/docs/admin/http#endpoint-apiv1bookielist_disk_filefile_typetype

从返回的结果可以看出,落到具体的磁盘上只有一个文件名称,是无法知道具体和哪些 Ledger 进行关联的,也就无法知道具体的 topic 了。
此时只能大胆假设,应该每个文件和具体的消息 ID 有一个映射关系,也就是索引。
所以需要搞清楚这个索引是如何运行的。
存储模型
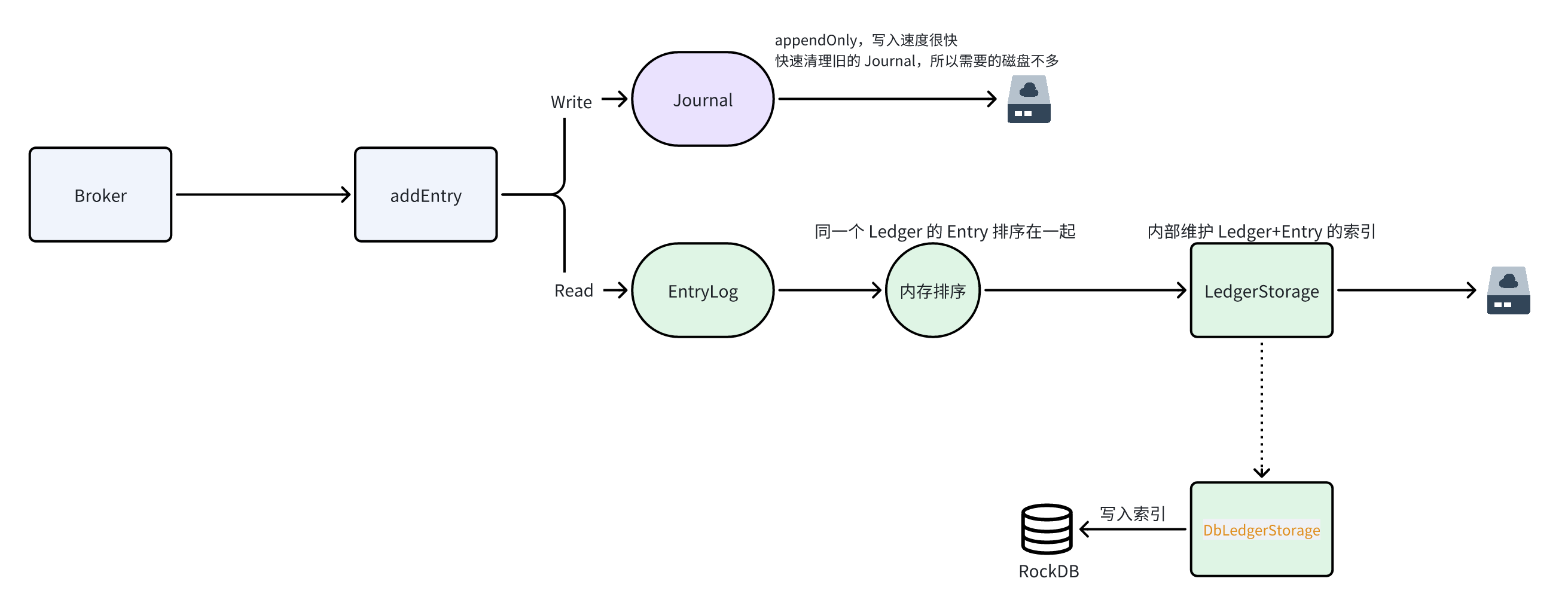
我查阅了一些网上的文章和源码大概梳理了一个存储流程:
- BK 收到写入请求,数据会异步写入到
Journal/Entrylog - Journal 直接顺序写入,并且会快速清除已经写入的数据,所以需要的磁盘空间不多(所以从监控中其实可以看到 Journal 的磁盘占有率是很低的)。
- 考虑到会随机读消息,EntryLog 在写入前进行排序,保证落盘的数据中同一个 Ledger 的数据尽量挨在一起,充分利用 PageCache.
- 最终数据的索引通过
LedgerId+EntryId生成索引信息存放到RockDB中(Pulsar的场景使用的是DbLedgerStorage实现)。 - 读取数据时先从获取索引,然后再从磁盘读取数据。
- 利用
Journal和EntryLog实现消息的读写分离。
简单来说 BK 在存储数据的时候会进行双写,Journal 目录用于存放写的数据,对消息顺序没有要求,写完后就可以清除了。
而 Entry 目录主要用于后续消费消息进行读取使用,大部分场景都是顺序读,毕竟我们消费消息的时候很少会回溯,所以需要充分利用磁盘的 PageCache,将顺序的消息尽量的存储在一起。
同一个日志文件中可能会存放多个 Ledger 的消息,这些数据如果不排序直接写入就会导致乱序,而消费时大概率是顺序的,但具体到磁盘的表现就是随机读了,这样读取效率较低。
所以我们使用 Helm 部署 Bookkeeper 的时候需要分别指定 journal 和 ledgers 的目录
volumes:
# use a persistent volume or emptyDir
persistence: true
journal:
name: journal
size: 20Gi
local_storage: false
multiVolumes:
- name: journal0
size: 10Gi
# storageClassName: existent-storage-class
mountPath: /pulsar/data/bookkeeper/journal0
- name: journal1
size: 10Gi
# storageClassName: existent-storage-class
mountPath: /pulsar/data/bookkeeper/journal1
ledgers:
name: ledgers
size: 50Gi
local_storage: false
storageClassName: sc
# storageClass:
# ... useMultiVolumes: false
multiVolumes:
- name: ledgers0
size: 1000Gi
# storageClassName: existent-storage-class
mountPath: /pulsar/data/bookkeeper/ledgers0
- name: ledgers1
size: 1000Gi
# storageClassName: existent-storage-class
mountPath: /pulsar/data/bookkeeper/ledgers1
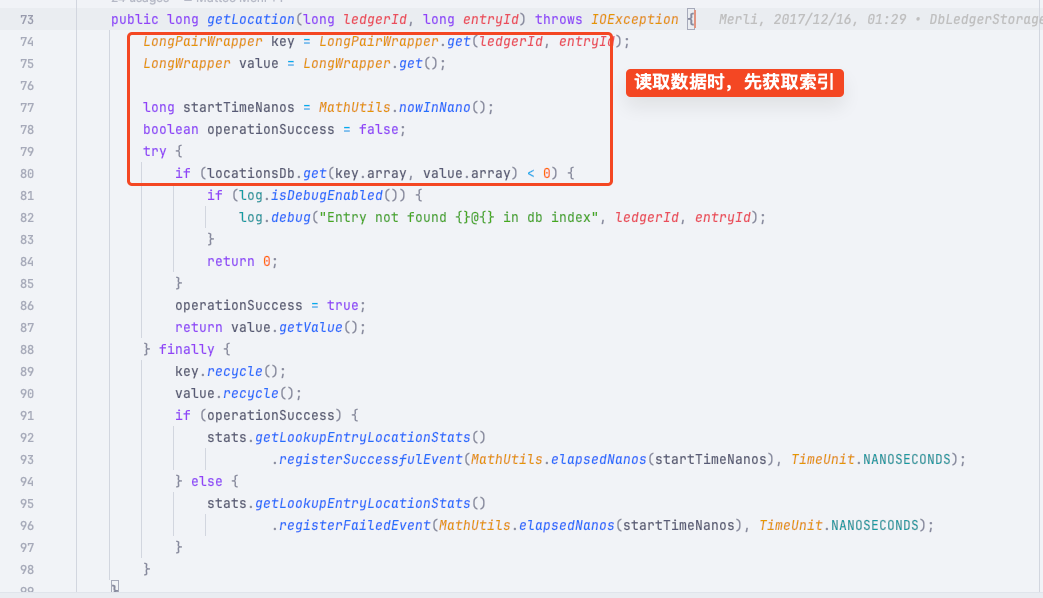
每次在写入和读取数据的时候都需要通过消息 ID 也就是 ledgerId 和 entryId 来获取索引信息。
也印证了之前索引的猜测。
所以借助于 BK 读写分离的特性,我们还可以单独优化存储。
比如写入 Journal 的磁盘因为是顺序写入,所以即便是普通的 HDD 硬盘速度也很快。
大部分场景下都是读大于写,所以我们可以单独为 Ledger 分配高性能 SSD 磁盘,按需使用。
因为在最底层的日志文件中无法直接通过 ledgerId 得知占用磁盘的大小,所以我们实际的磁盘占用率对不上的问题依然没有得到解决,这个问题我还会持续跟进,有新的进展再继续同步。
白话 Pulsar Bookkeeper 的存储模型的更多相关文章
- 翟佳:高可用、强一致、低延迟——BookKeeper的存储实现
分享嘉宾:翟佳 StreamNative 联合创始人 编辑整理:张晓伟 美团点评 出品平台:DataFunTalk 导读:多数读者们了解BookKeeper是通过Pulsar,实际上BookKeepe ...
- Entity Framework 6 Recipes 2nd Edition(10-5)译 -> 在存储模型中使用自定义函数
10-5. 在存储模型中使用自定义函数 问题 想在模型中使用自定义函数,而不是存储过程. 解决方案 假设我们数据库里有成员(members)和他们已经发送的信息(messages) 关系数据表,如Fi ...
- SQLite剖析之存储模型
前言 SQLite作为嵌入式数据库,通常针对的应用的数据量相对于DBMS的数据量小.所以它的存储模型设计得非常简单,总的来说,SQLite把一个数据文件分成若干大小相等的页面,然后以B树的形式来组织这 ...
- Bitcask 存储模型
Bitcask 存储模型 Bitcask 是一个日志型.基于hash表结构的key-value存储模型,以Bitcask为存储模型的K-V系统有 Riak和 beansdb新版本. 日志型数据存储 何 ...
- LSM存储模型
LSM存储模型 数据库有3种基本的存储引擎: 哈希表,支持增.删.改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统.对于key-value的插入以及查询,哈希表的复杂度 ...
- SQLite入门与分析(八)---存储模型(1)
写在前面:SQLite作为嵌入式数据库,通常针对的应用的数据量相对于通常DBMS的数据量是较小的.所以它的存储模型设计得非常简单,总的来说,SQLite把一个数据文件分成若干大小相等的页面,然后以B树 ...
- LSM树存储模型
----<大规模分布式存储系统:原理解析与架构实战>读书笔记 之前研究了Bitcask存储模型,今天来看看LSM存储模型,两者尽管同属于基于键值的日志型存储模型.可是Bitcask使用哈希 ...
- 剖析Elasticsearch集群系列第一篇 Elasticsearch的存储模型和读写操作
剖析Elasticsearch集群系列涵盖了当今最流行的分布式搜索引擎Elasticsearch的底层架构和原型实例. 本文是这个系列的第一篇,在本文中,我们将讨论的Elasticsearch的底层存 ...
- 剖析Elasticsearch集群系列之一:Elasticsearch的存储模型和读写操作
转载:http://www.infoq.com/cn/articles/analysis-of-elasticsearch-cluster-part01 1.辨析Elasticsearch的索引与Lu ...
- 并发编程学习笔记之Java存储模型(十三)
概述 Java存储模型(JMM),安全发布.规约,同步策略等等的安全性得益于JMM,在你理解了为什么这些机制会如此工作后,可以更容易有效地使用它们. 1. 什么是存储模型,要它何用. 如果缺少同步,就 ...
随机推荐
- Petals
------------恢复内容开始------------ 打开发现一堆地址冒红 滑倒后面发现E8,根据经验应该是花指令考点 然后D-->nop-->C-->P得到正常结果 然后第 ...
- FPGA常用IP核
前言: 芯片行业中的IP,一般称为IP(Intellectual Property)核,是具有知识产权核的集成电路芯核的总称.说白了就是厂家实现的具有特定功能工具,然后我们可以直接调用,就相当于是函数 ...
- Object.assign () 和深拷贝
先看看啥叫深拷贝?啥叫浅拷贝? 假设B复制了A,修改A的时候,看B是否发生变化: 如果B跟着也变了,说明是浅拷贝,拿人手短!(修改堆内存中的同一个值) 如果B没有改变,说明是深拷贝,自食其力!(修改堆 ...
- execl表格if函数and和or的使用方法?
当在Excel中处理数据时,IF函数是非常有用的函数之一.它允许您根据指定的条件执行不同的操作.在IF函数中,AND和OR函数可以帮助您组合多个条件以实现更复杂的逻辑判断.接下来,我将详细描述IF函数 ...
- [ABC299F] Square Subsequence
Problem Statement You are given a string $S$ consisting of lowercase English letters. Print the numb ...
- SpringBoot整合Swagger3
1.导入相关依赖 <!--swagger--> <dependency> <groupId>io.springfox</groupId> <art ...
- eclipse工具使用
eclipse下载 官网下载:https://www.eclipse.org/downloads/packages/ 打开后,找到Eclipse IDE for Java Developers点击进入 ...
- MinIO的简单使用
MINIO介绍 什么是对象存储? 以阿里云OSS为例: 对象存储服务OSS(Object Storage Service)是一种海量.安全.低成本.高可靠的云存储服务,适合存放任意类型的文件.容量和处 ...
- libGDX游戏开发之修改游戏帧数FPS(十三)
libGDX游戏开发之修改游戏帧数FPS(十三) libGDX系列,游戏开发有unity3D巴拉巴拉的,为啥还用java开发?因为我是Java程序员emm-国内用libgdx比较少,多数情况需要去官网 ...
- cookie的一些知识点总结
一.cookie的种类 sessionID 这个ID是会话性的,只要关闭了当前浏览器,这个ID会消失,需要调用getSessoin重新获取一个新的session 会话性cookie 这个cookie也 ...