火山引擎DataLeap的Catalog系统搜索实践 (二):整体架构
整体架构
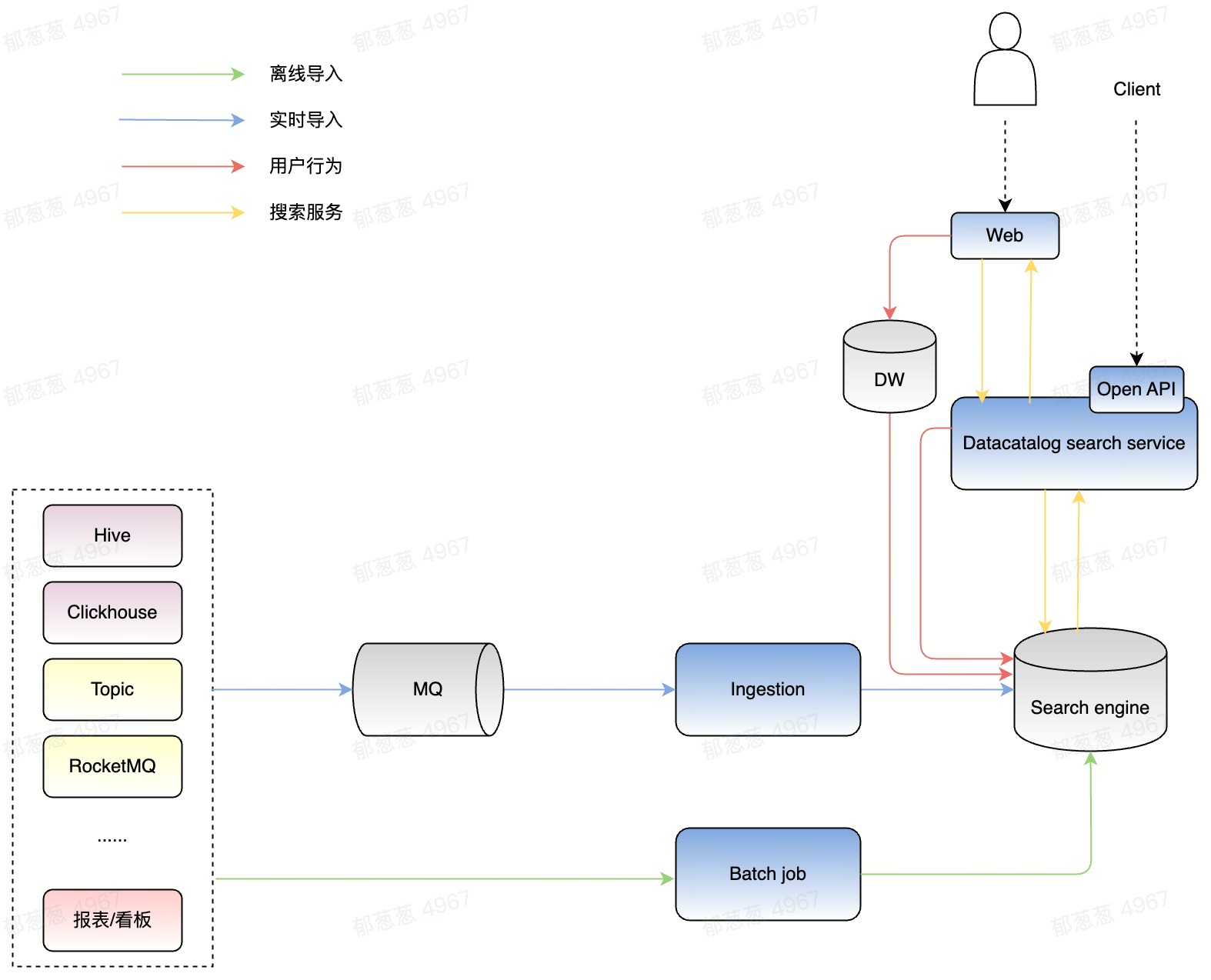
- 实时导入。资产元数据变更时相应的平台发出实时变更消息,Data Catalog系统会消费变更消息,通过ingestion服务更新Elasticsearch中的文档,以此来达到搜索实时性秒级的需求。
- 离线导入。实时导入的过程中可能会遇到网络波动等不可控因素导致更新失败,因此需要定时的任务来检查和增量更新缺失的元数据。
- 用户行为记录。记录用户搜索点击日志,用来后续进行搜索的Badcase review和模型训练。火山引擎DataLeap的Catalog系统这部分采用了前端埋点和服务端埋点结合的方式。前端埋点有成熟的内部框架,埋点数据流入离线数仓表,缺点是这部分数据要经过离线任务T+1才能使用。服务端埋点数据直接进入Elasticsearch,即时可用,同时在不支持前端埋点的场景(如ToB场景),可以成为主要的埋点数据收集方式。
- 线上搜索服务。提供搜索相关的线上服务,在后文详细解释这部分。
服务架构

- 搜索推荐服务(Type as you search)。搜索推荐服务对性能有一定的要求,通常来说补全的请求完成时间不能超过200ms,超过了用户就会有比较明显的延迟感。因此不能直接使用搜索接口实现,我们的系统里是基于Elasticsearch的Context suggester实现的。除此之外,还有两个问题需要重点考虑:
- 基于浏览的热度排序。页面上能够推荐的词数是有限的,通常是10个,在输入较短时,候选的推荐词通常会超过这个限制,因此通过资产的浏览热度来排序可以提高搜索推荐的准确率,改善用户的搜索体验。
- 时序问题。一次搜索过程中会有一连串的搜索推荐请求,服务端会并行的处理这些请求,通常更长的输入由于候选推荐词更少服务端响应反而更快,在用户输入较快的时候(比如连续的删除字符),前端先发出的请求可能会后返回,因此可能造成输入停止后推荐的词与输入不匹配。我们的方案是前端在根据服务端响应刷新数据时需要检查返回的输入与当前输入框内容是否一致,从而保持最终一致性。
- 聚合服务。火山引擎DataLeap的Catalog系统的聚合服务根据输入和筛选项提供搜索过程中需要用到的统计数字。例如用户希望知道搜索结果总共有多少条,每个筛选项下有多少个候选结果等统计信息,从而指导用户对搜索结果进行筛选,缩小搜索范围。同时,每个筛选项下的可选项需要根据输入和其它关联的筛选值动态生成,这部分也需要聚合服务提供。
- 搜索服务。支持核心的搜索过程,通过输入,返回对应的资产作为搜索结果。分为4个主要的部分。
- 预处理过程(Preprocess),主要包含对输入的预处理和用户信息的预处理。
- 对输入的预处理主要包括分词,停用,词性还原等基本的文本处理。分词主要包含英文分词和中文分词。英文分词需要处理-_等链接符分词,中文分词主要是用IK分词器。停用主要包含各种词如“的”,“了”,“我”和各种特殊符号“》〉?”等无意义的词语。词性还原是一把双刃剑,因为Data Catalog中的词语不同于一般的自然语言,有比较多的专有名词,比如live listing不应当被还原为live list,避免文本匹配的分数不准。同时这部分也包含对输入中的强pattern进行识别,如"数据库名.表名”等。
- 对用户信息的预处理。用户是否为超级用户,是否为API用户等,可以借此判断用户常搜索的资产类型或从未搜索的资产类型。
- 召回过程(Recall),负责通过输入和筛选项根据文本相关度从Elasticsearch查询一定数量的搜索候选结果,供下一步精排使用。召回过程需要保证用户期望的结果包含在召回结果中,否则后续排序优化都是徒劳。同时,火山引擎DataLeap 的Catalog系统召回的数量需要限制在合理的数值。主要原因有两点:一是排序靠后的搜索结果几乎没有用户会查看。二是召回过多的候选结果会影响性能,尤其是排序性能消耗比较大时。我们的召回主要分为两种方式:自然召回和强规则召回。
- 自然召回。对经过预处理的输入进行不同资产类型的召回,使用best field的策略,对资产的不同字段设置不同的权重,例如命中名称的资产应当比命中描述的资产优先级高。这里的权重通常根据经验设置,可以根据搜索结果的Badcase review得到,这个权重数值的精度要求不高,确保期望的结果能召回回来即可。
- 强规则召回。可以定制一些规则,作为自然召回的补充,涵盖精确表名的召回,或者从用户的常用资产列表进行召回。
除此之外,还需要做好多租户的隔离,避免当前租户的用户召回其它租户的资产。 - 精排过程(Rank),负责对召回的结果进行最终的排序。精排过程依次包含机器学习模型预测(Learning to rank)和基于规则调整两部分。Learning to rank部分详细介绍见后文。
- 机器学习模型在线预测,负责主要的排序工作。加载离线训练得到的PMML模型文件,提供预测功能。
- 基于强规则的调整,包含排序的各种兜底策略,比较常用的有:
- 精确匹配的结果排在第一位。
- 添加Tie-breaker,保证分数相同的结果多次搜索的排序一致。
- 后处理过程(Postprocess),对排好序的结果添加各种不影响顺序的后处理。例如:
- 权限检查,隐藏表设置。一些资产不希望被没有相关权限的用户查看详情,需要在搜索结果中设置相应字段并返回给前端。
- 高亮,对命中字段进行高亮标注,返回给前端。
火山引擎DataLeap的Catalog系统搜索实践 (二):整体架构的更多相关文章
- 如何又快又好实现 Catalog 系统搜索能力?火山引擎 DataLeap 这样做
摘要 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理.资产.安全等全套数据中台建设,降低工作成本和数据维护成本.挖掘数据价 ...
- 火山引擎 DataLeap:揭秘字节跳动数据血缘架构演进之路
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维 ...
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- 火山引擎 DataLeap:一家企业,数据体系要怎么搭建?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 导读:经过十多年的发展,数据治理在传统行业以及新兴互联网公司都已经产生落地实践.字节跳动也在探索一种分布式的数据治 ...
- 火山引擎DataLeap数据调度实例的 DAG 优化方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 实例 DAG 介绍 DataLeap 是火山引擎自研的一站式大数据中台解决方案,集数据集成.开发.运维.治理.资产管理能力 ...
- 字节跳动构建Data Catalog数据目录系统的实践(上)
作为数据目录产品,Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景,并服务于数据开发和数据治理的产品体系.本文介绍了字节跳动 Data ...
- 还原火山引擎 A/B 测试产品——DataTester 私有化部署实践经验
作为一款面向ToB市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向ToB客户私有化的实际落地中,火 ...
- JuiceFS 在火山引擎边缘计算的应用实践
火山引擎边缘云是以云计算基础技术和边缘异构算力结合网络为基础,构建在边缘大规模基础设施之上的云计算服务,形成以边缘位置的计算.网络.存储.安全.智能为核心能力的新一代分布式云计算解决方案. 01- 边 ...
- 火山引擎 A/B 测试产品——DataTester 私有化架构分享
作为一款面向 ToB 市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向 ToB 客户私有化的实际落地中,火 ...
随机推荐
- DOM级别
DOM1 DOM1级由两个模块组成:DOM核心(DOM CORE)和DOM HTML.其中,DOM核心规定的是如何映射基于XML的文档结构,以便简化对文档中任意部分的访问和操作.DOM HTML模块则 ...
- games101-1 光栅化与光线追踪中的空间变换
在学习了一些games101的课程之后,我还是有点困惑,对于计算机图形学的基础知识,总感觉还是缺乏一些更加全面的认识,幸而最*在做games101的第五次作业时,查询资料找到了scratchpixel ...
- 比STL还STL?——更全面的解析!
如何更快的使用高级数据结构 Part 1 :__gnu_pbds 库 __gnu_pbds 自带了封装好了的平衡树.字典树.hash等强有力的数据结构,常数还比自己写的小,效率更高 一.平衡树 #de ...
- 音色逼真、韵律自然的AI人声克隆限时福利!
声音,为数字人注入灵魂. 2023云栖大会上,阿里云视频云接受了CCTV-2财经频道的采访,分享并演示了如何利用云端智能剪辑,一站式完成数字人渲染及视频精编二创. 正如视频开头所呈现的AI重现演员&q ...
- echarts官网文档打开慢的解决方法
echarts官网文档打开慢的解决方法由于我们在做大数据屏的时候需要很多echarts图表,这个过程中也会遇到需要查询echarts官网文档.手册.配置项的时候,但是由于网站在国外,访问很慢或者打不开 ...
- 用EXCEL VBA 做的学生成绩分析系统
标题:基于EXCEL VBA的学生成绩分析系统--详细介绍与说明导言:学生成绩分析对于教育机构和学生个体来说具有重要意义.本文将详细介绍基于EXCEL VBA的学生成绩分析系统的设计与实现.通过该系统 ...
- SpringCore完整学习教程4,入门级别
本章从第4章开始 4. Logging Spring Boot使用Commons Logging进行所有内部日志记录,但保留底层日志实现开放.为Java Util Logging.Log4J2和Log ...
- ubuntu 20.04安装mysql5.7
ubuntu 22.04系统安装mysql5.7 一.查看系统默认安装的数据库版本 apt-get update apt-cache policy mysql-server ubuntu 20.04自 ...
- 在k8s中快速搭建基于Prometheus监控系统
公众号「架构成长指南」,专注于生产实践.云原生.分布式系统.大数据技术分享 前言 K8s本身不包含内置的监控工具,所以市场上有不少这样监控工具来填补这一空白,但是没有一个监控工具有prometheus ...
- MinIO客户端之stat
MinIO提供了一个命令行程序mc用于协助用户完成日常的维护.管理类工作. 官方资料 mc stat 获取指定桶或者对象的信息,包含对象的元数据. 指定桶bkt1,查看信息,命令如下: ./mc st ...