SparkSQL高并发:读取存储数据库
摘要:实践解析如何利用SarkSQL高并发进行读取数据库和存储数据到数据库。
本文分享自华为云社区《SarkSQL高并发读取数据库和存储数据到数据库》,作者:Copy工程师 。
1. SparkSql 高并发读取数据库
SparkSql连接数据库读取数据给了三个API:
//Construct a DataFrame representing the database table accessible via JDBC URL url named table and connection properties.
Dataset<Row> jdbc(String url, String table, java.util.Properties properties)
//Construct a DataFrame representing the database table accessible via JDBC URL url named table using connection properties.
Dataset<Row> jdbc(String url, String table, String[] predicates, java.util.Properties connectionProperties)
//Construct a DataFrame representing the database table accessible via JDBC URL url named table.
Dataset<Row> jdbc(String url, String table, String columnName, long lowerBound, long upperBound, int numPartitions, java.util.Properties connectionProperties)
三个API介绍:
1. 单个分区,单个task执行,无并发
遇到数据量很大的表,抽取速度慢。
实例:
SparkSession sparkSession = SparkSession.builder().appName("SPARK_FENGDING_TASK1").master("local").config("spark.testing.memory", 471859200).getOrCreate();
// 配置连接属性
Properties dbProps = new Properties();
dbProps.put("user","user");
dbProps.put("password","pwd");
dbProps.put("driver","oracle.jdbc.driver.OracleDriver");
// 连接数据库 获取数据 要使用自己的数据库连接串
Dataset<Row> tableDf = sparkSession.read().jdbc("jdbc:oracle:thin:@IP:1521:DEMO", "TABLE_DEMO", dbProps);
// 返回1
tableDf.rdd().getPartitions();
该API的并发数为1,单分区,不管你留给该任务节点多少资源,都只有一个task执行任务
2. 任意字段分区
该API是第二个API,根据设置的分层条件设置并发度:
def jdbc(
url: String,
table: String,
predicates: Array[String], #这个是分层的条件,一个数组
connectionProperties: Properties): DataFrame = {
val parts: Array[Partition] = predicates.zipWithIndex.map { case (part, i) =>
JDBCPartition(part, i) : Partition
}
jdbc(url, table, parts, connectionProperties)
}
实例:
// 设置分区条件 通过入库时间 把 10月和11月 的数据 分两个分区
String[] patitions = {"rksj >= '1569859200' and rksj < '1572537600'","rksj >= '1572537600' and rksj < '1575129600'"};
// 根据StudentId 分15个分区,就会有15个task抽取数据
Dataset<Row> tableDf3 = sparkSession.read().jdbc("jdbc:oracle:thin:@IP:1521:DEMO", "TABLE_DEMO",patitions,dbProps);
// 返回2
tableDf3.rdd().getPartitions();
该API操作相对自由,就是设置分区条件麻烦一点。
3. 根据Long类型字段分区
该API是第三个API,根据设置的分区数并发抽取数据:
def jdbc(
url: String,
table: String,
columnName: String, # 根据该字段分区,需要为整形,比如id等
lowerBound: Long, # 分区的下界
upperBound: Long, # 分区的上界
numPartitions: Int, # 分区的个数
connectionProperties: Properties): DataFrame = {
val partitioning = JDBCPartitioningInfo(columnName, lowerBound, upperBound, numPartitions)
val parts = JDBCRelation.columnPartition(partitioning)
jdbc(url, table, parts, connectionProperties)
}
实例:
// 根据StudentId 分15个分区,就会有15个task抽取数据
Dataset<Row> tableDf2 = sparkSession.read().jdbc("jdbc:oracle:thin:@IP:1521:DEMO", "TABLE_DEMO", "studentId",0,1500,15,dbProps);
// 返回10
tableDf2.rdd().getPartitions();
该操作根据分区数设置并发度,缺点是只能用于Long类型字段。
2. 存储数据到数据库
存储数据库API给了Class DataFrameWriter<T>类,该类有存储到文本,Hive,数据库的API。这里只说数据库的API,提一句,如果保存到Text格式,只支持保存一列。。。就很难受。
实例:
有三种写法
// 第一张写法,指定format类型,使用save方法存储数据库
jdbcDF.write()
.format("jdbc")
.option("url", "jdbc:postgresql:dbserver")
.option("dbtable", "schema.tablename")
.option("user", "username")
.option("password", "password")
.save();
// 第二种写法 使用jdbc写入数据库
jdbcDF2.write()
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties); // 第三种写法,也是使用jdbc,只不过添加createTableColumnTypes,创建表的时候使用该属性字段创建表字段
jdbcDF.write()
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)")
.jdbc("jdbc:postgresql:dbserver", "schema.tablename", connectionProperties);
当我们的表已经存在的时候,使用上面的语句就会报错表已存在,这是因为我们没有指定存储模式,默认是ErrorIfExists
保存模式:
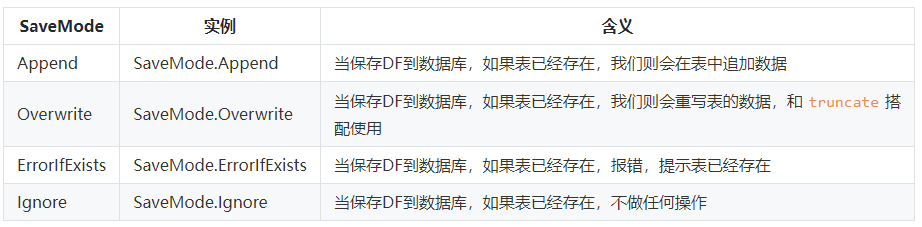
所以一般都是这样用:
tableDf3.write().mode(SaveMode.Append).jdbc("jdbc:oracle:thin:@IP:1521:DEMO", "TABLE_DEMO", connectionProperties);
对于connectionProperties还有很多其他选项:
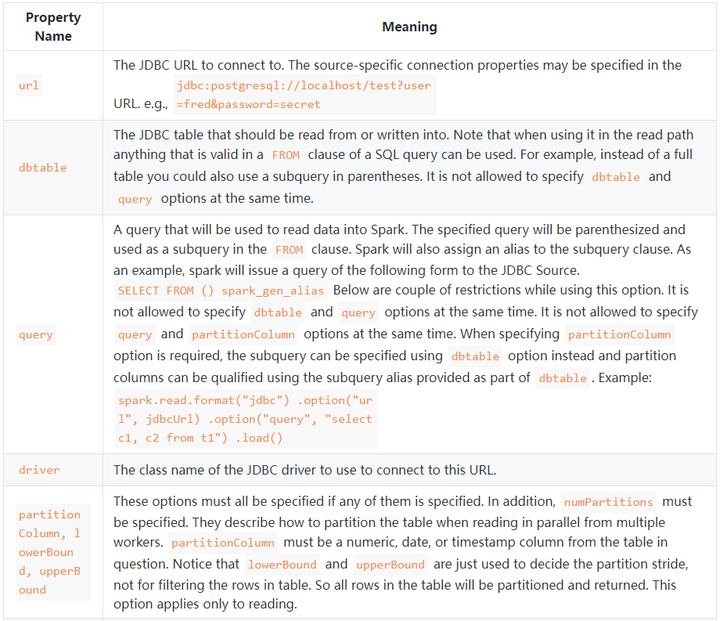

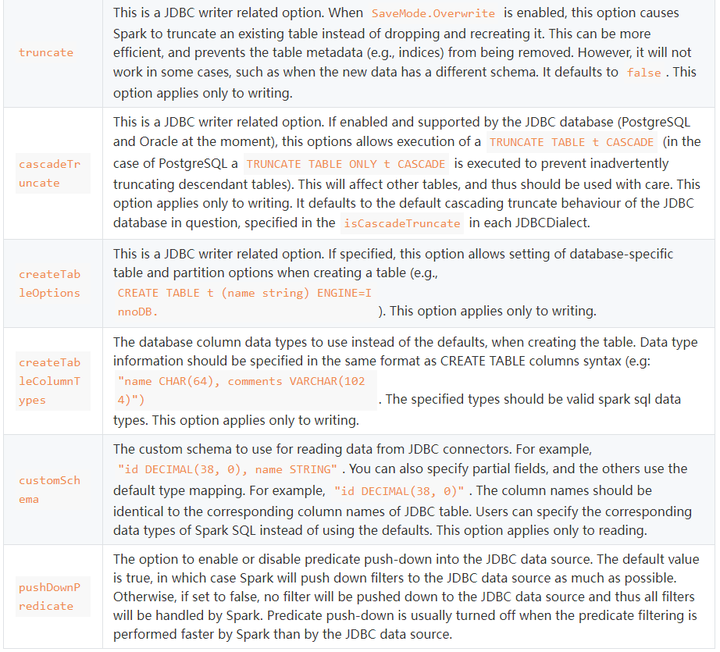
这里面的truncate就是说当使用SaveMode.Overwrite的时候,设置truncate为true,就会对表进行truncate语句清理表,不再是删除表在重建表的操作。
SparkSQL高并发:读取存储数据库的更多相关文章
- 如何在高并发分布式系统中生成全局唯一Id(转)
http://www.cnblogs.com/heyuquan/p/global-guid-identity-maxId.html 又一个多月没冒泡了,其实最近学了些东西,但是没有安排时间整理成博文, ...
- (转)如何在高并发分布式系统中生成全局唯一Id
又一个多月没冒泡了,其实最近学了些东西,但是没有安排时间整理成博文,后续再奉上.最近还写了一个发邮件的组件以及性能测试请看 <NET开发邮件发送功能的全面教程(含邮件组件源码)> ,还弄了 ...
- 【Redis】1、Jedis对管道、事务以及Watch的操作来应对高并发
对于一个互联网平台来说,高并发是经常会遇到的场景.最有代表性的比如秒杀和抢购.高并发会出现三个特点: 1.高并发读取 2.高并发写入(一致性) 3.出现超卖问题 前端如何应对? 1.缓存静态数据,例如 ...
- 高并发分布式系统如何做到唯一Id
又一个多月没冒泡了,其实最近学了些东西,但是没有安排时间整理成博文,后续再奉上.最近还写了一个发邮件的组件以及性能测试请看 <NET开发邮件发送功能的全面教程(含邮件组件源码)> ,还弄了 ...
- Go项目实战:打造高并发日志采集系统(六)
前情回顾 前文我们完成了日志采集系统的日志文件监控,配置文件热更新,协程异常检测和保活机制. 本节目标 本节加入kafka消息队列,kafka前文也介绍过了,可以对消息进行排队,解耦合和流量控制的作用 ...
- SSM实战——秒杀系统之高并发优化
一:高并发点 高并发出现在秒杀详情页,主要可能出现高并发问题的地方有:秒杀地址暴露.执行秒杀操作. 二:静态资源访问(页面)优化——CDN CDN,内容分发网络.我们把静态的资源(html/css/j ...
- 在CentOS上使用Nginx和Tomcat搭建高可用高并发网站
目录 目录 前言 创建CentOS虚拟机 安装Nginx 安装Tomcat 安装lvs和keepalived 反向代理 部署网站 搭建数据库 编写网站项目 解决session一致性 注意 参考资料 前 ...
- Sqlserver 高并发和大数据存储方案
Sqlserver 高并发和大数据存储方案 随着用户的日益递增,日活和峰值的暴涨,数据库处理性能面临着巨大的挑战.下面分享下对实际10万+峰值的平台的数据库优化方案.与大家一起讨论,互相学习提高! ...
- MySQL面试必考知识点:揭秘亿级高并发数据库调优与最佳实践法则
做业务,要懂基本的SQL语句: 做性能优化,要懂索引,懂引擎: 做分库分表,要懂主从,懂读写分离... 数据库的使用,是开发人员的基本功,对它掌握越清晰越深入,你能做的事情就越多. 今天我们用10分钟 ...
- mongodb三种存储引擎高并发更新性能专题测试
背景说明 近期北京理财频道反馈用来存放股市实时数据的MongoDB数据库写响应请求很慢,难以跟上业务写入速度水平.我们分析了线上现场的情况,发现去年升级到SSD磁盘后,数据持久化的磁盘IO开销已经不是 ...
随机推荐
- FWT & FMT(位运算卷积)学习笔记
它们两个的全名叫 快速沃尔什变换(FWT) 和 快速莫比乌斯变换(FMT),用来在 \(O(n\log n)\) 时间复杂度内求位运算卷积. 因为 FMT 能解决的问题是 FWT 的子集,所以这里不讲 ...
- [vue]精宏技术部试用期学习笔记 III
精宏技术部试用期学习笔记(vue) 父子通信 什么是通信 / 为什么要通信 通信即在不同组件之间传输数据 当在 复用组件 时,需要传递不同数据达成不同的表现效果 能够根据其他组件的行动,响应式 的做出 ...
- Wampserver搭建DVWA和sqli-labs问题总结
Wampserver 搭建 DVWA 和 sqli-labs 问题总结 遇到问题解决的思路方法 百度,博客去搜索相关的问题,人工智能 chatgpt 查看官方文档,查看注释. 本次解决方法就是在文档的 ...
- 估值为一亿的AI核心代码
本题要求你实现一个稍微更值钱一点的 AI 英文问答程序,规则是: 无论用户说什么,首先把对方说的话在一行中原样打印出来: 消除原文中多余空格:把相邻单词间的多个空格换成 1 个空格,把行首尾的空格全部 ...
- DP:使用最小花费爬楼梯
数组的每个索引做为一个阶梯,第 i个阶梯对应着一个非负数的体力花费值 cost[i](索引从0开始). 每当你爬上一个阶梯你都要花费对应的体力花费值,然后你可以选择继续爬一个阶梯或者爬两个阶梯. 您需 ...
- Markdown语法入门与进阶指南
一.Markdown简介 Markdown是一种轻量级标记语言,创始人为约翰·格鲁伯(john Gruber).它允许人们使用易读易写的纯文本格式编写文档,然后转换成有效的XHTML(或者HTML)文 ...
- 吉特日化MES & SQL Server中的数据类型
一. 整数数据类型 1.bit bit数据类型是整型,其值只能是0.1或空值.这种数据类型用于存储只有两种可能值的数据,如Yes 或No.True 或False .On 或Off.注意:很省空间的一种 ...
- [ABC263E] Sugoroku 3
Problem Statement There are $N$ squares called Square $1$ though Square $N$. You start on Square $1$ ...
- 'parent.relativePath' of POM com.qbb:log_record_elegant:1.0-SNAPSHOT points at com.qbb:qiu_code instead of org.springframework.boot:spring-boot-starter-parent
完整的错误: 'parent.relativePath' of POM com.qbb:log_record_elegant:1.0-SNAPSHOT (F:\QbbCode\qiu_code\log ...
- logback日志颜色设置
resources下创建logback-spring.xml配置文件,名字必须要叫这个!!! <?xml version="1.0" encoding="UTF-8 ...