论文解读(SentiX)《SentiX: A Sentiment-Aware Pre-Trained Model for Cross-Domain Sentiment Analysis》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文信息
论文标题:SentiX: A Sentiment-Aware Pre-Trained Model for Cross-Domain Sentiment Analysis
论文作者:Jie Zhou, Junfeng Tian, Rui Wang, Yuanbin Wu, Wenming Xiao, Liang He
论文来源:
论文地址:download
论文代码:download
视屏讲解:click
1 介绍
出发点:预先训练好的语言模型已被广泛应用于跨领域的 NLP 任务,如情绪分析,实现了最先进的性能。然而,由于用户在不同域间的情绪表达的多样性,在源域上对预先训练好的模型进行微调往往会过拟合,导致在目标域上的结果较差;
思路:通过大规模 review 数据集的领域不变情绪知识对情感软件语言模型(SENTIX)进行预训练,并将其用于跨领域情绪分析任务,而无需进行微调。本文提出了一些基于现有的标记和句子级别的词汇和注释的训练前任务,如表情符号、情感词汇和评级,而不受人为干扰。进行了一系列的实验,结果表明,该模型具有巨大的优势。
预训练模型在跨域情感分析上存在的问题:
- 现有的预训练模型侧重于通过自监督策略学习语义内容,而忽略了预训练短语的情绪特定知识;
- 在微调阶段,预训练好的模型可能会通过学习过多的特定领域的情绪知识而过拟合源域,从而导致目标域的性能下降;
贡献:
- 提出了 SENTIX 用于跨域情绪分类,以在大规模未标记的多域数据中学习丰富的域不变情绪知识;
- 在标记水平和句子水平上设计了几个预训练目标,通过掩蔽和预测来学习这种领域不变的情绪知识;
- 实验表明,SENTIX 获得了最先进的跨领域情绪分析的性能,并且比 BERT 需要更少的注释数据才能达到等效的性能;
2 方法
2.1 模型框架
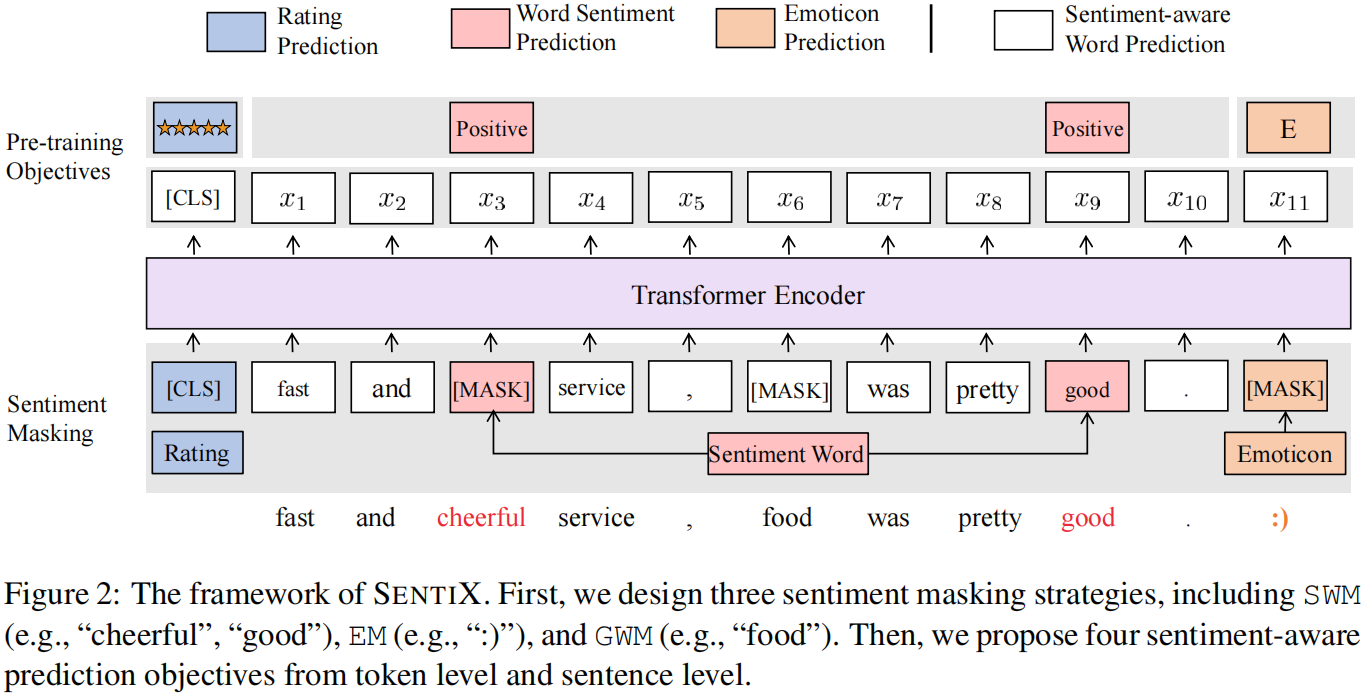
2.2 Sentiment Masking
评论包含了许多半监督的情绪信号,如 情绪词汇、表情符号 和 评级,而大规模的评论数据可以从像 Yelp 这样的在线评论网站上获得。
- 情绪词汇(Sentiment Words):积极(P),消极(N),其他(0);
- 情感符(Emoticons):经常用于表示用户情感的特殊符号,如(“)”、“(”、“:”、“D”),本文选择语料库中经常出现的 100 个特殊符号作为情感符,并将其标记为 “E”,其他为 “0”;
- 评分(Rating):情绪评分分为 5 个等级;
策略:
- Sentiment Word Masking (SWM):为丰富情绪信息,用 30% 的比率掩盖了情绪词;
- Emoticon Masking (EM):由于一个句子中的表情符号数量相对较少,并且删除表情符号不会影响句子的语义信息,所以为每个句子屏蔽了 50% 的表情符号;
- General Word Masking (GWM):如果只关注情感词和表情符号,模型可能会失去其他单词的一般语义信息。因此,使用 [MASK] 并用 15% 的比率替换句子中的一般单词来学习语义信息;
2.3 Pre-training Objectives
$\mathcal{L}_{w}=-\frac{1}{|\hat{\mathcal{X}}|} \sum_{\hat{x} \in \hat{\mathcal{X}}} \frac{1}{|\hat{x}|} \sum_{i=1}^{|\hat{x}|} \log \left(P\left(\left|x_{i}\right| \hat{x}_{i}\right)\right)$
Word Sentiment Prediction (WSP)
根据情感知识,把词的情绪分为积极的、消极的和其他的。因此,设计了 WSP 来学习标记的情感知识。我们的目的是推断单词 $w_{i}$ 的情绪极性 $s_{i}$ 根据 $h_{i}$,$P\left(s_{i} \mid \hat{x_{i}}\right)= \operatorname{Softmax}\left(W_{s} \cdot h_{i}+b_{s}\right) $。这里使用交叉熵损失:
$\mathcal{L}_{s}=-\frac{1}{|\hat{\mathcal{X}}|} \sum_{\hat{x} \in \hat{\mathcal{X}}} \frac{1}{|\hat{x}|} \sum_{i=1}^{|\hat{x}|} \log \left(P\left(s_{i} \mid \hat{x}_{i}\right)\right)$
Rating Prediction (RP)
以上任务侧重于学习 Token 水平的情感知识。评级代表了句子级评论的情绪得分。推断评级将带来句子水平的情感知识。与BERT类似,使用最终状态 $h_{[\mathrm{CLS}]}$ 作为句子表示。该评级由 $P(r \mid \hat{x})=\operatorname{Softmax}\left(W_{r} \cdot h_{[C L S]}+b_{r}\right)$ 进行预测,并根据预测的评级分布计算损失:
$\mathcal{L}_{r}=-\frac{1}{|\hat{\mathcal{X}}|} \sum_{\hat{x} \in \hat{\mathcal{X}}} \log (P(r \mid \hat{x}))$
2.4 Joint Training
$\mathcal{L}=\mathcal{L}_{T}+\mathcal{L}_{S}$
其中:
$\mathcal{L}_{T}=\mathcal{L}_{w}+\mathcal{L}_{s}+\mathcal{L}_{e} $
$\mathcal{L}_{S}=\mathcal{L}_{r}$
3 实验

论文解读(SentiX)《SentiX: A Sentiment-Aware Pre-Trained Model for Cross-Domain Sentiment Analysis》的更多相关文章
- CVPR2020论文解读:三维语义分割3D Semantic Segmentation
CVPR2020论文解读:三维语义分割3D Semantic Segmentation xMUDA: Cross-Modal Unsupervised Domain Adaptation for 3 ...
- VLDB'22 HiEngine极致RTO论文解读
摘要:<Index Checkpoints for Instant Recovery in In-Memory Database Systems>是由华为云数据库创新Lab一作发表在数据库 ...
- itemKNN发展史----推荐系统的三篇重要的论文解读
itemKNN发展史----推荐系统的三篇重要的论文解读 本文用到的符号标识 1.Item-based CF 基本过程: 计算相似度矩阵 Cosine相似度 皮尔逊相似系数 参数聚合进行推荐 根据用户 ...
- CVPR2019 | Mask Scoring R-CNN 论文解读
Mask Scoring R-CNN CVPR2019 | Mask Scoring R-CNN 论文解读 作者 | 文永亮 研究方向 | 目标检测.GAN 推荐理由: 本文解读的是一篇发表于CVPR ...
- AAAI2019 | 基于区域分解集成的目标检测 论文解读
Object Detection based on Region Decomposition and Assembly AAAI2019 | 基于区域分解集成的目标检测 论文解读 作者 | 文永亮 学 ...
- Gaussian field consensus论文解读及MATLAB实现
Gaussian field consensus论文解读及MATLAB实现 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 一.Introduction ...
- zz扔掉anchor!真正的CenterNet——Objects as Points论文解读
首发于深度学习那些事 已关注写文章 扔掉anchor!真正的CenterNet——Objects as Points论文解读 OLDPAN 不明觉厉的人工智障程序员 关注他 JustDoIT 等 ...
- NIPS2018最佳论文解读:Neural Ordinary Differential Equations
NIPS2018最佳论文解读:Neural Ordinary Differential Equations 雷锋网2019-01-10 23:32 雷锋网 AI 科技评论按,不久前,NeurI ...
- [论文解读] 阿里DIEN整体代码结构
[论文解读] 阿里DIEN整体代码结构 目录 [论文解读] 阿里DIEN整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x04 模型基类 4.1 基本逻辑 ...
- 【抓取】6-DOF GraspNet 论文解读
[抓取]6-DOF GraspNet 论文解读 [注]:本文地址:[抓取]6-DOF GraspNet 论文解读 若转载请于明显处标明出处. 前言 这篇关于生成抓取姿态的论文出自英伟达.我在读完该篇论 ...
随机推荐
- Error in nextTick: "TypeError: Right-hand side of 'instanceof' is not an object"
发生这种情况,直接去查看 props 对象是否 类型正确 props 有 大概两种 写法吧, 一种就是对象形 ,一种是数组形 // 对象形props: { show: { type: Boolean ...
- 近期SQL优化实战分享
分享一下本周SQL优化的两个场景. 如果能对读者有一定的启发,共同探讨,不胜荣幸. 版本信息:mysql,5.7.19 引擎: innodb 场景1 我们有一张常口表,里面的数据由各种数据源合并而来, ...
- Kubernetes 研究笔记
Kubernetes 研究笔记 在接下来的这篇笔记中,我将会介绍 Kubernetes 这一强大的容器编排工具,并学习其基本使用方法.该笔记将会被存储在https://github.com/owlma ...
- 更换Mysql数据库-----基于Abo.io 的书籍管理Web应用程序
之前公司一直使用的是ASP.NET Boilerplate (ABP),但是当解决方案变得很大时,项目启动就变得非常慢,虽然也想了一些办法,将一些基础模块做成Nuget包的形式,让整个解决方案去引用. ...
- 高级程序员和新手小白程序员区别你是那个等级看解决bug速度
IT入门深似海 ,程序员行业,我觉得是最难做的.加不完的班,熬不完的夜. 和产品经理,扯不清,理还乱的宿命关系 一直都在 新需求-做项目-解决问题-解决bug-新需求 好像一直都是这么一个循环.(哈哈 ...
- .netcore中的虚拟文件EmbeddedFile
以前一直比较好奇像swagger,cap,skywalking等组件是如何实现引用一个dll即可在网页上展示界面的,难道这么多html,js,css等都是硬编码写死在代码文件中的?后面接触apb里面也 ...
- python 爬虫某东网商品信息 | 没想到销量最高的是
哈喽大家好,我是咸鱼 好久没更新 python 爬虫相关的文章了,今天我们使用 selenium 模块来简单写个爬虫程序--爬取某东网商品信息 网址链接:https://www.jd.com/ 完整源 ...
- @FunctionalInterface注解的使用
被@FunctionalInterface注解标记的类型表明这是一个函数接口.从概念上讲,函数接口只有一个抽象方法.如果接口声明的抽象方法覆写Object类的公共方法,那这方法不算作接口的抽象方法,因 ...
- Vue项目学习
一.二维数组尝试 var vm = new Vue({ el: "#app", data: { huilv:[ [6.8540, 132.9787, 1298.7013, 1.32 ...
- 信创优选,国产开源,Solon v2.3.6 发布
Solon 是什么开源项目? 一个,Java 新的生态型应用开发框架.它从零开始构建,有自己的标准规范与开放生态(历时五年,已有全球第二级别的生态).与其他框架相比,它解决了两个重要的痛点:启动慢,费 ...