Hibench对大数据平台CDH/HDP基准性能测试
一、部署方式
1.1、源码/包:https://github.com/Intel-bigdata/HiBench
部署方法:
https://github.com/Intel-bigdata/HiBench/blob/master/docs/build-hibench.md
注意:hibench执行需hadoop客户端jar包环境
如何使用HiBench进行基准测试说明:
https://cloud.tencent.com/developer/article/1158310
二、目录/文件简介

主要介绍下bin执行文件目录和conf配置文件目录。
·2.1配置文件目录--conf

benchmarks.lst 配置需测试项
frameworks.lst 配置测试hadoop或spark
hibench.conf 配置数据量级别及文件数等
hadoop.conf hadoop home、master等配置项
spark.conf spark home、master、 Yarn运行核数、内存等配置项
workloads目录 存放各种具体测试项配置文件
·2.2配置文件说明
|
文件名 |
主要用途 |
|
benchmarks.lst |
主要用于配置benchmarks的模块 |
|
flink.conf.template |
Flink测试的配置参数 |
|
frameworks.lst |
主要用于配置HiBench支持的测试框架 |
|
gearpump.conf.template |
gearpump测试相关配置文件 |
|
hadoop.conf.template |
Hadoop测试相关配置文件 |
|
hibench.conf |
HiBench配置文件 |
|
spark.conf.template |
Spark配置文件 |
|
storm.conf.template |
Strom配置文件 |
·2.3配置文件说明
··2.3.1. benchmarks.lst配置文件
主要用于配置benchmarks列表,配置如下,可以对不需要测试的模块进行屏蔽或者删除,在需要屏蔽在前面加“#”如下:(适用于执行run_all.sh)
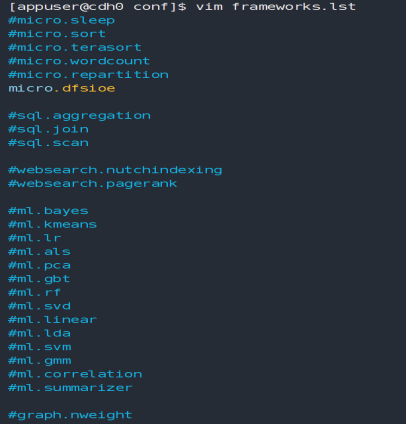
··2.3.2. hadoop.conf.template配置文件
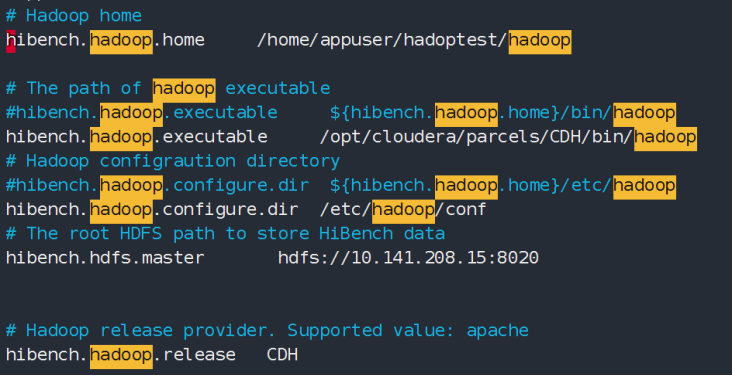
该配置文件主要用于配置Hadoop的环境,如果需要对Hadoop做benchmark测试则需要将该文件重命名为hadoop.conf。
编辑hadoop.conf文件,配置Hadoop环境,此处以CDH的目录配置为例,配置如下:
··2.3.3. spark.conf.template配置文件
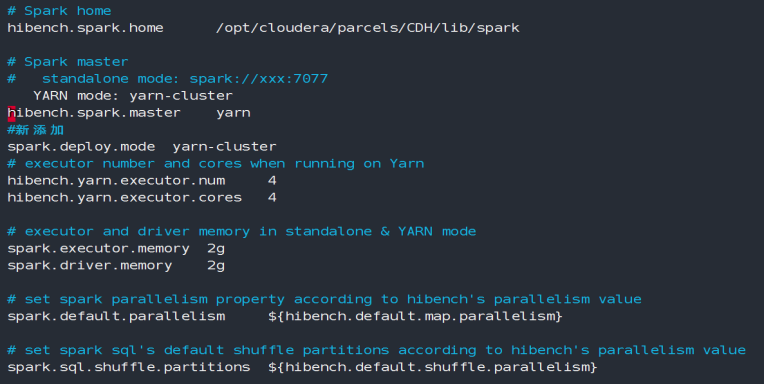
主要用于配置Spark的环境及运行参数,如果需要测试Saprk框架则需要将该配置文件重命名为spark.conf。
编辑spark.conf文件,配置Spark的环境,此处以CDH的目录配置为例,配置如下:根据集群环境调整相应参数。
··2.3.4. hibench.conf配置文件
主要配置HiBench的运行参数及HiBench各个模块的home环境配置,根据需要修改相应的配置参数:
主要关注参数hibench.scale.profile、hibench.default.map.parallelism和hibench.default.shuffle.parallelism配置:
hibench.scale.profile:主要配置HiBench测试的数据规模;
hibench.default.map.parallelism:主要配置MapReduce的Mapper数量;
hibench.default.shuffle.parallelism:配置Reduce数量;
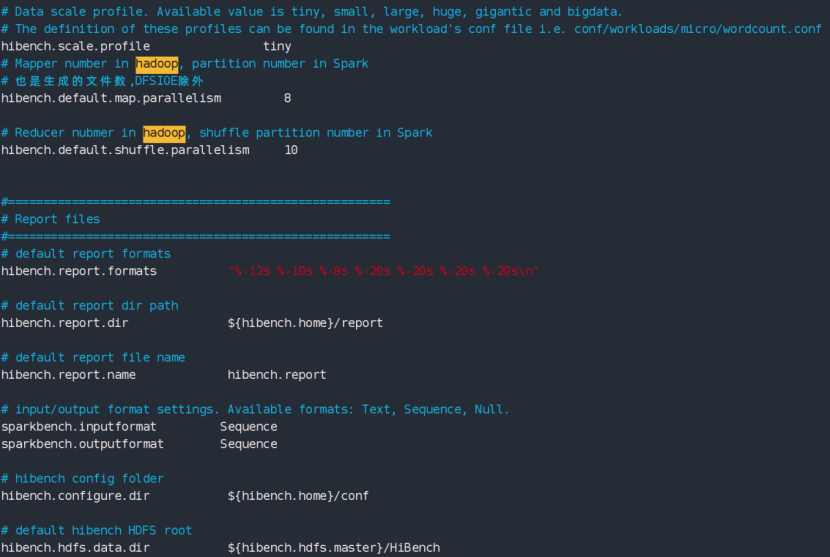
注意:
# 也是生成的文件数,DFSIOE除外
例如 hibench.default.map.parallelism 10
wordcount.conf配置数据量为10000000字节(10M),10个文件,及每个文件为1M。
三、数据规模说明
HiBench的默认数据规模有:tiny, small, large, huge, gigantic andbigdata,在这几种数据规模之外Fayson还介绍如何自己指定数据量。
·3.1DFSIOE数据规模介绍及自定义
配置文件:${hibench.home}/conf/workloads/micro/dfsioe.conf
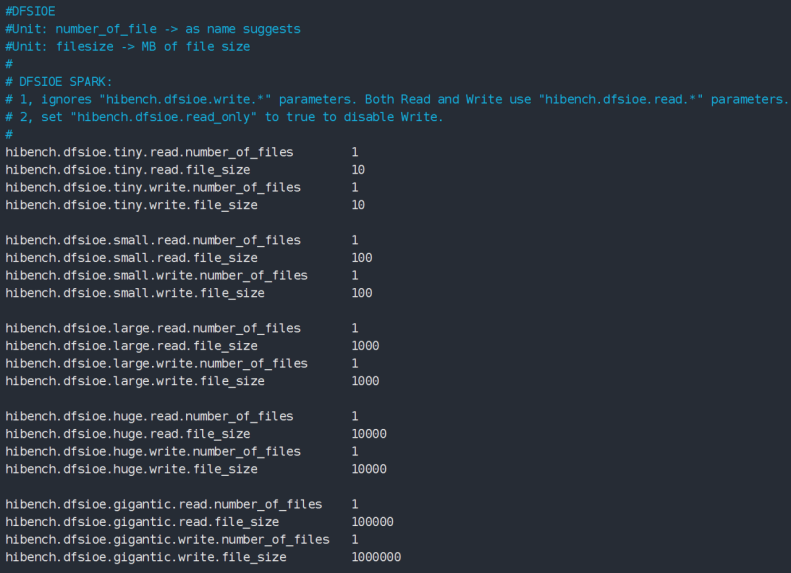
DFSIOE测试用例通过定义读或写的文件数和文件的大小来指定测试数据量的规模,如果需要自定义测试规模则修改文件数和文件的大小即可,文件大小以MB为单位。
例如:我需要自定义一个5TB数量级的DFSIOE测试,在hibench.conf文件中hibench.scale.profile配置的是mybigdata,需要在dfsioe.conf配置文件中增加读写文件数为5120,文件大小设置为1024,具体配置如下:
hibench.dfsioe.mybigdata.read.number_of_files 5120
hibench.dfsioe.mybigdata.read.file_size 1024
hibench.dfsioe.mybigdata.write.number_of_files 5120
hibench.dfsioe.mybigdata.write.file_size 1024
读写测试的数据量均为5TB = 5120 * 1024MB
·3.2举例配置单词统计测试项 数据量大小

进入/conf/workloads/micro目录下,修改wordcount.conf

注意:dfsioe单位:MB,terasort单位:kb,其他测试项单位为:字节。
四、执行文件目录--bin

方式一:
sh run_all.sh
通过在conf下文件配置好数据量及测试项,批量执行测试项测试,包含数据准备及运行。
方式二:
1、具体测试某一项,以单词统计举例,准备数据可进入
/bin/workloads/micro/wordcount/prepare/
执行prepare.sh
(可执行命令hadoop fs -du -h /Hibench/Wordcount 查看对应各个用例生成的测试数据及用例结果
删除测试数据:sudo -u hdfs hadoop fs -rm -r /Hibench/Wordcount)
2、运行测试,进入/bin/workloads/micro/wordcount/hadoop/ 执行run.sh

五、查看报告文件

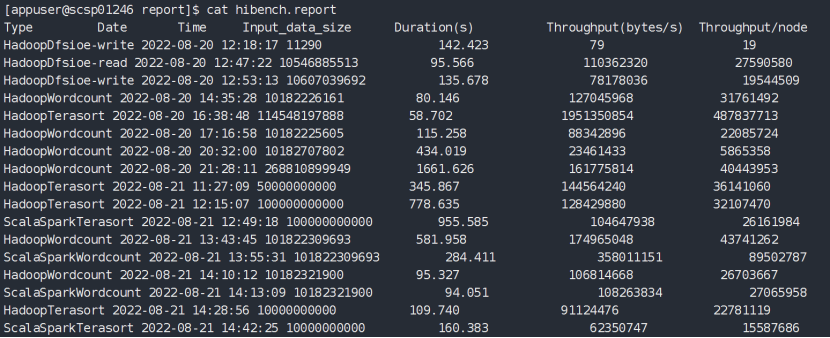
进入/report下,查看 hibench.report,其中包含类型、执行日期和时间,数据量,主要关注:持续时间,吞吐量/秒和吞吐量/节点。
Hibench对大数据平台CDH/HDP基准性能测试的更多相关文章
- 朝花夕拾之--大数据平台CDH集群离线搭建
body { border: 1px solid #ddd; outline: 1300px solid #fff; margin: 16px auto; } body .markdown-body ...
- 大数据 -- Cloudera Manager(简称CM)+CDH构建大数据平台
一.Cloudera Manager介绍 Cloudera Manager(简称CM)是Cloudera公司开发的一款大数据集群安装部署利器,这款利器具有集群自动化安装.中心化管理.集群监控.报警等功 ...
- HDP 企业级大数据平台
一 前言 阅读本文前需要掌握的知识: Linux基本原理和命令 Hadoop生态系统(包括HDFS,Spark的原理和安装命令) 由于Hadoop生态系统组件众多,导致大数据平台多节点的部署,监控极其 ...
- CM记录-CDH大数据平台实施经验总结2016(转载)
CDH大数据平台实施经验总结2016(转载) 2016年负责实施了一个生产环境的大数据平台,用的CDH平台+docker容器的方式,过了快半年了,现在把总结发出来. 1. 平台规划注意事项 1.1 业 ...
- product of大数据平台搭建------CM 和CDH安装
一.安装说明 CM是由cloudera公司提供的大数据组件自动部署和监控管理工具,相应的和CDH是cloudera公司在开源的hadoop社区版的基础上做了商业化的封装的大数据平台. 采用离线安装模式 ...
- CDH构建大数据平台-使用自建的镜像地址安装Cloudera Manager
CDH构建大数据平台-使用自建的镜像地址安装Cloudera Manager 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搭建CM私有仓库 详情请参考我的笔记: http ...
- CDH 大数据平台搭建
一.概述 Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”),基于Web的用户界面,支持大多数Hadoop组件,包括 ...
- HDP 大数据平台搭建
一.概述 Apache Ambari是一个基于Web的支持Apache Hadoop集群的供应.管理和监控的开源工具,Ambari已支持大多数Hadoop组件,包括HDFS.MapReduce.Hiv ...
- CDH构建大数据平台-配置集群的Kerberos认证安全
CDH构建大数据平台-配置集群的Kerberos认证安全 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 当平台用户使用量少的时候我们可能不会在一集群安全功能的缺失,因为用户少,团 ...
- CDH构建大数据平台-Kerberos高可用部署【完结篇】
CDH构建大数据平台-Kerberos高可用部署[完结篇] 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.安装Kerberos相关的软件包并同步配置文件 1>.实验环境 ...
随机推荐
- C++子类的构造函数
子类的构造函数 子类可以有自己的构造函数 子类没有构造函数,默认系统会调用父类的构造函数 子类有自己的构造函数,系统会先运行父类的构造函数,随后运行子类的构造函数,对子类对象进行覆盖和拓展 即不论子类 ...
- Go命令
build: 编译包和依赖 clean: 移除对象文件 doc: 显示包或者符号的文档 env: 打印go的环境信息 bug: 启动错误报告 fix: 运行go tool fix fmt: 运行gof ...
- 你可得知道物理地址与IP地址
来看看计算机网络中这些常见的概念你有没有理解~ 物理地址 表示方式 物理地址即mac地址,每个网卡都有6字节的唯一标识,前三个字节表示厂商,后三个字节由厂商随机分配. 如何查看 在 command 中 ...
- 一篇博客带你上手Git
概述 安装Git 下载官方网站,下载后安装包样式:双击安装,安装成功后右键文件会有如下选项证明安装成功. 基本配置 设置用户信息,桌面右键,选择Git bash here hecheng@LAPTOP ...
- Nginx 文件名逻辑漏洞(CVE-2013-4547)(Vulhub)
Nginx 文件名逻辑漏洞(CVE-2013-4547)(Vulhub) 漏洞简介 在Nginx 0.8.41 ~ 1.4.3 / 1.5.0 ~ 1.5.7版本中存在错误解析用户请求的url信息,从 ...
- P3378 【模板】二叉堆
[洛谷]P3378 [模板]堆 方法一 手写堆 最小堆插入 从新增的最后一个结点的父结点开始,用要插入元素向下过滤上层结点(相当于要插入的元素向上渗透) void siftdown(int i) // ...
- 《Python魔法大冒险》009 魔法之语:字符串的奥秘
随着小鱼和魔法师的深入,他们来到了一个被薄雾笼罩的湖泊.湖中央有一个小岛,岛上有一棵巨大的古树,树上挂满了闪闪发光的果实,每一个果实上都刻着一个字母或符号. 小鱼好奇地问:"这些是什么果实? ...
- 关闭k8s的pod时减小对服务的影响
在应用程序的整个生命周期中,正在运行的 pod 会由于多种原因而终止.在某些情况下,Kubernetes 会因用户输入(例如更新或删除 Deployment 时)而终止 pod.在其他情况下,Kube ...
- 使用极速全景图下载大师下载720yun全景图片(一键下载建E、720云全景原图)
VR全景图片下载 软件简介 极速全景图下载大师下载地址: 点击进入下载页面 极速全景图下载大师(VR全景图下载器)软件官网: 点击进入官网 极速全景图下载大师如何下载720yun全景图片 1.首先,在 ...
- 升讯威在线客服系统的并发高性能数据处理技术:PLINQ并行查询技术
我在业余时间开发维护了一款免费开源的升讯威在线客服系统,也收获了许多用户.对我来说,只要能获得用户的认可,就是我最大的动力. 最近客服系统成功经受住了客户现场组织的压力测试,获得了客户的认可. 客户组 ...